
NVIDIA DGX Spark vs Mac Studio vs RTX-4080: Ollama Performance Comparison
GPT-OSS 120b benchmarks on three AI platforms
I dug up some interesting performance tests of GPT-OSS 120b running on Ollama across three different platforms: NVIDIA DGX Spark, Mac Studio, and RTX 4080. The GPT-OSS 120b model from the Ollama library weighs in at 65GB, which means it doesn’t fit into the 16GB VRAM of an RTX 4080 (or the newer RTX 5080).
Yes, the model can run with partial offloading to CPU, and if you have 64GB of system RAM (like I do), you can try it out. However, this setup would not be considered anywhere close to production-ready performance. For truly demanding workloads, you might need something like the NVIDIA DGX Spark, which is designed specifically for high-capacity AI workloads. For more on LLM performance—throughput vs latency, VRAM limits, and benchmarks across runtimes and hardware—see LLM Performance: Benchmarks, Bottlenecks & Optimization.

I expected this LLM would benefit significantly from running on a “high-RAM AI device” like the DGX Spark. While the results are good, they’re not as dramatically better as you might expect given the price difference between DGX Spark and more affordable options.
TL;DR
Ollama running GPT-OSS 120b performance comparison across three platforms:
| Device | Prompt Eval Performance (tokens/sec) | Generation Performance (tokens/sec) | Notes |
|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | Best overall performance, fully GPU-accelerated |
| Mac Studio | Unknown | 34 → 6 | One Test showed degradation with context size increase |
| RTX 4080 | 969 | 12.45 | 78% CPU / 22% GPU split due to VRAM limits |
Model specifications:
- Model: GPT-OSS 120b
- Parameters: 117B (Mixture-of-Experts architecture)
- Active parameters per pass: 5.1B
- Quantization: MXFP4
- Model size: 65GB
This is similar in architecture to other MoE models like Qwen3:30b, but at a much larger scale.
GPT-OSS 120b on NVIDIA DGX Spark
The LLM performance data for NVIDIA DGX Spark comes from the official Ollama blog post (linked below in the Useful Links section). The DGX Spark represents NVIDIA’s entry into the personal AI supercomputer market, featuring 128GB of unified memory specifically designed for running large language models.

GPT-OSS 120b’s performance looks impressive at 41 tokens/sec for generation. This makes it the clear winner for this particular model, showing that the extra memory capacity can make a real difference for extremely large models.
However, the medium-to-large LLMs performance doesn’t look as compelling. This is particularly noticeable with Qwen3:32b and Llama3.1:70b—exactly the models where you’d expect the high RAM capacity to shine. The performance on DGX Spark for these models isn’t inspiring when compared to the price premium. If you’re primarily working with models in the 30-70B parameter range, you might want to consider alternatives like a well-configured workstation) or even a Quadro RTX 5880 Ada with its 48GB of VRAM.
GPT-OSS 120b on Mac Studio Max
The Slinging Bits YouTube channel conducted comprehensive tests running GPT-OSS 120b on Ollama with varying context sizes. The results reveal a significant performance concern: the model’s generation speed dropped dramatically from 34 tokens/s to just 6 tokens/s as the context size increased.
This performance degradation is likely due to memory pressure and how macOS manages the unified memory architecture. While Mac Studio Max has impressive unified memory (up to 192GB in the M2 Ultra configuration), the way it handles very large models under increasing context loads differs significantly from dedicated GPU VRAM.


