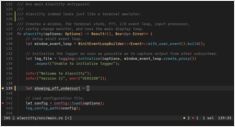
Qwen 3.6 27B en 35B MTP versus standaard op een 16 GB GPU
MTP versus standaard decoding op de RTX 4080 — echte benchmarks
Ik heb de prestaties van speculatief decoderen (Multi-Token Prediction, MTP) getest in Qwen 3.6 27B en 35B op een RTX 4080 met 16 GB VRAM.