Automação de Navegadores em Go: Selenium, chromedp, Playwright, ZenRows
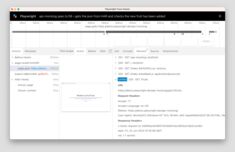
Selenium, chromedp, Playwright, ZenRows - em Go.
A escolha da pilha de automação de navegador e raspagem web em Go [{< ref “.” >} “browser automation stack and webscraping in Go”) afeta a velocidade, a manutenção e onde seu código é executado.