

Руководство по настройке размера контекста Docker Model Runner
Настройка размеров контекста в Docker Model Runner с обходными путями
Настройка размеров контекста в Docker Model Runner сложнее, чем должно быть.
Настройка размеров контекста в Docker Model Runner с обходными путями
Настройка размеров контекста в Docker Model Runner сложнее, чем должно быть.

Модель ИИ для дополнения изображений текстовыми инструкциями
Black Forest Labs выпустила FLUX.1-Kontext-dev, продвинутую модель искусственного интеллекта для преобразования изображений, которая дополняет существующие изображения с помощью текстовых инструкций.

Включите ускорение с помощью GPU для Docker Model Runner с поддержкой NVIDIA CUDA
Docker Model Runner — это официальный инструмент Docker для запуска моделей ИИ локально, но включение ускорения NVIDIA GPU в Docker Model Runner требует специальной настройки.

Сократите затраты на LLM на 80% благодаря умной оптимизации токенов
Оптимизация токенов — это критический навык, отличающий экономически эффективные приложения на основе LLM от экспериментов, разоряющих бюджет.
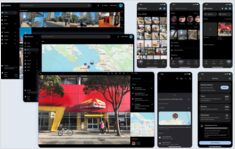
Ваши фотографии на самоуправляемом AI-облаке
Immich — это революционное открытое программное обеспечение с открытым исходным кодом для управления фотографиями и видео, которое дает вам полный контроль над вашими воспоминаниями. С функциями, сопоставимыми с Google Photos, включая распознавание лиц с использованием ИИ, умный поиск и автоматическое резервное копирование с мобильных устройств, при этом все ваши данные остаются конфиденциальными и защищенными на вашем собственном сервере.

Бенчмарки GPT-OSS 120b на трёх платформах ИИ
Я выкопал некоторые интересные тесты производительности GPT-OSS 120b, работающего на Ollama на трех разных платформах: NVIDIA DGX Spark, Mac Studio и RTX 4080. Модель GPT-OSS 120b из библиотеки Ollama весит 65ГБ, что означает, что она не помещается в 16ГБ видеопамяти RTX 4080 (или более новой RTX 5080).

Создавайте серверы MCP для ИИ-ассистентов с примерами на Python
Протокол Контекста Модели (MCP) революционизирует способ взаимодействия ИИ-ассистентов с внешними источниками данных и инструментами. В этом руководстве мы исследуем, как строить MCP-серверы на Python, с примерами, сосредоточенными на возможностях веб-поиска и парсинга.

Быстрая справка по командам Docker Model Runner
Docker Model Runner (DMR) — это официальное решение Docker для запуска моделей ИИ локально, представленное в апреле 2025 года. Этот справочник предоставляет быстрый доступ ко всем основным командам, настройкам и лучшим практикам.

Сравните Docker Model Runner и Ollama для локальных LLM
Запуск больших языковых моделей (LLM) локально стал все более популярным из-за приватности, контроля затрат и возможностей офлайн-работы. Ландшафт значительно изменился в апреле 2025 года, когда Docker представил Docker Model Runner (DMR), свое официальное решение для развертывания моделей ИИ.

Специализированные чипы ускоряют и удешевляют выводы ИИ
Будущее ИИ не ограничивается более умными моделями - это также вопрос более умного кремния. Специализированное оборудование для инференса ЛЛМ приводит к революции, аналогичной переходу майнинга биткоинов к ASIC.

Доступность, фактические розничные цены в шести странах и сравнение с Mac Studio.
NVIDIA DGX Spark — это реальный продукт, доступный к продаже с 15 октября 2025 года, ориентированный на разработчиков CUDA, которым требуется локальная работа с LLM с использованием интегрированного стека NVIDIA AI. Рекомендованная розничная цена в США составляет $3,999; в Великобритании, Германии и Японии розничная цена выше из-за НДС и каналов дистрибуции. Публичные ценники для Австралии и Южной Кореи (AUD/KRW) пока не опубликованы широко.

Интеграция Ollama с Go: руководство по SDK, примеры и лучшие практики для продакшена.
Этот гайд предоставляет всесторонний обзор доступных Go SDK для Ollama и сравнивает их функциональные возможности.

Сравнение скорости, параметров и производительности этих двух моделей
Вот сравнение между Qwen3:30b и GPT-OSS:20b, с акцентом на выполнение инструкций и параметры производительности, спецификации и скорость.

Не очень приятно.
Модели GPT-OSS от Ollama (https://www.glukhov.org/ru/llm-performance/ollama/ollama-gpt-oss-structured-output-issues/ “Ollama GPT-OSS”) постоянно сталкиваются с проблемами при работе со структурированным выводом, особенно при использовании с фреймворками вроде LangChain, OpenAI SDK, vllm и другими.

Несколько способов получения структурированного вывода из Ollama
Большие языковые модели (LLM) мощные, но в производстве мы редко хотим свободноформатных абзацев. Вместо этого нам нужны предсказуемые данные: атрибуты, факты или структурированные объекты, которые можно передать в приложение. Это Структурированный вывод LLM.

Мое собственное тестирование планирования моделей Ollama
Здесь я сравниваю, сколько VRAM новая версия Ollama выделяет для модели по сравнению с предыдущей версией. Новая версия работает хуже.