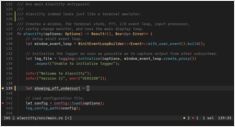
Qwen 3.6 27B und 35B MTP gegenüber Standard auf 16-GB-GPU
MTP im Vergleich zur Standard-Decodierung auf der RTX 4080 – echte Benchmarks
Ich habe die Leistung von spekulativem Decoding (Multi-Token Prediction, MTP) bei Qwen 3.6 27B und 35B auf einer RTX 4080 mit 16 GB VRAM getestet.