

LLMのコスト削減:トークン最適化戦略
スマートなトークン最適化でLLMのコストを80%削減
トークンの最適化は、コスト効率の高いLLMアプリケーションと、予算を浪費する実験を分けるための重要なスキルです。
スマートなトークン最適化でLLMのコストを80%削減
トークンの最適化は、コスト効率の高いLLMアプリケーションと、予算を浪費する実験を分けるための重要なスキルです。
ご自身でホストするAIを活用したバックアップに使用される写真
Immich は、あなたの思い出を完全にコントロールできる、革新的なオープンソースでセルフホスト型の写真および動画管理ソリューションです。Google Photos と競合する機能を備えており、AI による顔認識、スマート検索、自動モバイルバックアップを含みながら、あなたのデータをプライバシーとセキュリティを保ったまま、あなたのサーバー上に保管します。

GPT-OSS 120bの3つのAIプラットフォームにおけるベンチマーク
私は、Ollama上でGPT-OSS 120bのパフォーマンステストを3つの異なるプラットフォームで確認しました:NVIDIA DGX Spark, Mac Studio, and RTX 4080。OllamaライブラリのGPT-OSS 120bモデルは65GBあり、これはRTX 4080(または新しいRTX 5080の16GB VRAMには収まらないことを意味します。

Pythonの例を使ってAIアシスタント用のMCPサーバーを構築する
モデルコンテキストプロトコル(MCP)は、AIアシスタントが外部データソースやツールとどのように相互作用するかを革命的に変えてきました。本ガイドでは、ウェブ検索およびスクレイピング機能に焦点を当てた例を用いて、MCPサーバーをPythonで構築する方法について説明します。

Docker Model Runner コマンドのクイックリファレンス
Docker Model Runner (DMR) は、2025年4月に導入された Docker の公式ソリューションで、AIモデルをローカルで実行するためのものです。このチートシートでは、すべての必須コマンド、構成、およびベストプラクティスのクイックリファレンスを提供しています。

Docker Model RunnerとOllamaを比較してみる:ローカルLLM向け
ローカルで大規模言語モデル(LLM)を実行する は、プライバシー、コスト管理、オフライン機能のためにますます人気になってきています。 2025年4月にDockerが**Docker Model Runner (DMR)**を導入し、AIモデルの展開用の公式ソリューションとして登場したことで、状況は大きく変わりました。

ASIC とカスタムシリコンが、大規模言語モデル(LLM)の推論速度と効率を推進します。

6 カ国における実勢価格、Mac Studio との比較、および入手可能性について。
NVIDIA DGX Spark は実在する製品で、2025 年 10 月 15 日から販売開始されます。統合された NVIDIA AI スタック を利用して、ローカルでの LLM 作業 が必要な CUDA 開発者を主なターゲットとしています。米国での MSRP は 3,999 ドル です。英国・ドイツ・日本 での小売価格は、VAT(消費税)や流通チャネルの事情により高くなります。オーストラリアドル (AUD) や韓国ウォン (KRW) の公開価格はまだ広く発表されていません。

OllamaをGoで統合する: SDKガイド、例、およびプロダクションでのベストプラクティス
このガイドでは、利用可能な Go SDK for Ollama の包括的な概要を提供し、それらの機能セットを比較します。

これらの2つのモデルの速度、パラメータ数、およびパフォーマンスを比較する
以下は、Qwen3:30b と GPT-OSS:20b の比較です。 指示の遵循度(Instruction Following)とパフォーマンスパラメータ、仕様、速度に焦点を当てています。

あまり良くない。
OllamaのGPT-OSSモデルは、LangChainやOpenAI SDK、vllmなどのフレームワークと使用する際に、構造化された出力を処理する際に繰り返し問題が発生しています。

Ollamaから構造化された出力を取得する方法
大規模言語モデル(LLM) は強力ですが、本番環境では自由な形式のパラグラフ(段落)を返すことは稀です。 代わりに、アプリに投入できる予測可能なデータ:属性、事実、または構造化されたオブジェクトを求めます。 それが LLM 構造化出力 です。

オラマモデルのスケジューリングに関する自分のテスト
ここでは、新しいバージョンのOllamaがモデルに対してどのくらいのVRAMを割り当てているかについて、Ollama VRAM割り当てと以前のOllamaバージョンを比較しています。新しいバージョンは、以前のバージョンよりも劣っています。

現在のOllama開発状況に対する私の見解
Ollama は、LLM をローカルで実行するためのツールとして、非常に人気のあるツールの一つとなっています。
シンプルな CLI と、モデル管理の簡素化により、クラウド外で AI モデルと仕事をしたい開発者にとっての定番のオプションとなっています。

2025年のOllamaで最も注目されているUIの概要
ローカルにホストされた Ollama は、あなたのマシン上で大規模言語モデルを実行できるが、コマンドライン経由での使用はユーザーにとって使いにくい。
以下に、ローカルの Ollama に接続するための、いくつかのオープンソースプロジェクトが提供する ChatGPTスタイルのインターフェース がある。
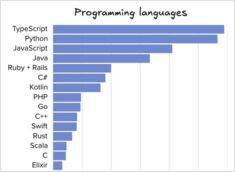
ソフトウェアエンジニアリングツールおよび言語の比較
The Pragmatic Engineerのレターは数日前に、2025年中盤におけるプログラミング言語、IDE、AIツールの普及状況などのデータを掲載しました。