

Google A2A-Protokoll 2026: Adoption, Hype und Realität
A2A ist nicht tot. Es ist nur nicht universell.
Googles Agent2Agent-Protokoll, meist abgekürzt als A2A, hatte ein seltsames erstes Jahr.
A2A ist nicht tot. Es ist nur nicht universell.
Googles Agent2Agent-Protokoll, meist abgekürzt als A2A, hatte ein seltsames erstes Jahr.

Zuverlässige Polling-Muster für KI-Agenten.
Polling-Agenten gehören zu den wenig glamourösen Teilen der Architektur von KI-Assistenten, sind aber gleichzeitig auch eine der nützlichsten Komponenten.

A2A macht Agents zu Netzwerkpeers.
Das A2A-Protokoll, kurz für Agent2Agent Protocol, ist ein offener Standard für die Kommunikation zwischen unabhängigen KI-Agent-Systemen.

MCP gibt Agenten Werkzeuge. A2A gibt Agenten Kollegen.
Die Architektur von KI-Agenten beginnt sich in zwei Schichten aufzuspalten.

CQRS in Go implementieren, ohne unnötigen Ballast
CQRS ist eines dieser Patterns, das überbeworben, überkompliziert und gelegentlich fälschlicherweise als Heilmittel gegen die langweilige CRUD-Alltagsarbeit dargestellt wird.
Diagrams as Code, ohne den Stress.
Mermaid ist ein textbasiertes Diagrammwerkzeug für Menschen, die Diagramme lieber schreiben, als Kästchen auf einer Leinwand zu verschieben. Es verwendet eine Markdown-ähnliche Syntax, um Flussdiagramme, Sequenzdiagramme, Klassendiagramme, Zustandsautomaten, Zeitachsen, Gantt-Diagramme, Entity-Relationship-Diagramme und mehr zu beschreiben.

Organisieren Sie Notizen nach Aktionen, nicht nach Themen.
Die Organisation von Notizen nach Themen klingt logisch, bis man Notizen zu PostgreSQL in fünf verschiedenen Ordnern hat und diejenige, die für das aktuelle Problem relevant ist, nicht findet.

Notizen, die sich verbessern, anstatt zu veralten.
Die meisten Engineering-Notizen werden einmal geschrieben und dann vergessen. Man fasst etwas während einer Debugging-Sitzung zusammen, kopiert es irgendwohin und findet es zwei Jahre später, ohne Kontext dafür zu haben, warum es damals wichtig war.

Verbreiten Sie wachsendes Wissen, nicht nur Beiträge.
Das vorherrschende Modell zur Veröffentlichung von Wissen im Internet hat sich seit den frühen 2000er Jahren kaum verändert: Etwas schreiben, polieren, veröffentlichen und dann weiterziehen.
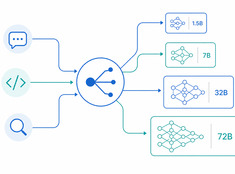
Das richtige Modell für die richtige Aufgabe.
Das Ausführen eines Modells mit 70 Milliarden Parametern, um eine 200-Wörter-E-Mail zusammenzufassen, ist verschwenderisch. Das Ausführen eines 3-Milliarden-Parameter-Modells zur Überprüfung von Produktionscode ist fahrlässig. Die meisten Systeme liegen irgendwo dazwischen – und genau hier kommt das Modell-Routing ins Spiel.
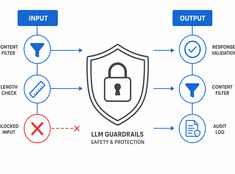
Steuern Sie das Risiko, nicht nur das Modell.
LLMs sind unvorhersehbar. Sie halluzinieren, geben Daten preis, generieren schädliche Inhalte oder lehnen legitime Anfragen ab. Guardrails (Sicherheitsvorkehrungen) beschränken das Modellverhalten, ohne dabei die Fähigkeiten zu beeinträchtigen.
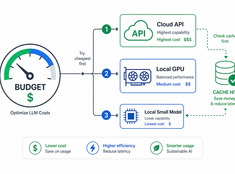
Verwende Tokens dort, wo es wirklich zählt.
Die Kosten für LLMs steigen linear mit der Nutzung. Ein System, das täglich 10.000 Anfragen mit $0,01 pro Anfrage verarbeitet, kostet täglich $100 — also $365 pro Jahr. Im Unternehmensmaßstab belaufen sich die Kosten auf über $10.000.
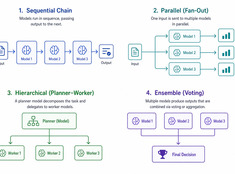
Wählen Sie das einfachste Muster, das funktioniert.
Einzige-Modell-Systeme sind einfach. Multi-Modell-Systeme sind leistungsstark. Die Herausforderung besteht nicht darin, Modelle auszuwählen, sondern die Architektur zu entwerfen, die sie orchestriert.

Arbeits-, Struktur- und Abrufgedächtnis für Assistenten.
Speicher verwandelt Assistenten von reaktiv in persistent, ist aber auch der Ort, an dem viele Systeme stillschweigend veralten. Umfragen argumentieren, dass die Trennung zwischen kurzfristigem und langfristigem Speicher für moderne Agenten-Speicher nicht mehr ausreicht; OpenAI- und LangGraph-SDKs weisen auf einen einfacheren Stack hin – Arbeitsgedächtnis, dauerhafter Zustand und Abruf.

Wie ernsthafte Assistenten tatsächlich aufgebaut sind.
Ein produktionsreifes KI-Assistentensystem ist nicht einfach „ein LLM mit einem Prompt“. Es ist ein System, das Absichten akzeptiert, Zustände verwaltet, entscheidet, wann es Informationen abrufen oder Aktionen ausführen soll, und genügend Laufzeitdetails offenlegt, um Fehler zu debuggen.

KI verändert das Wissensmanagement, nicht seinen Zweck.
KI ersetzt nicht das Wissensmanagement; sie verändert dessen Gestalt für Einzelpersonen und Teams gleichermaßen.
Neue Beiträge zu Systemen, Infrastruktur und KI-Engineering.