Enshittification di Ollama - I primi segnali
La mia opinione sull'attuale stato dello sviluppo di Ollama
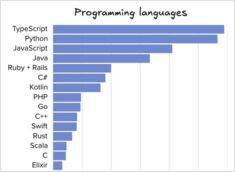
Ollama ha rapidamente diventato uno degli strumenti più popolari per eseguire i modelli LLM localmente. La sua semplice CLI e la gestione semplificata dei modelli l’hanno resa un’opzione di riferimento per gli sviluppatori che desiderano lavorare con i modelli AI al di fuori del cloud.