
Сравнение производительности Ollama: NVIDIA DGX Spark против Mac Studio против RTX-4080
Бенчмарки GPT-OSS 120b на трёх платформах ИИ
Я выкопал некоторые интересные тесты производительности GPT-OSS 120b, работающего на Ollama на трех разных платформах: NVIDIA DGX Spark, Mac Studio и RTX 4080. Модель GPT-OSS 120b из библиотеки Ollama весит 65ГБ, что означает, что она не помещается в 16ГБ видеопамяти RTX 4080 (или более новой RTX 5080).
Да, модель может работать с частичной выгрузкой на CPU, и если у вас 64ГБ системной оперативной памяти (как у меня), вы можете попробовать это. Однако такая настройка не будет близка к производственной производительности. Для действительно требовательных рабочих нагрузок вам, возможно, потребуется что-то вроде NVIDIA DGX Spark, который специально разработан для высоконагруженных ИИ-задач. Для получения дополнительной информации о производительности LLM — пропускная способность против задержки, ограничения VRAM и бенчмарки по различным средам выполнения и оборудованию — см. LLM Performance: Benchmarks, Bottlenecks & Optimization.

Я ожидал, что этот LLM значительно выиграет от работы на “высокооперативном ИИ-устройстве” вроде DGX Spark. Хотя результаты хорошие, они не так драматически лучше, как можно было бы ожидать, учитывая разницу в цене между DGX Spark и более доступными вариантами.
TL;DR
Ollama с GPT-OSS 120b сравнение производительности на трех платформах:
| Устройство | Производительность оценки запроса (токенов/сек) | Производительность генерации (токенов/сек) | Примечания |
|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | Лучшая общая производительность, полностью ускорена GPU |
| Mac Studio | Неизвестно | 34 → 6 | Один тест показал ухудшение производительности при увеличении размера контекста |
| RTX 4080 | 969 | 12.45 | 78% CPU / 22% GPU из-за ограничений VRAM |
Спецификации модели:
- Модель: GPT-OSS 120b
- Параметры: 117Б (архитектура Mixture-of-Experts)
- Активные параметры за проход: 5.1Б
- Квантование: MXFP4
- Размер модели: 65ГБ
Это похоже по архитектуре на другие модели MoE, такие как Qwen3:30b, но в гораздо большем масштабе.
GPT-OSS 120b на NVIDIA DGX Spark
Данные о производительности LLM для NVIDIA DGX Spark взяты из официального блога Ollama (ссылка ниже в разделе Полезные ссылки). DGX Spark представляет собой вход NVIDIA на рынок персональных ИИ-суперкомпьютеров, оснащенных 128ГБ унифицированной памяти, специально разработанной для работы с большими языковыми моделями.

Производительность GPT-OSS 120b выглядит впечатляюще — 41 токен/сек для генерации. Это делает его явным победителем для этой конкретной модели, показывая, что дополнительная емкость памяти может действительно повлиять на очень большие модели.
Однако производительность средних и крупных LLM не выглядит столь убедительно. Это особенно заметно с Qwen3:32b и Llama3.1:70b — именно теми моделями, где вы ожидаете, что высокая емкость памяти будет сиять. Производительность на DGX Spark для этих моделей не вдохновляет, если сравнивать с премиальной ценой. Если вы в основном работаете с моделями в диапазоне 30-70Б параметров, возможно, стоит рассмотреть альтернативы, такие как хорошо настроенная рабочая станция) или даже Quadro RTX 5880 Ada с ее 48ГБ видеопамяти.
GPT-OSS 120b на Mac Studio Max
Канал Slinging Bits на YouTube провел всесторонние тесты работы GPT-OSS 120b на Ollama с различными размерами контекста. Результаты выявили серьезную проблему с производительностью: скорость генерации модели резко упала с 34 токенов/с до всего 6 токенов/с по мере увеличения размера контекста.
Это ухудшение производительности, вероятно, вызвано давлением на память и тем, как macOS управляет унифицированной архитектурой памяти. Хотя Mac Studio Max имеет впечатляющую унифицированную память (до 192ГБ в конфигурации M2 Ultra), способ ее работы с очень большими моделями при увеличении нагрузки на контекст значительно отличается от выделенной видеопамяти GPU.


