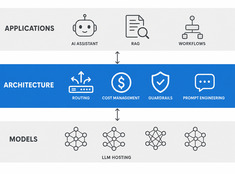
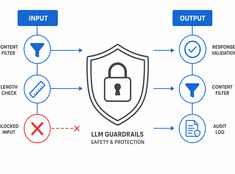
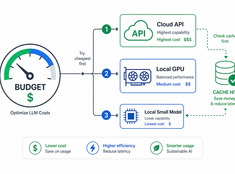
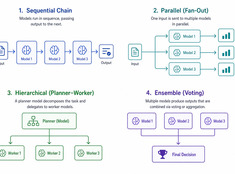
Czym jest Spec-Driven Development? Specyfikacja jako źródło prawdy
Specyfikacja jako źródło prawdy, a nie dokument dodatkowy.
Rozwój napędzany specyfikacjami (Spec-Driven Development) to jedna z tych idei, do których programiści sięgali wcześniej, a następnie odkładali na bok, gdy wysiłki przestawały przynosić wymierne korzyści.