

Guía de configuración del tamaño de contexto de Docker Model Runner
Configure tamaños de contexto en Docker Model Runner con soluciones alternativas
Configuración de tamaños de contexto en Docker Model Runner es más compleja de lo que debería ser.
Configure tamaños de contexto en Docker Model Runner con soluciones alternativas
Configuración de tamaños de contexto en Docker Model Runner es más compleja de lo que debería ser.

Modelo de IA para aumentar imágenes con instrucciones de texto
Black Forest Labs ha lanzado FLUX.1-Kontext-dev, un avanzado modelo de inteligencia artificial de imagen a imagen que mejora imágenes existentes mediante instrucciones de texto.

Habilite la aceleración de GPU para Docker Model Runner con soporte de NVIDIA CUDA
Docker Model Runner es la herramienta oficial de Docker para ejecutar modelos de IA localmente, pero habilitar la aceleración de GPU de NVidia en Docker Model Runner requiere una configuración específica.

Reduzca los costos de los modelos de lenguaje grande en un 80% con una optimización inteligente de tokens
La optimización de tokens es la habilidad crítica que separa las aplicaciones de LLM eficientes económicamente de experimentos que consumen presupuesto.
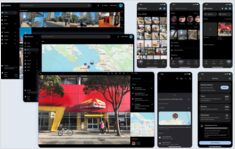
Sus fotos en la copia de seguridad impulsada por IA alojada en su propio servidor
Immich es una solución revolucionaria de código abierto y autohospedada para la gestión de fotos y videos que te da el control total sobre tus recuerdos. Con características que rivalizan con Google Photos, incluyendo reconocimiento facial impulsado por inteligencia artificial, búsqueda inteligente y copia de seguridad automática desde dispositivos móviles, todo mientras mantienes tus datos privados y seguros en tu propio servidor.

Resultados de benchmarks de GPT-OSS 120b en tres plataformas de IA
Investigué algunos interesantes tests de rendimiento del modelo GPT-OSS 120b ejecutándose en Ollama en tres plataformas diferentes: NVIDIA DGX Spark, Mac Studio y RTX 4080. El modelo GPT-OSS 120b del repositorio Ollama tiene un tamaño de 65GB, lo que significa que no cabe en los 16GB de VRAM de un RTX 4080 (ni en el más reciente RTX 5080).

Construya servidores MCP para asistentes de IA con ejemplos en Python
El Protocolo de Contexto del Modelo (MCP) está revolucionando la forma en que los asistentes de IA interactúan con fuentes de datos externas y herramientas. En esta guía, exploraremos cómo construir servidores MCP en Python, con ejemplos centrados en las capacidades de búsqueda en la web y raspado.

Referencia rápida para comandos de Docker Model Runner
Docker Model Runner (DMR) es la solución oficial de Docker para ejecutar modelos de IA localmente, introducida en abril de 2025. Esta guía rápida proporciona una referencia rápida para todos los comandos esenciales, configuraciones y mejores prácticas.

Compare Docker Model Runner y Ollama para LLM local
Correr modelos de lenguaje grandes (LLMs) localmente ha ganado popularidad cada vez mayor por razones de privacidad, control de costos y capacidades fuera de línea. El paisaje cambió significativamente en abril de 2025 cuando Docker introdujo Docker Model Runner (DMR), su solución oficial para la implementación de modelos de IA.

Los chips especializados están haciendo que la inferencia de IA sea más rápida y económica.
El futuro de IA no solo se trata de modelos más inteligentes modelos — se trata de silicio más inteligente.
El hardware especializado para inferencia de LLM está impulsando una revolución similar a la que experimentó la minería de Bitcoin al pasar a ASICs.

Disponibilidad, precios reales en tiendas minoristas en seis países y comparación con Mac Studio.
NVIDIA DGX Spark es real, está a la venta desde el 15 de octubre de 2025 y está dirigido a desarrolladores de CUDA que necesitan trabajo de LLM local con un stack de IA de NVIDIA integrado. El precio de venta al público en EE. UU. es de $3.999; el precio minorista en el Reino Unido/Alemania/Japón es más alto debido al IVA y a los canales de distribución. Los precios públicos en AUD/KRW aún no se han publicado ampliamente.

Integre Ollama con Go: guía del SDK, ejemplos y mejores prácticas para producción.
Este guía proporciona una visión general completa de los disponibles SDKs de Go para Ollama y compara sus conjuntos de características.

Comparando velocidad, parámetros y rendimiento de estos dos modelos
Aquí hay una comparación entre Qwen3:30b y GPT-OSS:20b centrada en el seguimiento de instrucciones y parámetros de rendimiento, especificaciones y velocidad.

No muy agradable.
Los modelos GPT-OSS de Ollama tienen problemas recurrentes al manejar salidas estructuradas, especialmente cuando se usan con marcos como LangChain, OpenAI SDK, vllm y otros.

Un par de formas de obtener salida estructurada de Ollama
Modelos de Lenguaje Grande (LLMs) son poderosos, pero en producción raramente queremos párrafos libres. En su lugar, queremos datos predecibles: atributos, hechos u objetos estructurados que puedas alimentar en una aplicación. Eso es Salida Estructurada de LLM.

Mi propia prueba de programación del modelo ollama
Aquí estoy comparando cómo mucho VRAM la nueva versión de Ollama asigna al modelo con la versión anterior de Ollama. La nueva versión es peor.