

2026년 구글 A2A 프로토콜: 채택 현황, 과열, 그리고 현실
A2A가 죽은 것은 아닙니다. 그저 범용적이지 않을 뿐입니다.
구글의 에이전트 간 상호 작용 프로토콜인 A2A(Agent2Agent)는 첫 해를 다소 혼란스럽게 보냈습니다.
A2A가 죽은 것은 아닙니다. 그저 범용적이지 않을 뿐입니다.
구글의 에이전트 간 상호 작용 프로토콜인 A2A(Agent2Agent)는 첫 해를 다소 혼란스럽게 보냈습니다.

AI 에이전트의 신뢰할 수 있는 폴링 패턴
폴링 에이전트(Polling Agent)는 AI 어시스턴트 아키텍처에서 가장 화려하지는 않은 부분 중 하나이지만, 동시에 가장 유용한 부분 중 하나이기도 합니다.

A2A는 에이전트를 네트워크 피어(peer)로 전환합니다.
A2A 프로토콜(에이전트 투 에이전트 프로토콜의 약자)은 독립된 AI 에이전트 시스템 간 통신을 위한 개방형 표준입니다.

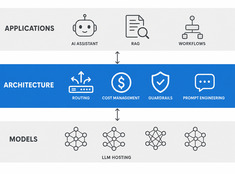
MCP는 에이전트에 도구를 제공하고, A2A는 에이전트에 동료(피어)를 제공합니다.
AI 에이전트 아키텍처가 두 개의 레이어로 분화되기 시작하고 있습니다.
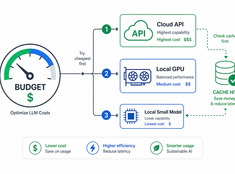
중요한 곳에 토큰을 투자하세요.
LLM(대형 언어 모델) 비용은 사용량에 따라 선형적으로 증가합니다. 하루에 1,000개의 요청을 처리하고 요청당 비용이 $0.01인 시스템의 경우, 일일 비용은 $100이며 연간 비용은 $365입니다. 기업 규모에서는 이 비용이 $10,000을 넘을 수 있습니다.
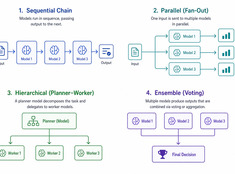
작동하는 가장 단순한 패턴을 선택하라.
단일 모델 시스템은 단순합니다. 다중 모델 시스템은 강력합니다. 여기서 핵심 과제는 모델을 선택하는 것이 아니라, 이러한 모델들을 조율하는 아키텍처를 설계하는 것입니다.
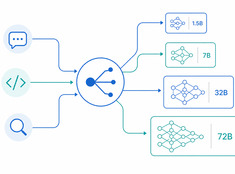
적절한 작업에 적합한 모델
200단어짜리 이메일을 요약하기 위해 700억 파라미터 모델 실행은 낭비입니다. 프로덕션 코드를 검토하기 위해 30억 파라미터 모델을 실행하는 것은 무모합니다. 대부분의 시스템은 이 두 극단 사이의 어딘가에 위치해 있으며, 바로 여기서 모델 라우팅(Model Routing)의 역할이 시작됩니다.
모델이 아닌 위험을 관리하십시오.
LLM은 예측 불가능합니다. 할루시네이션(환각)을 일으키거나, 데이터를 유출하거나, 해로운 콘텐츠를 생성하거나, 정당한 요청을 거부하기도 합니다. 가드레일(Guardrails)은 모델의 기능을 희생하지 않으면서도 모델의 행동을 제한합니다.

에이전트의 작업 기억, 구조화 기억 및 검색 기억
메모리는 어시스턴트를 반응형에서 지속형으로 전환시키지만, 동시에 많은 시스템이 조용히 부패하는 곳이기도 합니다. 설문 조사들은 단기적 대 장기적 이분법이 현대 에이전트 메모리에는 더 이상 충분하지 않다고 주장하며, OpenAI와 LangGraph SDK들은 작동 메모리(working memory), 내구 상태(durable state), 검색(retrieval)이라는 더 단순한 스택을 지향합니다.

진정한 어시스턴트가 어떻게 구축되는지
생산 환경용 AI 어시스턴트는 단순히 “프롬프트가 붙은 LLM"이 아닙니다. 사용자 의도를 수용하고, 상태를 유지하며, 언제 검색하거나 행동할지 결정하며, 실패를 디버깅할 수 있는 충분한 런타임 세부 정보를 노출하는 시스템입니다.

AI는 지식 관리의 목적을 바꾸는 것이 아니라, 지식 관리 방식을 변화시킵니다.
AI는 지식 관리를 대체하지 않습니다. 대신 개인과 팀 모두에게 지식 관리의 형태를 변화시키고 있습니다.
별, 토큰, 다운로드 — 진정한 승자는 누구인가?
GitHub에서 오픈소스 AI 에이전트 프레임워크의 인기가 폭발적으로 증가하고 있습니다. 자기 호스팅 AI 시스템 생태계의 핵심에 있는 두 프로젝트인 OpenClaw와 Hermes Agent는 압도적인 선두를 차지하여, 나머지 분야에서는 3위 자리를 놓고 치열한 경쟁이 벌어지고 있는 상황입니다.

RTX 4080에서의 MTP 대 표준 디코딩 — 실제 벤치마크
RTX 4080(16 GB VRAM) 환경에서 Qwen 3.6 27B 및 35B 모델의 추측 해독(Speculative decoding, 다중 토큰 예측(MTP)) 성능을 테스트했습니다.

llama-server를 종료하지 않고도 VRAM을 확보하는 방법
llama.cpp 라우터 모드는 수년 동안 llama-server에 도입된 변화 중 가장 유용한 변화 중 하나입니다. 이는 로컬 LLM 운영자에게 Ollama에서 기대하는 모델 관리 경험에 가까운 기능을 제공하면서도, llama.cpp를 처음부터 사용하게 만드는 원시 성능과 저레벨 제어를 그대로 유지합니다.

AI 시스템을 위한 컴파일된 지식
전제는 간단합니다. 컴파일된 지식은 검색된 단편보다 재사용성이 높습니다. RAG는 직관적인 질문—LLM에게 외부 지식을 어떻게 접근하게 할 것인가?—에 대한 기본 답변이 되었습니다.