

Design av moderna varningssystem för observabilitetsteam
Varningshantering är ett responsystem, inte ett larmsystem.
Alerting beskrivs för ofta som en övervakningsfunktion. Den ramverket är bekvämt, men det döljer det verkliga problemet.
Varningshantering är ett responsystem, inte ett larmsystem.
Alerting beskrivs för ofta som en övervakningsfunktion. Den ramverket är bekvämt, men det döljer det verkliga problemet.

Hur man installerar, konfigurerar och använder OpenCode
Jag återkommer gång på gång till llama.cpp för lokal inferens – det ger dig kontroll som Ollama och andra abstraherar bort, och det fungerar bara enkelt. Det är lätt att köra GGUF-modeller interaktivt med llama-cli eller exponera ett OpenAI-kompatibelt HTTP-API med llama-server.

Övervaka LLM med Prometheus och Grafana
LLM-inferens ser ut som “en API till” – fram till dess att latens toppar, köer backar upp och dina GPU:er sitter på 95 % minnesanvändning utan någon uppenbar förklaring.

En strategi för helhetsövervakning av LLM-inferens och LLM-applikationer
LLM-system (storspråkmodeller) misslyckas på sätt som traditionell API-övervakning inte kan upptäcka — köer fylls tyst, GPU-minne mättas långt innan CPU ser ut att vara upptagen, och latens ökar explosionsartat vid batchlageret snarare än vid applikationslagret.

Mätningar, instrumentpaneler, loggar och varningar för produktionssystem – Prometheus, Grafana, Kubernetes och AI-belasta.
Observabilitet är grunden för pålitliga produktionsystem.
Utan metrik, dashboard och varningar drar Kubernetes-kluster, AI-arbetslaster misslyckas tyst och latensregressioner går oobserverade tills användare klagar.

Sätt upp robust infrastrukturövervakning med Prometheus
Prometheus har blivit standarden för övervakning av molnbaserade applikationer och infrastruktur, och erbjuder insamling av mätvärden, frågefunktioner och integration med visualiseringsverktyg.
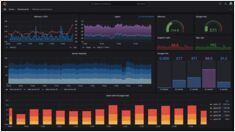
Mästare Grafana-inställningar för övervakning och visualisering
Grafana är den ledande öppna källkodsplattformen för övervakning och observabilitet, som omvandlar mätvärden, loggar och spårningar till åtgärdbara insikter genom imponerande visualiseringar.