
GNOME Boxes: 特徴、利点、課題、および代替ソフトウェアに関する包括的なガイド
GNOME Boxes による Linux 用のシンプルな仮想マシン管理
現代のコンピューティング環境において、仮想化は開発、テスト、複数のオペレーティングシステムの実行において不可欠となっています。Linuxユーザーが仮想マシンを簡単に管理できる方法を探している場合、GNOME Boxesは、機能性を犠牲にすることなく、軽量で使いやすいオプションとして際立っています。
GNOME Boxes による Linux 用のシンプルな仮想マシン管理
現代のコンピューティング環境において、仮想化は開発、テスト、複数のオペレーティングシステムの実行において不可欠となっています。Linuxユーザーが仮想マシンを簡単に管理できる方法を探している場合、GNOME Boxesは、機能性を犠牲にすることなく、軽量で使いやすいオプションとして際立っています。

専用チップにより、AIの推論がより高速かつ低コストになっている。

在庫状況、6か国の実際の小売価格、およびMac Studioとの比較。
NVIDIA DGX Spark は現実のものであり、2025年10月15日に販売開始され、CUDA開発者向けに、統合されたNVIDIA AIスタックを使用してローカルLLM作業を行う必要がある人を対象としています。US MSRPは**$3,999**; UK/DE/JPの小売価格はVATとチャネルの影響で高くなっています。AUD/KRWの公開価格はまだ広く掲載されていません。

AIに最適な消費者向けGPUの価格 - RTX 5080およびRTX 5090
またまた、LLM(大規模言語モデル)に特に、AI全般に適した上位レベルの消費者向けGPUの価格を比較してみましょう。具体的には、以下を確認しています。
RTX-5080およびRTX-5090の価格
価格はわずかに下がっています。
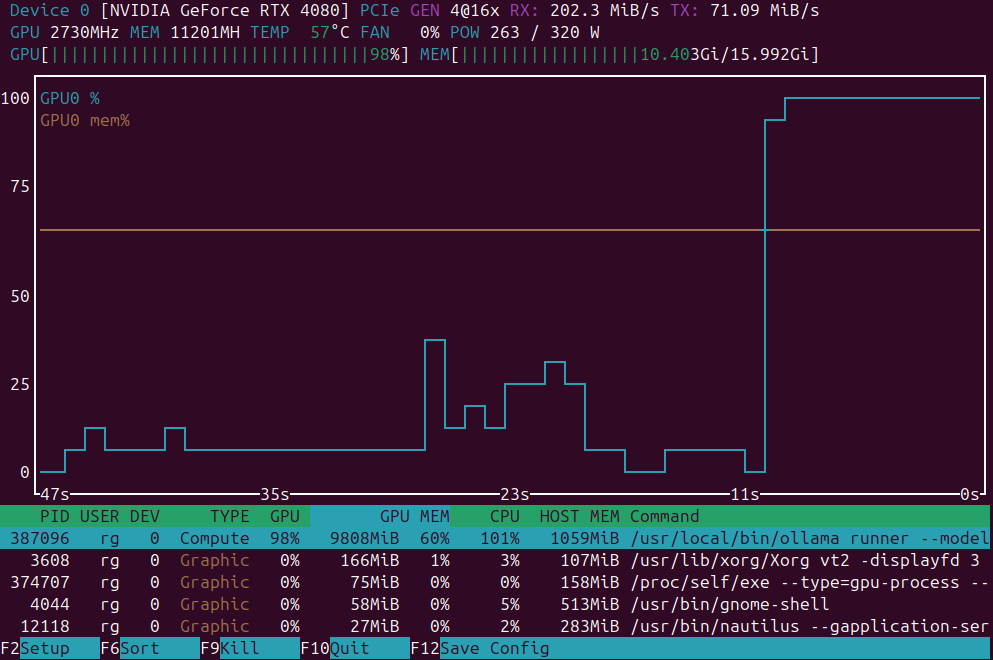
GPU負荷監視用のアプリケーションの簡単な一覧
GPU負荷監視アプリケーション: nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

2025年7月にはすぐに利用可能になるはずです。
NVIDIAは、NVIDIA DGX Sparkを近日中にリリースする予定です。これは、ブラックウェルアーキテクチャを採用し、128GB以上の統合RAMと1 PFLOPSのAI性能を備えた小型のAIスーパーコンピュータです。LLMを実行するための非常に便利なデバイスです。

AIに最適なGPU価格の更新 - RTX 5080およびRTX 5090
トップレベルの消費者向けGPUの価格を比較しましょう。特にLLM(大規模言語モデル)やAI全体に適したGPUについて詳しく見てみましょう。
具体的には、RTX 5080およびRTX 5090の価格を見てみましょう。わずかに価格が下がっています。

価格の現実チェック - RTX 5080 と RTX 5090
ちょうど3か月前には、RTX 5090は店頭に並んでいなかったが、今やそれらが販売されている。ただし、価格はMRSPよりもやや高くなっている。
最も安いオーストラリアでのRTX 5080およびRTX 5090の価格を比較してみよう。

より多くのRAM、より少ない電力消費、それでもなお高価な……
トップの自動化システムで、ある素晴らしい仕事に使用されます。

LLM用に2番目のGPUをインストールすることを考慮していますか?
PCIe レーンがLLM性能に与える影響? タスクによります。トレーニングやマルチGPUの推論では、パフォーマンスの低下が顕著です。

ではなぜこのBSODを目にしてきたのか...
この問題に強く打たれました。しかし、あなたのブルースクリーン(BSOD)が私のものと似ている場合は、PCを調査し、テストすることをお勧めします。原因はインテルの13世代および14世代CPU劣化問題でした。

インテルCPUにおけるOllamaの効率的なコアとパフォーマンスコアの比較
私はある仮説をテストしたいと思っています。すなわち、「インテルCPUのすべてのコアを活用することで、LLMの速度が向上するか?」というものです。このテストについては、ALL cores on Intel CPU would raise the speed of LLMs?をご覧ください。
新しいgemma3 27bitモデル(gemma3:27b、ollama上では17GB)が私のGPUの16GB VRAMに収まらず、部分的にCPU上での実行に頼っているという点が気になります。

AIは多くのパワーが必要です…
現代の世界の混乱の中でも、ここではさまざまなカードのテクスペックを比較、AIタスクに適したAI用のカードについて見ていく。
(Deep Learning、
Object Detection、
およびLLMs)。
しかし、これらはすべて非常に高価です。

オラマを並列リクエストの実行に設定する。
Ollama サーバーが同時に2つのリクエストを受け取った場合、その動作は設定と利用可能なシステムリソースに依存します。

古いプリンタードライバと比べてはるかに簡単です
ET-8500をWindowsにインストールする方法は、マニュアルに詳細に記載されています。ET-8500 Linuxドライバのインストールは簡単ですが、簡単ではありません。このガイドは、2026年のドキュメントツール: Markdown、LaTeX、PDFおよび印刷ワークフロー ハブの一部です。

LLMのGPUとCPUでの速度をテストしてみましょう
いくつかのLLM(大規模言語モデル)のバージョン(llama3(メタ/Facebook)、phi3(マイクロソフト)、gemma(グーグル)、mistral(オープンソース))におけるCPUおよびGPUでの予測速度の比較。