Для приложений, требующих стабильной производительности при различных длинах контекста, это делает Mac Studio менее подходящим для GPT-OSS 120b, несмотря на его иначе отличные возможности для ИИ-задач. Возможно, у вас будет больше удачи с меньшими моделями или стоит рассмотреть использование функций параллельной обработки запросов Ollama для максимизации пропускной способности в производственных сценариях.
GPT-OSS 120b на RTX 4080
Изначально я думал, что запуск Ollama с GPT-OSS 120b на моем потребительском ПК не будет особенно увлекательным, но результаты приятно удивили меня. Вот что произошло, когда я протестировал его с этим запросом:
$ ollama run gpt-oss:120b --verbose Сравните погоду в столицах штатов Австралии
Размышление...
Нам нужно сравнить погоду в столицах штатов Австралии. Предоставить сравнение, возможно, включить
...
*Все данные доступны с сентября 2024 года; любые обновления от BOM после этой даты могут немного изменить числа, но общие закономерности остаются неизменными.*
общее время: 4м39.942105769с
время загрузки: 75.843974мс
количество оценок запроса: 75 токен(ов)
время оценки запроса: 77.341981мс
скорость оценки запроса: 969.72 токенов/с
количество оценок: 3483 токен(ов)
время оценки: 4м39.788119563с
скорость оценки: 12.45 токенов/с
Теперь вот интересная часть — Ollama с этой LLM работал в основном на CPU! Модель просто не помещается в 16ГБ видеопамяти, поэтому Ollama умно выгрузил большую ее часть в системную память. Вы можете увидеть это поведение с помощью команды ollama ps:
$ ollama ps
ИМЯ ID РАЗМЕР ПРОЦЕССОР КОНТЕКСТ
gpt-oss:120b a951a23b46a1 65 ГБ 78%/22% CPU/GPU 4096
Несмотря на работу с разделением 78% CPU / 22% GPU, RTX 4080 все равно демонстрирует приличную производительность для модели такого размера. Оценка запроса происходит молниеносно — 969 токенов/с, а даже скорость генерации 12.45 токенов/с пригодна для многих приложений.
Это особенно впечатляет, если учитывать, что:
- Модель почти в 4 раза больше доступной видеопамяти
- Большая часть вычислений происходит на CPU (которая выигрывает от моих 64ГБ системной памяти)
- Понимание как Ollama использует ядра CPU может помочь оптимизировать эту настройку
Кто бы мог подумать, что потребительский GPU сможет обрабатывать модель с 117Б параметров, не говоря уже о пригодной производительности? Это демонстрирует мощь интеллектуального управления памятью Ollama и важность наличия достаточного количества системной памяти. Если вы заинтересованы в интеграции Ollama в свои приложения, ознакомьтесь с этим руководством по использованию Ollama с Python.
Примечание: Хотя это работает для экспериментов и тестирования, вы заметите, что GPT-OSS может иметь некоторые особенности, особенно с форматами структурированного вывода.
Чтобы исследовать больше бенчмарков, компромиссов между выгрузкой в VRAM и CPU и настройкой производительности на различных платформах, ознакомьтесь с нашим LLM Performance: Benchmarks, Bottlenecks & Optimization хабом.
Основные источники
- Ollama на NVIDIA DGX Spark: Бенчмарки производительности - Официальный пост в блоге Ollama с всесторонними данными о производительности DGX Spark
- GPT-OSS 120B на Mac Studio - YouTube Slinging Bits - Подробное видео с тестированием GPT-OSS 120b с различными размерами контекста
Связанное чтение по сравнению оборудования и Ollama
- DGX Spark vs. Mac Studio: Практический, проверенный ценой взгляд на персональный ИИ-суперкомпьютер NVIDIA - Подробное объяснение конфигураций DGX Spark, глобальных цен и прямого сравнения с Mac Studio для локальной работы с ИИ
- NVIDIA DGX Spark - Ожидания - Раннее освещение DGX Spark: доступность, цены и технические характеристики
- Цены на NVidia RTX 5080 и RTX 5090 в Австралии - октябрь 2025 - Текущие рыночные цены на потребительские GPU следующего поколения
- Насколько хорош Quadro RTX 5880 Ada 48GB? - Обзор 48ГБ рабочего GPU-альтернативы для ИИ-задач
- Ollama cheatsheet - Всестороннее руководство по командам и советам для Ollama
P.S. Новые данные
Уже после публикации этого поста я нашел на сайте NVIDIA дополнительные статистические данные о LLM Inferrence на DGX Spark:
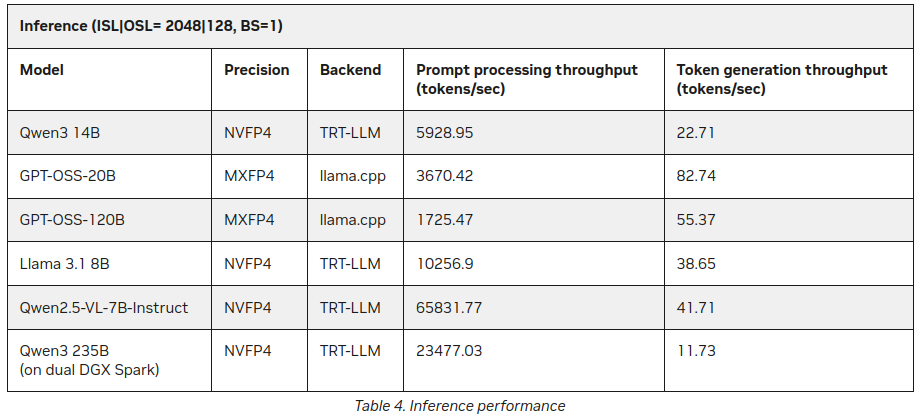
Лучше, но не сильно противоречит вышесказанному (55 токенов против 41), но это интересное дополнение, особенно о Qwen3 235B (на двойном DGX Spark) производящем 11+ токенов/секунду
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
