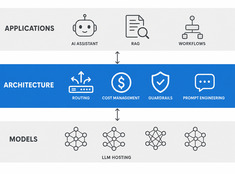
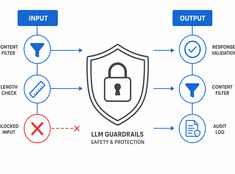
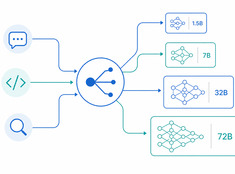
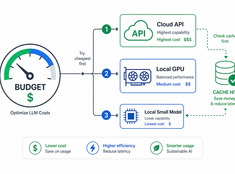
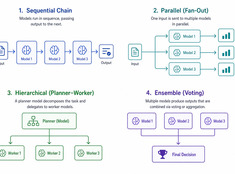
Спекулятивное декодирование: ускорение вывода LLM на 20–50%
Ускоренный инференс LLM без потери качества — практическое руководство
Модель объемом 70 миллиардов параметров генерирует один токен за один прямой проход, и при каждом проходе веса перезагружаются из видеопамяти (VRAM), вычисляется внимание (attention) по всему контексту и синхронизируется память. Между токенами GPU простаивает, ожидая разрешения последовательных зависимостей.