

Protokół Google A2A w 2026 roku: adopcja, hype i rzeczywistość
A2A nie jest martwy. Po prostu nie jest uniwersalny.
Protokół Agent2Agent od Google, zwykle skracany do A2A, miał dziwne pierwsze rok.
A2A nie jest martwy. Po prostu nie jest uniwersalny.
Protokół Agent2Agent od Google, zwykle skracany do A2A, miał dziwne pierwsze rok.

Niezawodne wzorce oparte na pytaniu o status dla agentów AI.
Agentów sondujących (polling agents) należy uznać za jedną z najmniej glamour, ale zarazem najbardziej użytecznych części architektury asystentów AI.

MCP dostarcza agentom narzędzia. A2A dostarcza agentom równe sobie podmioty.
Architektura agentów AI zaczyna dzielić się na dwie warstwy.

A2A przekształca agentów w równorzędne węzły sieciowe.
Protokół A2A, skrótem od Agent2Agent Protocol, to otwarty standard komunikacji między niezależnymi systemami agentów AI.
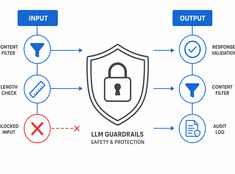
Kontroluj ryzyko, nie tylko model.
Modele językowe LLM są nieprzewidywalne. Halucynują, ujawniają dane, generują szkodliwe treści lub odmawiają spełnienia legalnych zapytań. Mechanizmy ochronne (guardrails) ograniczają zachowanie modelu, nie kosztem jego możliwości.
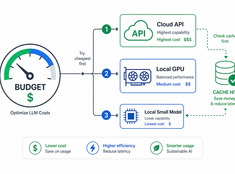
Inwestuj tokeny tam, gdzie naprawdę się liczą.
Koszty LLM rosną liniowo wraz z użyciem. System przetwarzający 10 000 zapytań dziennie po cenie 0,01 USD za zapytanie kosztuje 100 USD dziennie — czyli 365 USD rocznie. W skali przedsiębiorczej to ponad 10 000 USD.
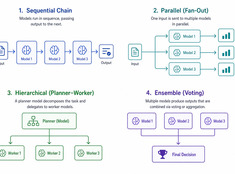
Wybierz najprostszy działający wzorzec.
Systemy oparte na jednym modelu są proste. Systemy wielomodelowe są potężne. Wyzwanie nie polega na wyborze modeli – chodzi o zaprojektowanie architektury, która je koordynuje.
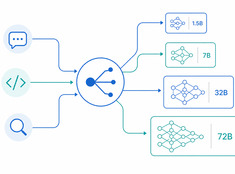
Odpowiedni model dla odpowiedniego zadania.
Uruchamianie modelu o 70 miliardach parametrów w celu podsumowania 200-znakowego e-maila jest marnotrawstwem. Zastosowanie modelu o 3 miliardach parametrów do recenzji kodu produkcyjnego jest bezmyślną ryzykownością. Większość systemów funkcjonuje gdzieś w tym spektrum – i tutaj z pomocą przychodzi routing modeli.

Pamięć robocza, strukturalna i odzyskiwania dla asystentów.
Pamięć przekształca asystentów z reaktywnych w trwałych, ale to również miejsce, w którym wiele systemów cicho się psuje. Ankiety wskazują, że podział na pamięć krótko- i długoterminową nie jest już wystarczający dla współczesnej pamięci agentów; OpenAI i SDK LangGraph wskazują na prostszą architekturę — pamięć roboczą, trwały stan i mechanizmy odzyskiwania danych.

Jak naprawdę są budowane poważne asystenci.
Produkcjony asystent AI to nie „model LLM z promptem”. To system, który akceptuje intencję użytkownika, utrzymuje stan, decyduje, kiedy pobrać dane lub wykonać akcję, oraz udostępnia wystarczająco szczegółowe informacje o czasie działania, aby debugować awarie.

AI zmienia zarządzanie wiedzą, nie jej cel.
AI nie zastępuje zarządzania wiedzą; zmienia jej kształt zarówno dla osób indywidualnych, jak i zespołów.
Gwiazdki, tokeny, pobrania — kto naprawdę wygrywa?
Otwartoźródłowe frameworki agentów AI zyskują na popularności na GitHubie w tempie wybuchowym. Dwa projekty lyingce w centrum ekosystemu samodzielnie hostowanych systemów AI — OpenClaw i Hermes Agent — wyprzedziły resztę pola tak daleko, że pozostali uczestnicy rywalizują o odległe trzecie miejsce.

MTP w porównaniu do standardowego dekodowania na RTX 4080 — rzeczywiste benchmarki
Przetestowałem wydajność spekulacyjnego dekodowania (Wieloznakowego Przewidywania, MTP) w modelach Qwen 3.6 27B i 35B na karcie RTX 4080 z 16 GB pamięci VRAM.

Darmowa pamięć VRAM bez zabijania llama-server.
Tryb routera w llama.cpp to jedna z najbardziej przydatnych zmian wprowadzonych do llama-server w ciągu ostatnich lat. Wreszcie daje lokalnym operatorom modeli LLM coś w rodzaju zarządzania modelami, do którego są przyzwyczajeni z Ollama, jednocześnie zachowując surową wydajność i kontrolę na niskim poziomie, która sprawia, że warto korzystać z llama.cpp w pierwszej kolejności.

Złożona wiedza dla systemów AI
Premisa jest prosta: skompilowana wiedza jest bardziej ponownie wykorzystywalna niż pobrane fragmenty. RAG stał się domyślną odpowiedzią na proste pytanie – jak zapewnić LLM dostęp do zewnętrznej wiedzy?