
NVIDIA DGX Spark vs Mac Studio vs RTX-4080: Confronto delle prestazioni di Ollama
Benchmark GPT-OSS 120b su tre piattaforme AI
Ho trovato alcuni interessanti test sulle prestazioni di GPT-OSS 120b in esecuzione su Ollama su tre diversi piattaforme: NVIDIA DGX Spark, Mac Studio, e RTX 4080. Il modello GPT-OSS 120b dalla libreria Ollama pesa 65 GB, il che significa che non si adatta alla VRAM da 16 GB di un RTX 4080 (o al più recente RTX 5080).
Sì, il modello può essere eseguito con un offloading parziale sulla CPU, e se hai 64 GB di RAM del sistema (come ho io), puoi provarlo. Tuttavia, questa configurazione non sarebbe considerata affatto vicina alle prestazioni necessarie per un ambiente di produzione. Per carichi di lavoro davvero impegnativi, potresti aver bisogno di qualcosa come il NVIDIA DGX Spark, che è stato progettato specificamente per carichi di lavoro AI ad alta capacità. Per ulteriori informazioni sulle prestazioni degli LLM—throughput vs latenza, limiti di VRAM e benchmark su diversi runtimes e hardware—vedi Prestazioni degli LLM: Benchmark, Colli di bottiglia & Ottimizzazione.

Avevo previsto che questo LLM potesse beneficiare significativamente dall’essere eseguito su un “dispositivo ad alta capacità di RAM” come il DGX Spark. Sebbene i risultati siano buoni, non sono così nettamente migliori come potresti aspettarti considerando la differenza di prezzo tra DGX Spark e opzioni più economiche.
TL;DR
Ollama in esecuzione su GPT-OSS 120b confronto delle prestazioni su tre piattaforme:
| Dispositivo | Prestazioni di valutazione del prompt (token/sec) | Prestazioni di generazione (token/sec) | Note | |
|---|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | Prestazioni complessive migliori, completamente accelerato dalla GPU | |
| Mac Studio | Sconosciuto | 34 → 6 | Un test ha mostrato un peggioramento con l’aumento della dimensione del contesto | |
| RTX 4080 | 969 | 12,45 | Divisione 78% CPU / 22% GPU a causa dei limiti di VRAM |
Specifiche del modello:
- Modello: GPT-OSS 120b
- Parametri: 117B (architettura Mixture-of-Experts)
- Parametri attivi per passata: 5,1B
- Quantizzazione: MXFP4
- Dimensione del modello: 65 GB
Questo è simile ad altre architetture MoE come Qwen3:30b, ma su una scala molto maggiore.
GPT-OSS 120b su NVIDIA DGX Spark
I dati sulle prestazioni del modello LLM su NVIDIA DGX Spark provengono dal post ufficiale del blog Ollama (vedi di seguito nella sezione Link utili). Il DGX Spark rappresenta l’ingresso di NVIDIA nel mercato dei supercomputer personali per l’AI, con 128 GB di memoria unificata specificamente progettata per l’esecuzione di modelli linguistici di grandi dimensioni.

Le prestazioni di GPT-OSS 120b sembrano impressionanti, con una velocità di generazione di 41 token/sec. Questo lo rende chiaramente il vincitore per questo modello specifico, dimostrando che la capacità aggiuntiva di memoria può davvero fare la differenza per modelli estremamente grandi.
Tuttavia, le prestazioni dei modelli LLM di dimensioni medio-grandi non sembrano così convincenti. Questo è particolarmente evidente con Qwen3:32b e Llama3.1:70b—esattamente i modelli in cui ti aspetteresti che la capacità di RAM elevata brillasse. Le prestazioni su DGX Spark per questi modelli non sono particolarmente ispiratrici quando si confrontano con il premio di prezzo. Se stai principalmente lavorando con modelli nella gamma di parametri da 30 a 70B, potresti voler considerare alternative come un workstation ben configurato o anche un Quadro RTX 5880 Ada con i suoi 48 GB di VRAM.
GPT-OSS 120b su Mac Studio Max
Il canale YouTube Slinging Bits ha condotto test completi sull’esecuzione di GPT-OSS 120b su Ollama con dimensioni di contesto variabili. I risultati rivelano un problema significativo di prestazioni: la velocità di generazione del modello è calata drasticamente da 34 token/s a soli 6 token/s con l’aumento della dimensione del contesto.
Questo peggioramento delle prestazioni è probabilmente dovuto alla pressione sulla memoria e a come macOS gestisce l’architettura della memoria unificata. Sebbene il Mac Studio Max abbia una memoria unificata impressionante (fino a 192 GB nella configurazione M2 Ultra), il modo in cui gestisce modelli molto grandi sotto carichi di contesto crescenti differisce in modo significativo dalla VRAM dedicata della GPU.


