

Problemas de Saída Estruturada do Ollama GPT-OSS
Não muito agradável.
Modelos GPT-OSS do Ollama têm problemas recorrentes ao lidar com saídas estruturadas, especialmente quando usados com frameworks como LangChain, OpenAI SDK, vllm e outros.
Não muito agradável.
Modelos GPT-OSS do Ollama têm problemas recorrentes ao lidar com saídas estruturadas, especialmente quando usados com frameworks como LangChain, OpenAI SDK, vllm e outros.

Alguns modos de obter saída estruturada do Ollama
Grandes Modelos de Linguagem (LLMs) são poderosos, mas, em produção, raramente queremos parágrafos livres. Em vez disso, queremos dados previsíveis: atributos, fatos ou objetos estruturados que você pode alimentar em um aplicativo. Isso é Saída Estruturada de LLM.

Tentei ambos o Kubuntu e o KDE Neon, o Kubuntu é mais estável.
Para fãs do KDE Plasma, duas distribuições Linux frequentemente surgem em discussões:
Kubuntu e KDE Neon.
Elas podem parecer similares — ambas vêm com o KDE Plasma como desktop padrão, ambas são baseadas no Ubuntu e ambas são amigáveis para novatos.

Meu próprio teste de escalonamento do modelo ollama
Aqui estou comparando quanto de VRAM a nova versão do Ollama aloca para o modelo com a versão anterior do Ollama. A nova versão é pior.

Notas sobre a configuração de IP estático no Linux
Este guia irá guiá-lo pelo processo de alterar o endereço IP estático em um servidor Ubuntu.

Minha visão sobre o estado atual do desenvolvimento do Ollama
Ollama tornou-se rapidamente uma das ferramentas mais populares para executar LLMs localmente.
Sua CLI simples e sua gestão de modelos aprimorada tornaram-na uma opção preferida para desenvolvedores que desejam trabalhar com modelos de IA fora do cloud.

Plataforma alternativa de comunicação VoIP
Mumble é uma aplicação de voz sobre IP (VoIP) gratuita e de código aberto, projetada principalmente para comunicação de voz em tempo real. Ela utiliza uma arquitetura cliente-servidor, onde os usuários se conectam a um servidor compartilhado para conversar entre si.

Visão geral rápida das interfaces de usuário mais proeminentes para Ollama em 2025
O Ollama hospedado localmente permite que você execute modelos de linguagem grandes em sua própria máquina, mas usar o Ollama via linha de comando não é amigável para o usuário.
Aqui estão vários projetos de código aberto que oferecem interfaces do tipo ChatGPT que se conectam a um Ollama local.
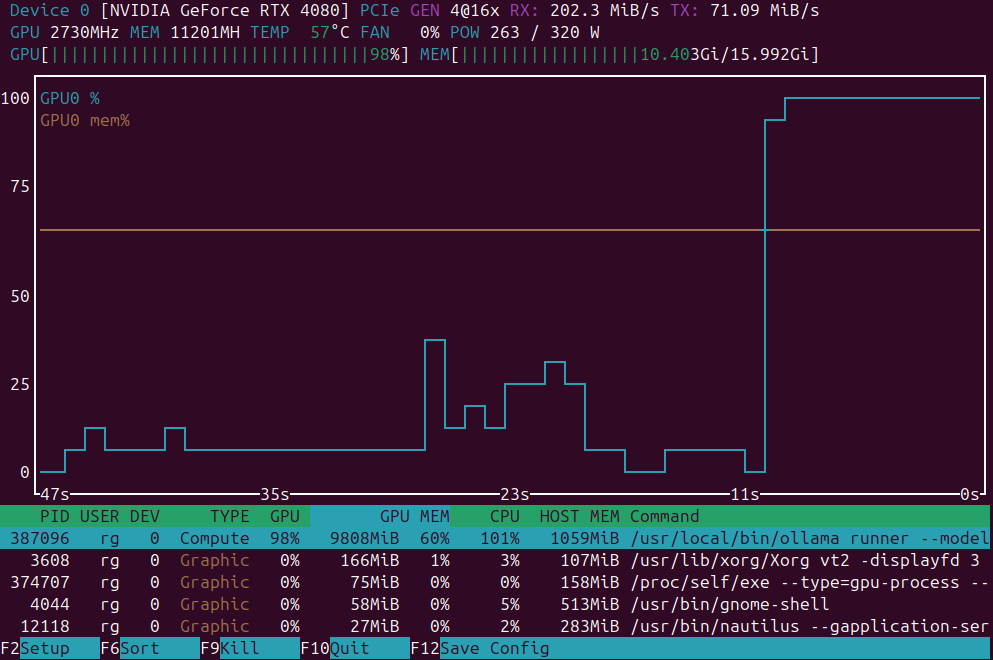
Pequena lista de aplicações para monitoramento de carga da GPU
Aplicações de monitoramento de carga da GPU:
nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

Instalando o pequeno k3s Kubernetes em um cluster de homelab
Aqui está um passo a passo para a instalação de um cluster K3s com 3 nós em servidores de metal nu (1 mestre + 2 trabalhadores).

Breve visão geral das variantes do Kubernetes
Comparando distribuições de self-hosting Kubernetes para hospedagem em servidores bare-metal ou domésticos, com foco na facilidade de instalação, desempenho, requisitos do sistema e conjuntos de recursos.
Escolhendo a melhor versão do Kubernetes para o nosso homelab
Estou comparando variantes de Kubernetes auto-hospedado que se adequam ao homelab baseado no Ubuntu com 3 nós (16 GB de RAM, 4 núcleos cada), focando na facilidade de instalação e manutenção, suporte para volumes persistentes e LoadBalancers.
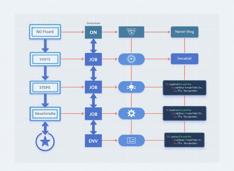
Um pouco sobre as ações comuns do GitHub e sua estrutura.
GitHub Actions é uma plataforma de automação e CI/CD dentro do GitHub, usada para construir, testar e implantar seu código com base em eventos como pushes, pull requests ou em um agendamento.

Por sinal, docker-compose é diferente de docker compose...
Aqui está uma
Docker Compose cheatsheet
com exemplos anotados para ajudá-lo a dominar os arquivos e comandos do Compose rapidamente.
Sobre o Obsidian ...
Aqui está uma análise detalhada de
Obsidian como uma ferramenta poderosa para gestão do conhecimento pessoal (GKP),
explicando sua arquitetura, funcionalidades, vantagens e como apoia fluxos de trabalho modernos de conhecimento.

Em julho de 2025, em breve deverá estar disponível
Nvidia está prestes a lançar NVIDIA DGX Spark - pequeno supercomputador de IA baseado na arquitetura Blackwell com 128+GB de memória unificada e 1 PFLOPS de desempenho de IA. Dispositivo interessante para executar LLMs.