

llama.cpp を使用した 16GB VRAM における LLM ベンチマーク(速度とコンテキスト)
16GB VRAM における llama.cpp のトークン生成速度(表)。
ここでは、16GB の VRAM を持つ GPU で動作するいくつかの LLM の速度を比較し、セルフホスティングに適した最適なモデルを選定しています。
16GB VRAM における llama.cpp のトークン生成速度(表)。
ここでは、16GB の VRAM を持つ GPU で動作するいくつかの LLM の速度を比較し、セルフホスティングに適した最適なモデルを選定しています。

オーストラリアではRTX 5090は供給不足であり、価格が高騰しています。
オーストラリアにはRTX 5090の在庫があります。 ただし、ごくわずかです。 もし見つけたとしても、現実感の欠けた、莫大なプレミアム価格を支払わなければなりません。

GPU および永続性を備えた Compose ファーストの Ollama サーバー。
Ollama は、メタル(物理マシン)上で非常に良好に動作します。それをサービスとして扱うと、さらに興味深くなります。安定したエンドポイント、固定されたバージョン、永続的なストレージ、そして GPU が利用可能か不可かの明確な状態が確保されます。

RTX 4080(16GB VRAM)でのLLM速度テスト
大規模言語モデルをローカルで実行すると、プライバシーの確保、オフラインでの使用が可能になり、APIコストはゼロになります。このベンチマークでは、RTX 4080上で動作する14のポピュラーなLLMs on Ollamaから期待できる性能が明らかになります。
正しいターミナルを選んでLinuxワークフローを最適化しましょう
Linuxユーザーにとって最も重要なツールの一つは、端末エミュレータです。https://www.glukhov.org/ja/developer-tools/terminals-shell/terminal-emulators-for-linux-comparison/ “Linux端末エミュレータ比較”

オーストラリアの小売業者から、リアルなオーストラリアドルでの価格を今すぐ。
NVIDIA DGX Spark (GB10 Grace Blackwell) は、主要な PC 小売店に国内在庫があり、オーストラリアで入手可能 となっています。 世界的な DGX Spark の価格と入手性 を追いかけていただいている方なら、オーストラリアでの価格帯はストレージ構成や小売店によって 6,249 オーストラリアドルから 7,999 オーストラリアドル であることが、ご関心をお持ちいただけるでしょう。

AI 向けコンシューマー GPU の価格 - RTX 5080 と RTX 5090
特に大規模言語モデル(LLM)向け、そして AI 全般に適した、トピレベルの消費者用 GPU の価格を比較してみましょう。 具体的には、RTX-5080 と RTX-5090 の価格 に注目しています。

テキスト、画像、音声を共有された埋め込み空間に統一する
クロスモーダル埋め込みは、人工知能において画期的な進展をもたらし、統一された表現空間内で異なるデータタイプ間の理解と推論を可能にします。

オープンモデルを活用して、予算内のハードウェアでエンタープライズAIをデプロイする
AI の民主化はここにやってきました。 Llama、Mistral、Qwen などのオープンソース大規模言語モデル(LLM)が現在、プロプライエタリなモデルと競合するレベルに達しており、チームは 消費级ハードウェアを使用した AI インフラストラクチャ を構築することで、コストを削減しながらもデータプライバシーとデプロイの完全な制御を維持することが可能になりました。

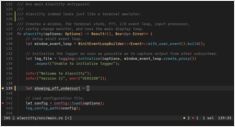
Docker Model Runnerでコンテキストサイズを設定する際の回避策
Docker Model Runnerにおけるコンテキストサイズの設定は、本来よりも複雑です。

テキスト指示を使って画像を拡張するためのAIモデル
ブラックフォレスト・ラボズは、FLUX.1-Kontext-devという高度な画像から画像へのAIモデルをリリースしました。このモデルは、テキストの指示を使って既存の画像を補強します。

NVIDIA CUDAをサポートしたDocker Model RunnerでGPU加速を有効にする
Docker Model Runner は、Dockerが公式に提供するローカルでAIモデルを実行するためのツールですが、
Docker Model RunnerにおけるNVidia GPUの加速の有効化 には特定の設定が必要です。

GPT-OSS 120bの3つのAIプラットフォームにおけるベンチマーク
私は、Ollama上でGPT-OSS 120bのパフォーマンステストを3つの異なるプラットフォームで確認しました:NVIDIA DGX Spark, Mac Studio, and RTX 4080。OllamaライブラリのGPT-OSS 120bモデルは65GBあり、これはRTX 4080(または新しいRTX 5080の16GB VRAMには収まらないことを意味します。

Docker Model Runner コマンドのクイックリファレンス
Docker Model Runner (DMR) は、2025年4月に導入された Docker の公式ソリューションで、AIモデルをローカルで実行するためのものです。このチートシートでは、すべての必須コマンド、構成、およびベストプラクティスのクイックリファレンスを提供しています。

Docker Model RunnerとOllamaを比較してみる:ローカルLLM向け
ローカルで大規模言語モデル(LLM)を実行する は、プライバシー、コスト管理、オフライン機能のためにますます人気になってきています。 2025年4月にDockerが**Docker Model Runner (DMR)**を導入し、AIモデルの展開用の公式ソリューションとして登場したことで、状況は大きく変わりました。

6 カ国における実勢価格、Mac Studio との比較、および入手可能性について。
NVIDIA DGX Spark は実在する製品で、2025 年 10 月 15 日から販売開始されます。統合された NVIDIA AI スタック を利用して、ローカルでの LLM 作業 が必要な CUDA 開発者を主なターゲットとしています。米国での MSRP は 3,999 ドル です。英国・ドイツ・日本 での小売価格は、VAT(消費税)や流通チャネルの事情により高くなります。オーストラリアドル (AUD) や韓国ウォン (KRW) の公開価格はまだ広く発表されていません。