

호주 RTX 5090, 2026 년 3 월 가격과 재고 현실
호주에서는 RTX 5090 가 품귀 현상을 보이고 가격이 비쌉니다.
호주에 RTX 5090 재고가 있습니다. 마침내. 하지만 하나를 찾아도 현실과 동떨어진 프리미엄 가격을 지불해야 합니다.
호주에서는 RTX 5090 가 품귀 현상을 보이고 가격이 비쌉니다.
호주에 RTX 5090 재고가 있습니다. 마침내. 하지만 하나를 찾아도 현실과 동떨어진 프리미엄 가격을 지불해야 합니다.

2025년 1월 GPU 및 RAM 가격 확인
오늘 우리는 최상위 소비자용 GPU와 RAM 모듈을 살펴보겠습니다.
구체적으로는
RTX-5080 및 RTX-5090 가격, 그리고 32GB (2x16GB) DDR5 6000을 살펴보겠습니다.

지금 호주 현지 소매업체의 실제 AUD 가격
NVIDIA DGX Spark (GB10 Grace Blackwell) 은 이제 주요 PC 판매점에서 재고 상태로 호주에서도 구매 가능 합니다. 전 세계 DGX Spark 가격과 가용성 을 지켜보셨다면, 호주의 가격은 저장 구성과 판매처에 따라 6,249 호주 달러에서 7,999 호주 달러 사이임을 알게 되시면 흥미로워하실 것입니다.

우브untu에서 네트워크 문제를 해결한 방법
새로운 커널을 자동으로 설치한 후 Ubuntu 24.04에서 이더넷 네트워크가 사라짐 문제가 발생했습니다. 이 문제가 두 번째로 발생했기 때문에, 이 문제를 겪고 있는 다른 사람들에게 도움이 되기 위해 해결 방법을 여기에 기록해 두고자 합니다.

짧은 글입니다, 단지 가격을 알립니다.
이러한 광적인 RAM 가격 변동성 으로 인해 보다 명확한 그림을 그리기 위해, 먼저 우리가 직접 호주 내 RAM 가격을 추적 해보겠습니다.

AI 수요로 인한 공급 부족으로 RAM 가격이 163~619% 급등
2025 년 말, 메모리 시장은 모든 세그먼트에서 램 가격이 급등 하는 전례 없는 가격 변동성을 경험하고 있습니다.

AI 에 적합한 소비자용 GPU 가격 – RTX 5080 과 RTX 5090
특히 LLM 과 일반적인 AI 에 적합한 최상위 소비자용 GPU 의 가격을 비교해 보겠습니다. 구체적으로는 RTX-5080 과 RTX-5090 가격 에 초점을 맞추고 있습니다.

오픈 모델로 저비용 하드웨어에서 엔터프라이즈 AI 배포
AI 의 민주화는 이제 현실이 되었습니다. Llama, Mistral, Qwen 과 같은 오픈소스 LLM 이 독점 모델들과 경쟁할 수준에 도달함에 따라, 팀들은 소비자용 하드웨어를 활용한 AI 인프라 구축 을 통해 비용을 절감하면서도 데이터 프라이버시와 배포에 대한 완전한 통제를 유지할 수 있게 되었습니다.
GNOME Boxes를 사용한 Linux용 간단한 가상 머신 관리
현대 컴퓨팅 환경에서 가상화는 개발, 테스트, 여러 운영 체제의 실행에 필수적인 요소가 되었습니다. Linux 사용자들이 가상 머신을 관리하는 데 간단하고 직관적인 방법을 원한다면, GNOME Boxes는 기능성을 희생하지 않고 사용 편의성을 중시하는 가벼운 사용자 친화적인 옵션으로 두드러집니다.

6 개 국가의 가용성, 실제 소매 가격 및 Mac Studio 와의 비교.
NVIDIA DGX Spark 는 실존하며, 2025 년 10 월 15 일에 출시되어 통합 NVIDIA AI 스택을 갖춘 로컬 LLM 작업이 필요한 CUDA 개발자를 대상으로 합니다. 미국 권장 소매가 (MSRP) 는 3,999 달러이며, 영국/독일/일본의 소매가는 부가가치세 (VAT) 와 유통 채널 비용으로 인해 더 높습니다. 호주/한국의 공개 스티커 가격은 아직 널리 발표되지 않았습니다.
프록시모克斯란 무엇인가?
**Proxmox Virtual Environment (Proxmox VE)**는 Debian 기반으로 만들어진 오픈소스, 타입-1 하이퍼바이저 및 데이터센터 오케스트레이션 플랫폼입니다.

