
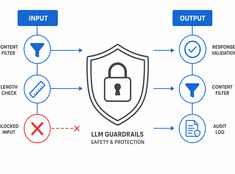
LLM-ограничения на практике: что действительно работает
«Контролируйте риски, а не только модель».
Большие языковые модели (LLM) непредсказуемы. Они галлюцинируют, утекают данными, генерируют вредоносный контент или отказывают в выполнению легитимных запросов. Ограничительные механизмы (guardrails) constraining поведение модели, не жертвуя при этом ее возможностями.