For applications requiring consistent performance across varying context lengths, this makes Mac Studio less ideal for GPT-OSS 120b, despite its otherwise excellent capabilities for AI workloads. You might have better luck with smaller models or consider using Ollama’s parallel request handling features to maximize throughput in production scenarios.
GPT-OSS 120b on RTX 4080
I initially thought running Ollama with GPT-OSS 120b on my consumer PC wouldn’t be particularly exciting, but the results pleasantly surprised me. Here’s what happened when I tested it with this query:
$ ollama run gpt-oss:120b --verbose Compare the weather in state capitals of Australia
Thinking...
We need to compare weather in state capitals of Australia. Provide a comparison, perhaps include
...
*All data accessed September 2024; any updates from the BOM after that date may slightly adjust the
numbers, but the broad patterns remain unchanged.*
total duration: 4m39.942105769s
load duration: 75.843974ms
prompt eval count: 75 token(s)
prompt eval duration: 77.341981ms
prompt eval rate: 969.72 tokens/s
eval count: 3483 token(s)
eval duration: 4m39.788119563s
eval rate: 12.45 tokens/s
Now here’s the interesting part—Ollama with this LLM was running mostly on CPU! The model simply doesn’t fit in the 16GB VRAM, so Ollama intelligently offloaded most of it to system RAM. You can see this behavior using the ollama ps command:
$ ollama ps
NAME ID SIZE PROCESSOR CONTEXT
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
Despite running with a 78% CPU / 22% GPU split, the RTX 4080 still delivers respectable performance for a model this size. The prompt evaluation is blazingly fast at 969 tokens/s, and even the generation speed of 12.45 tokens/s is usable for many applications.
This is particularly impressive when you consider that:
- The model is nearly 4x larger than the available VRAM
- Most of the computation happens on CPU (which benefits from my 64GB of system RAM)
- Understanding how Ollama uses CPU cores can help optimize this setup further
Who would have thought a consumer GPU could handle a 117B parameter model at all, let alone with usable performance? This demonstrates the power of Ollama’s intelligent memory management and the importance of having sufficient system RAM. If you’re interested in integrating Ollama into your applications, check out this guide on using Ollama with Python.
Note: While this works for experimentation and testing, you’ll notice GPT-OSS can have some quirks, particularly with structured output formats.
To explore more benchmarks, VRAM and CPU offloading trade-offs, and performance tuning across platforms, check our LLM Performance: Benchmarks, Bottlenecks & Optimization hub.
Primary Sources
- Ollama on NVIDIA DGX Spark: Performance Benchmarks - Official Ollama blog post with comprehensive DGX Spark performance data
- GPT-OSS 120B on Mac Studio - Slinging Bits YouTube - Detailed video testing GPT-OSS 120b with varying context sizes
Related Reading on Hardware Comparison and Ollama
- DGX Spark vs. Mac Studio: A Practical, Price-Checked Look at NVIDIA’s Personal AI Supercomputer - Detailed explanation of DGX Spark configs, global pricing, and direct comparison with Mac Studio for local AI work
- NVIDIA DGX Spark - Anticipation - Early coverage of DGX Spark: availability, pricing, and technical specifications
- NVidia RTX 5080 and RTX 5090 prices in Australia - October 2025 - Current market pricing for next-gen consumer GPUs
- Is the Quadro RTX 5880 Ada 48GB Any Good? - Review of the 48GB workstation GPU alternative for AI workloads
- Ollama cheatsheet - Comprehensive command reference and tips for Ollama
P.S. New Data
Already after I had published this post I found on NVIDIA site some more statistics on LLM Inferrence on DGX Spark:
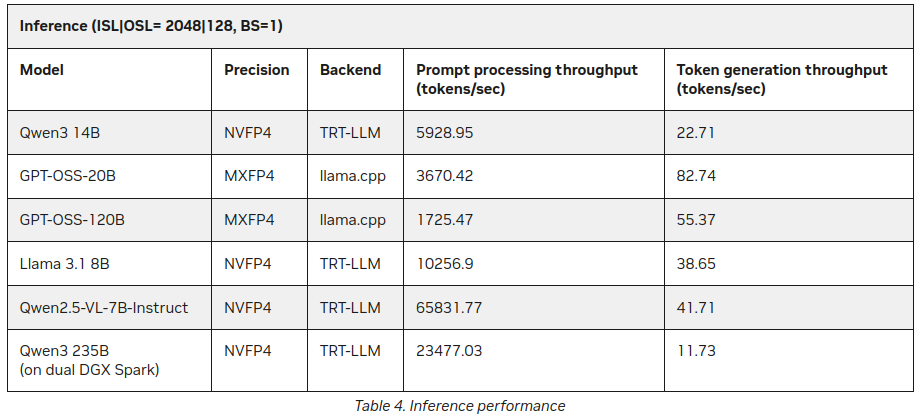
Better, but not contracicting much to said above (55 tokens vs 41) but it is an interesting addition, especially about Qwen3 235B (on dual DGX Spark) producing 11+ tokens/second
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
