
vLLM Quickstart: High-Performance LLM Serving - in 2026
Fast LLM inference with OpenAI API
vLLM is a high-throughput, memory-efficient inference and serving engine for Large Language Models (LLMs) developed by UC Berkeley’s Sky Computing Lab.
Fast LLM inference with OpenAI API
vLLM is a high-throughput, memory-efficient inference and serving engine for Large Language Models (LLMs) developed by UC Berkeley’s Sky Computing Lab.

Real AUD pricing from Aussie retailers now
The NVIDIA DGX Spark (GB10 Grace Blackwell) is now available in Australia at major PC retailers with local stock. If you’ve been following the global DGX Spark pricing and availability, you’ll be interested to know that Australian pricing ranges from $6,249 to $7,999 AUD depending on storage configuration and retailer.

Technical guide to AI-generated content detection
The proliferation of AI-generated content has created a new challenge: distinguishing genuine human writing from “AI slop” - low-quality, mass-produced synthetic text.

Testing Cognee with local LLMs - real results
Cognee is a Python framework for building knowledge graphs from documents using LLMs. But does it work with self-hosted models?

Type-safe LLM outputs with BAML and Instructor
When working with Large Language Models in production, getting structured, type-safe outputs is critical. Two popular frameworks - BAML and Instructor - take different approaches to solving this problem.

Thoughts on LLMs for self-hosted Cognee
Choosing the Best LLM for Cognee demands balancing graph-building quality, hallucination rates, and hardware constraints. Cognee excels with larger, low-hallucination models (32B+) via Ollama but mid-size options work for lighter setups.

Build AI search agents with Python and Ollama
Ollama’s Python library now includes native OLlama web search capabilities. With just a few lines of code, you can augment your local LLMs with real-time information from the web, reducing hallucinations and improving accuracy.

Pick the right vector DB for your RAG stack
Choosing the right vector store can make or break your RAG application’s performance, cost, and scalability. This comprehensive comparison covers the most popular options in 2024-2025.

Build AI search agents with Go and Ollama
Ollama’s Web Search API lets you augment local LLMs with real-time web information. This guide shows you how to implement web search capabilities in Go, from simple API calls to full-featured search agents.

Compare the best local LLM hosting tools in 2026. API maturity, hardware support, tool calling, and real-world use cases.
Running LLMs locally is now practical for developers, startups, and even enterprise teams.
But choosing the right tool — Ollama, vLLM, LM Studio, LocalAI or others — depends on your goals:

Build robust AI/ML pipelines with Go microservices
As AI and ML workloads become increasingly complex, the need for robust orchestration systems has become greater. Go’s simplicity, performance, and concurrency makes it an ideal choice for building the orchestration layer of ML pipelines, even when the models themselves are written in Python.
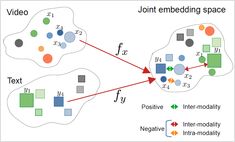
Unify text, images, and audio in shared embedding spaces
Cross-modal embeddings represent a breakthrough in artificial intelligence, enabling understanding and reasoning across different data types within a unified representation space.

Deploy enterprise AI on budget hardware with open models
The democratization of AI is here. With open-source LLMs like Llama 3, Mixtral, and Qwen now rivaling proprietary models, teams can build powerful AI infrastructure using consumer hardware - slashing costs while maintaining complete control over data privacy and deployment.

LongRAG, Self-RAG, GraphRAG - Next-gen techniques
Retrieval-Augmented Generation (RAG) has evolved far beyond simple vector similarity search. LongRAG, Self-RAG, and GraphRAG represent the cutting edge of these capabilities.

Speed-up FLUX.1-dev with GGUF quantization
FLUX.1-dev is a powerful text-to-image model that produces stunning results, but its 24GB+ memory requirement makes it challenging to run on many systems. GGUF quantization of FLUX.1-dev offers a solution, reducing memory usage by approximately 50% while maintaining excellent image quality.

Configure context sizes in Docker Model Runner with workarounds
Configuring context sizes in Docker Model Runner is more complex than it should be.