AI 에 적합한 소비자용 GPU 가격 - RTX 5080 과 RTX 5090
LLM 을 비롯한 AI 작업에 적합한 최상위 소비자용 GPU 의 가격을 비교해 보겠습니다. 특히 RTX-5080 과 RTX-5090 가격 에 주목합니다. 가격이 약간 하락했습니다.
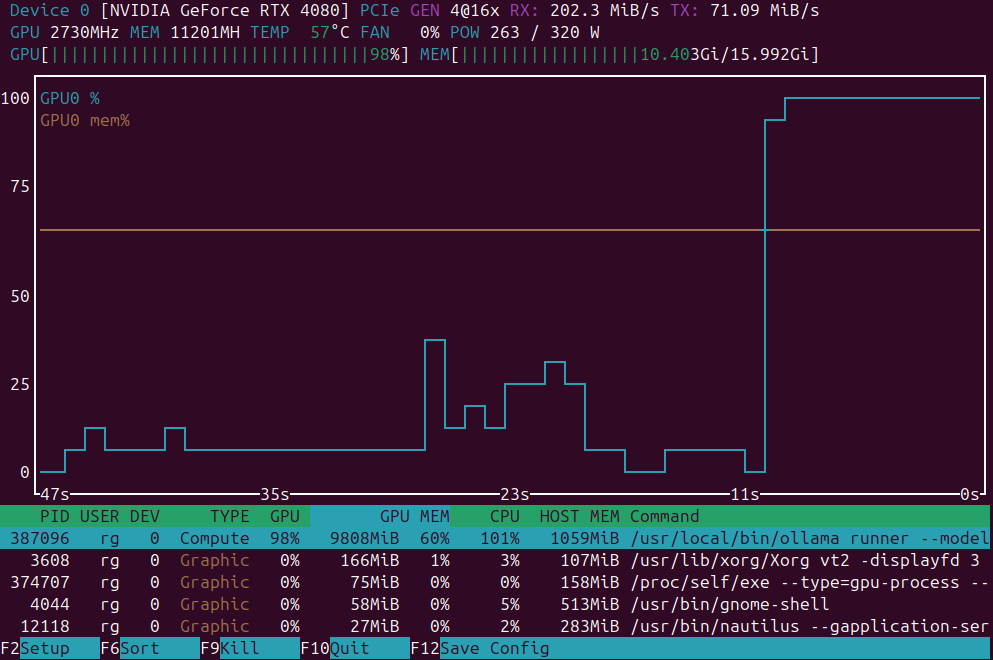
GPU 부하 모니터링을 위한 애플리케이션 목록
GPU 로드 모니터링 애플리케이션: nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

2025 년 7 월이면 곧 이용 가능할 것입니다.
Nvidia 가 곧 NVIDIA DGX Spark를 출시합니다. 128GB 이상의 통합 RAM 과 1 PFLOPS AI 성능을 갖춘 블랙웰 (Blackwell) 아키텍처 기반의 소형 AI 슈퍼컴퓨터입니다. LLM 을 실행하기에 훌륭한 기기입니다.

AI 적합 GPU 가격 업데이트 - RTX 5080 및 RTX 5090
2026 년의 컴퓨팅 하드웨어, 특히 LLM 과 AI 전반에 적합한 최상위 소비자용 GPU 의 가격을 비교해 보겠습니다. 구체적으로는 RTX 5080 과 RTX 5090 가격 을 살펴보세요. 가격이 약간 하락했습니다.

가격 현실 점검 - RTX 5080 과 RTX 5090
3 개월 전까지만 해도 상점에서 RTX 5090 을 찾아볼 수 없었는데, 이제는 등장했지만 가격은 권장 소비자 가격 (MRSP) 보다 약간 높은 편입니다. 가장 저렴한 호주 내 RTX 5080 과 RTX 5090 가격 을 비교해보고 상황이 어떻게 변했는지 확인해 보겠습니다.
참고로 2025 년 7 월 호주 내 RTX 5080 과 RTX 5090 가격, 2025 년 10 월, 그리고 2025 년 11 월 자료도 함께 참고해 보세요.