

AI Coding Assistants comparison
Cursor AI vs GitHub Copilot vs Cline AI vs...
Will list here some AI-assisted coding tools and AI Coding Assistants and their nice sides.
Cursor AI vs GitHub Copilot vs Cline AI vs...
Will list here some AI-assisted coding tools and AI Coding Assistants and their nice sides.

Ollama on Intel CPU Efficient vs Performance cores
I’ve got a theory to test - if utilising ALL cores on Intel CPU would raise the speed of LLMs? This is bugging me that new gemma3 27 bit model (gemma3:27b, 17GB on ollama) is not fitting into 16GB VRAM of my GPU, and partially running on CPU.

Understand Ollama concurrency, queueing, and how to tune OLLAMA_NUM_PARALLEL for stable parallel requests.
This guide explains how Ollama handles parallel requests (concurrency, queuing, and resource limits), and how to tune it using the OLLAMA_NUM_PARALLEL environment variable (and related knobs).

Comparing two deepseek-r1 models to two base ones
DeepSeek’s first-generation of reasoning models with comparable performance to OpenAI-o1, including six dense models distilled from DeepSeek-R1 based on Llama and Qwen.

Updated Ollama command list - ls, ps, run, serve, etc
This Ollama CLI cheatsheet focuses on the commands you use every day (ollama ls, ollama serve, ollama run, ollama ps, model management, and common workflows), with examples you can copy/paste.

Next round of LLM tests
Not long ago was released. Let’s catch up and test how Mistral Small performs comparing to other LLMs.

A python code of RAG's reranking

So many models with billions of parameters..
Testing how Perplexica performs with various LLMs running on local Ollama: Llama3, Llama3.1, Hermes 3, Mistral Nemo, Mistral Large, Gemma 2, Qwen2, Phi 3 and Command-r of various quants and selecting The best LLM for Perplexica

Comparing two self-hosted AI search engines
Awesome food is the pleasure for your eyes too. But in this post we will compare two AI-based search systems, Farfalle and Perplexica.
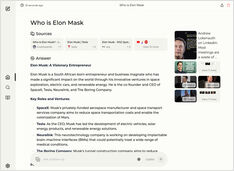
Running copilot-style service locally? Easy!
That’s very exciting! Instead of calling copilot or perplexity.ai and telling all the world what you are after, you can now host similar service on your own PC or laptop!

Testing logical fallacy detection
Recently we have seen several new LLMs were released. Exciting times. Let’s test and see how they perform when detecting logical fallacies.
Not so many to choose from but still....
When I started experimenting with LLMs the UIs for them were in active development and now some of them are really good.

Requires some experimenting but
Still there are some common approaches how to write good prompts so LLM would not get confused trying to understand what you wand from it.

8 llama3 (Meta+) and 5 phi3 (Microsoft) LLM versions
Testing how models with different number of parameters and quantization are behaving.

Ollama LLM model files take a lot of space
After installing ollama better to reconfigure ollama to store them in new place right away. So after we pull a new model, it doesn’t get downloaded to the old location.