Guarda-redes para LLMs na Prática: O Que Realmente Funciona
Controle o risco, não apenas o modelo.
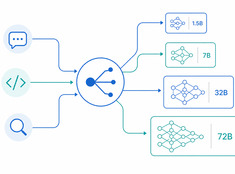
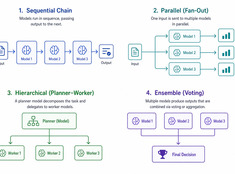
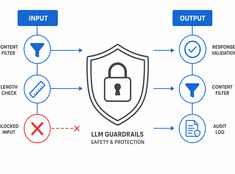
Os LLMs são imprevisíveis. Eles alucinam, vazam dados, geram conteúdo prejudicial ou recusam solicitações legítimas. As barreiras de segurança (guardrails) restringem o comportamento do modelo sem sacrificar a capacidade.