Per applicazioni che richiedono prestazioni costanti su lunghezze di contesto variabili, questo rende il Mac Studio meno ideale per GPT-OSS 120b, nonostante le sue capacità eccellenti per i carichi di lavoro di AI. Potresti ottenere maggiori risultati con modelli più piccoli o considerare l’uso delle funzionalità di gestione delle richieste parallele di Ollama per massimizzare il throughput in scenari di produzione.
GPT-OSS 120b su RTX 4080
All’inizio pensavo che eseguire Ollama con GPT-OSS 120b sul mio PC consumer non sarebbe stato particolarmente eccitante, ma i risultati mi hanno sorpreso positivamente. Ecco cosa è successo quando l’ho testato con questa query:
$ ollama run gpt-oss:120b --verbose Confronta il clima nelle capitali degli stati dell'Australia
Sto pensando...
Dobbiamo confrontare il clima nelle capitali degli stati dell'Australia. Fornisci un confronto, potresti includere
...
*Tutti i dati accessibili a settembre 2024; eventuali aggiornamenti del BOM successivi a questa data potrebbero leggermente modificare i
numeri, ma i pattern generali rimangono invariati.*
durata totale: 4m39.942105769s
durata di caricamento: 75.843974ms
contatore di valutazione del prompt: 75 token
durata di valutazione del prompt: 77.341981ms
velocità di valutazione del prompt: 969.72 token/s
contatore di valutazione: 3483 token
durata di valutazione: 4m39.788119563s
velocità di valutazione: 12.45 token/s
Ora ecco la parte interessante—Ollama con questo LLM stava eseguendo quasi interamente sulla CPU! Il modello semplicemente non si adatta alla VRAM da 16 GB, quindi Ollama ha intelligente offloaded la maggior parte di esso alla RAM del sistema. Puoi vedere questo comportamento utilizzando il comando ollama ps:
$ ollama ps
NOME ID DIMENSIONE PROCESSORE CONTESTO
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
Nonostante il 78% CPU / 22% GPU, l’RTX 4080 comunque fornisce prestazioni rispettabili per un modello di questa dimensione. La valutazione del prompt è estremamente veloce a 969 token/s, e anche la velocità di generazione di 12,45 token/s è utilizzabile per molte applicazioni.
Questo è particolarmente impressionante considerando che:
- Il modello è quasi 4 volte più grande della VRAM disponibile
- La maggior parte del calcolo avviene sulla CPU (che beneficia della mia RAM del sistema da 64 GB)
- Capire come Ollama utilizza i core della CPU può aiutare a ottimizzare ulteriormente questa configurazione
Chi avrebbe mai pensato che una GPU consumer potesse gestire un modello con 117B parametri, figuriamoci con prestazioni utilizzabili? Questo dimostra il potere della gestione intelligente della memoria di Ollama e l’importanza di disporre di una sufficiente RAM del sistema. Se sei interessato all’integrazione di Ollama nelle tue applicazioni, consulta questa guida su l’utilizzo di Ollama con Python.
Nota: Sebbene questo funzioni per sperimentazione e test, noterai che GPT-OSS può avere alcuni inconvenienti, in particolare con i formati di output strutturati.
Per esplorare ulteriori benchmark, i compromessi tra offloading VRAM e CPU, e l’ottimizzazione delle prestazioni su diversi piattaforme, consulta il nostro LLM Performance: Benchmarks, Bottlenecks & Optimization hub.
Fonti principali
- Ollama su NVIDIA DGX Spark: Benchmark sulle Prestazioni - Post ufficiale del blog Ollama con dati completi sulle prestazioni del DGX Spark
- GPT-OSS 120B su Mac Studio - Canale YouTube Slinging Bits - Video dettagliato che testa GPT-OSS 120b con dimensioni di contesto variabili
Lettura correlata su confronto hardware e Ollama
- DGX Spark vs. Mac Studio: Una panoramica pratica, con verifica dei prezzi, su NVIDIA’s Personal AI Supercomputer - Spiegazione dettagliata delle configurazioni DGX Spark, prezzi globali e confronto diretto con Mac Studio per il lavoro locale sull’AI
- NVIDIA DGX Spark - Anticipazioni - Copertura iniziale del DGX Spark: disponibilità, prezzi e specifiche tecniche
- Prezzi di NVidia RTX 5080 e RTX 5090 in Australia - Ottobre 2025 - Prezzi attuali del mercato per le nuove GPU consumer
- Il Quadro RTX 5880 Ada 48GB è buono? - Recensione della GPU da 48 GB per lavoro sull’AI
- Ollama cheatsheet - Riferimento completo ai comandi e suggerimenti per Ollama
P.S. Nuovi dati
Già dopo aver pubblicato questo post, ho trovato sul sito NVIDIA alcune statistiche aggiuntive sull’inferenza degli LLM su DGX Spark:
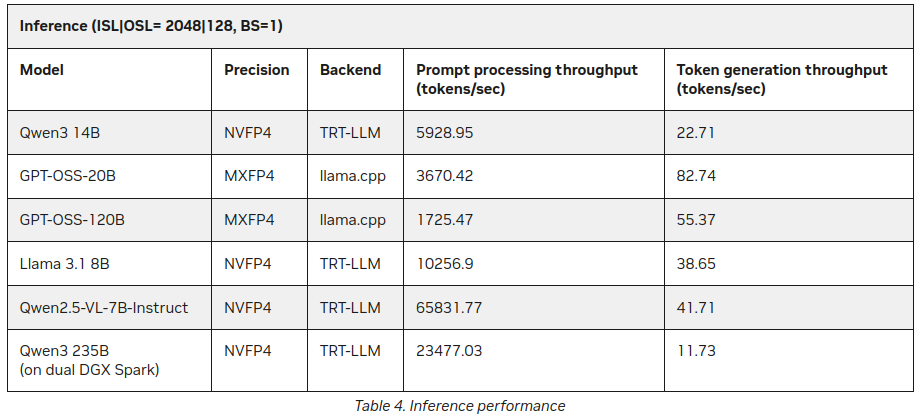
Migliore, ma non contraddittoria rispetto a quanto detto sopra (55 token vs 41), ma è un’aggiunta interessante, soprattutto riguardo a Qwen3 235B (su dual DGX Spark) che produce 11+ token al secondo
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
