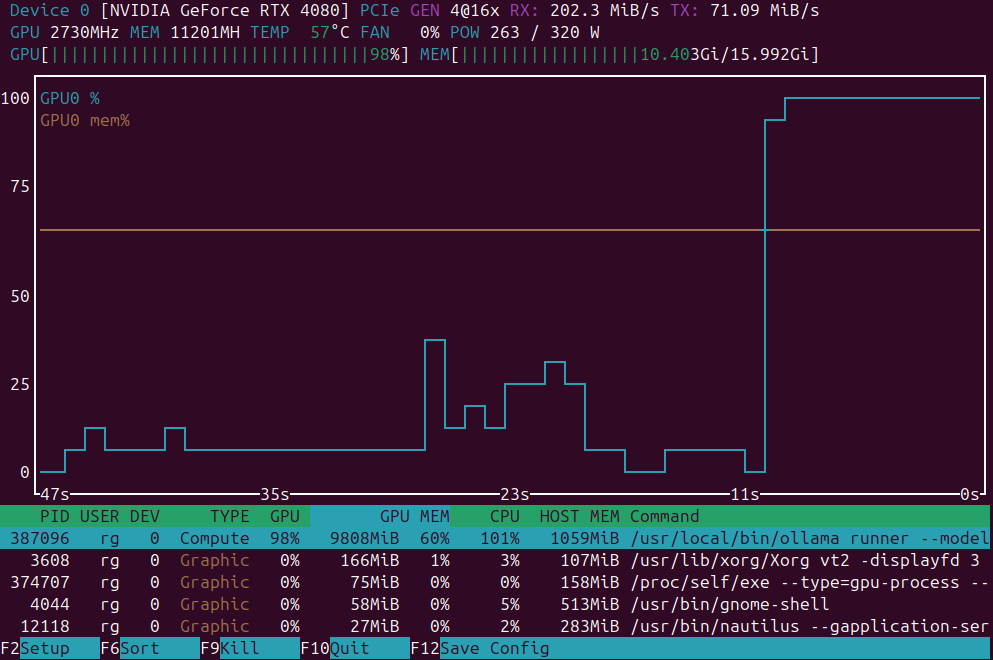
Dodanie obsługi GPU firmy NVIDIA do Docker Model Runner
Włącz przyspieszenie GPU dla Docker Model Runner z obsługą NVIDIA CUDA
Docker Model Runner to oficjalne narzędzie firmy Docker do uruchamiania modeli AI lokalnie, ale włączanie przyspieszenia GPU od firmy NVidia w Docker Model Runner wymaga konkretnej konfiguracji.