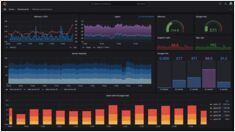
Monitorear la inferencia de LLM en producción (2026): Prometheus y Grafana para vLLM, TGI, llama.cpp
Monitorea LLM con Prometheus y Grafana
La inferencia de LLM parece “solo otra API” — hasta que aparecen picos de latencia, se forman colas y tus GPUs se quedan en un 95% de memoria sin una explicación obvia.