

Guía de configuración del tamaño de contexto de Docker Model Runner
Configure tamaños de contexto en Docker Model Runner con soluciones alternativas
Configuración de tamaños de contexto en Docker Model Runner es más compleja de lo que debería ser.
Configure tamaños de contexto en Docker Model Runner con soluciones alternativas
Configuración de tamaños de contexto en Docker Model Runner es más compleja de lo que debería ser.

Habilite la aceleración de GPU para Docker Model Runner con soporte de NVIDIA CUDA
Docker Model Runner es la herramienta oficial de Docker para ejecutar modelos de IA localmente, pero habilitar la aceleración de GPU de NVidia en Docker Model Runner requiere una configuración específica.

Referencia rápida para comandos de Docker Model Runner
Docker Model Runner (DMR) es la solución oficial de Docker para ejecutar modelos de IA localmente, introducida en abril de 2025. Esta guía rápida proporciona una referencia rápida para todos los comandos esenciales, configuraciones y mejores prácticas.

Compare Docker Model Runner y Ollama para LLM local
Correr modelos de lenguaje grandes (LLMs) localmente ha ganado popularidad cada vez mayor por razones de privacidad, control de costos y capacidades fuera de línea. El paisaje cambió significativamente en abril de 2025 cuando Docker introdujo Docker Model Runner (DMR), su solución oficial para la implementación de modelos de IA.

Integre Ollama con Go: guía del SDK, ejemplos y mejores prácticas para producción.
Este guía proporciona una visión general completa de los disponibles SDKs de Go para Ollama y compara sus conjuntos de características.

+ Ejemplos Específicos Utilizando LLMs de Pensamiento
En este post, exploraremos dos formas de conectar tu aplicación Python a Ollama: 1. A través de HTTP REST API; 2. A través de la biblioteca oficial de Python de Ollama.

Mi visión sobre el estado actual del desarrollo de Ollama
Ollama ha pasado rápidamente a ser una de las herramientas más populares para ejecutar modelos de lenguaje grande (LLM) en local.
Su CLI simple y su gestión de modelos optimizada han convertido a Ollama en una opción preferida para desarrolladores que desean trabajar con modelos de IA fuera de la nube.

Breve visión general de las interfaces de usuario más destacadas para Ollama en 2025
Locally hosted Ollama permite ejecutar modelos de lenguaje grandes en tu propia máquina, pero usarlo desde la línea de comandos no es muy amigable para el usuario. Aquí hay varios proyectos de código abierto que ofrecen interfaces estilo ChatGPT que se conectan a un Ollama local.

qwen3 8b, 14b y 30b, devstral 24b, mistral small 24b
En este test estoy comparando cómo diferentes LLMs alojados en Ollama traducen una página Hugo en inglés al alemán.

Lista breve de proveedores de LLM
El uso de LLMs no es muy costoso, podría no haber necesidad de comprar una nueva GPU impresionante. Aquí hay una lista si proveedores de LLM en la nube con LLMs que alojan.

Comparando dos modelos deepseek-r1 con dos modelos base
DeepSeek’s primer generación de modelos de razonamiento con un rendimiento comparable al de OpenAI-o1, incluyendo seis modelos densos destilados de DeepSeek-R1 basados en Llama y Qwen.

Lista de comandos de Ollama actualizada: ls, ps, run, serve, etc.
Esta hoja de trucos de la CLI de Ollama se centra en los comandos que usas a diario (ollama ls, ollama serve, ollama run, ollama ps, gestión de modelos y flujos de trabajo comunes), con ejemplos que puedes copiar y pegar.

Comparando dos motores de búsqueda de IA autoalojados
La comida increíble también es un placer para la vista. Pero en esta entrada compararemos dos sistemas de búsqueda basados en IA, Farfalle y Perplexica.
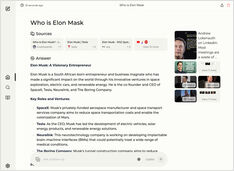
¿Ejecutando un servicio de estilo Copilot de forma local? ¡Fácil!
¡Eso es muy emocionante! En lugar de llamar a Copilot o Perplexity.ai y contarle al mundo entero lo que buscas, ¡ahora puedes alojar un servicio similar en tu propio PC o portátil!

Los archivos de modelos LLM de Ollama ocupan mucho espacio.
Después de instalar Ollama, es mejor reconfigurar Ollama para que los almacene en la nueva ubicación de inmediato. Así, cuando descargamos un nuevo modelo, no se descarga en la ubicación antigua.