
NVIDIA DGX Spark vs Mac Studio vs RTX-4080: Comparación del rendimiento de Ollama
Resultados de benchmarks de GPT-OSS 120b en tres plataformas de IA
Investigué algunos interesantes tests de rendimiento del modelo GPT-OSS 120b ejecutándose en Ollama en tres plataformas diferentes: NVIDIA DGX Spark, Mac Studio y RTX 4080. El modelo GPT-OSS 120b del repositorio Ollama tiene un tamaño de 65GB, lo que significa que no cabe en los 16GB de VRAM de un RTX 4080 (ni en el más reciente RTX 5080).
Sí, el modelo puede ejecutarse con un desalojo parcial a la CPU, y si tienes 64GB de RAM del sistema (como yo), puedes probarlo. Sin embargo, esta configuración no se consideraría en absoluto como apta para producción. Para cargas de trabajo realmente exigentes, podrías necesitar algo como el NVIDIA DGX Spark, que está diseñado específicamente para cargas de trabajo de IA de alta capacidad. Para más información sobre el rendimiento de los LLM —rendimiento de throughput versus latencia, límites de VRAM y benchmarks a través de runtimes y hardware— véase Rendimiento de LLM: Benchmarks, Cuellos de Botella y Optimización.

Me esperaba que este LLM beneficiara significativamente de ejecutarse en un dispositivo “de alta RAM para IA” como el DGX Spark. Aunque los resultados son buenos, no son tan notablemente mejores como podrías esperar dado el diferencial de precios entre DGX Spark y opciones más económicas.
TL;DR
Ollama ejecutando GPT-OSS 120b comparación de rendimiento en tres plataformas:
| Dispositivo | Rendimiento de Evaluación de Prompt (tokens/segundo) | Rendimiento de Generación (tokens/segundo) | Notas | |
|---|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | Mejor rendimiento general, totalmente acelerado por GPU | |
| Mac Studio | Desconocido | 34 → 6 | Un test mostró degradación con el aumento del tamaño de contexto | |
| RTX 4080 | 969 | 12.45 | 78% CPU / 22% GPU debido a límites de VRAM |
Especificaciones del modelo:
- Modelo: GPT-OSS 120b
- Parámetros: 117B (arquitectura Mixture-of-Experts)
- Parámetros activos por paso: 5.1B
- Cuantización: MXFP4
- Tamaño del modelo: 65GB
Esta arquitectura es similar a otras modelos MoE como Qwen3:30b, pero a una escala mucho mayor.
GPT-OSS 120b en NVIDIA DGX Spark
Los datos de rendimiento del LLM para NVIDIA DGX Spark provienen de la entrada oficial del blog de Ollama (enlazada más abajo en la sección de enlaces útiles). El DGX Spark representa la entrada de NVIDIA en el mercado de los superordenadores personales para IA, con 128GB de memoria unificada especialmente diseñada para ejecutar modelos de lenguaje grandes.

El rendimiento de GPT-OSS 120b parece impresionante con 41 tokens/segundo para la generación. Esto lo convierte claramente en el ganador para este modelo específico, mostrando que la capacidad adicional de memoria puede hacer una diferencia real para modelos extremadamente grandes.
Sin embargo, el rendimiento de los LLMs medianos a grandes no parece tan atractivo. Esto es especialmente notable con Qwen3:32b y Llama3.1:70b —exactamente los modelos donde te esperarías que la alta capacidad de RAM brillara. El rendimiento en DGX Spark para estos modelos no es inspirador comparado con el premium de precio. Si estás trabajando principalmente con modelos en el rango de 30-70B de parámetros, quizás quieras considerar alternativas como una estación de trabajo bien configurada o incluso un Quadro RTX 5880 Ada con sus 48GB de VRAM.
GPT-OSS 120b en Mac Studio Max
El canal de YouTube Slinging Bits realizó pruebas exhaustivas ejecutando GPT-OSS 120b en Ollama con tamaños de contexto variables. Los resultados revelan una preocupación significativa de rendimiento: la velocidad de generación del modelo cayó drásticamente de 34 tokens/s a solo 6 tokens/s a medida que aumentaba el tamaño del contexto.
Esta degradación de rendimiento probablemente se debe a la presión de memoria y a cómo macOS maneja la arquitectura de memoria unificada. Aunque el Mac Studio Max tiene una memoria unificada impresionante (hasta 192GB en la configuración M2 Ultra), la forma en que maneja modelos muy grandes bajo cargas de contexto crecientes difiere significativamente de la VRAM dedicada de la GPU.


Para aplicaciones que requieren un rendimiento consistente en diferentes longitudes de contexto, esto hace que el Mac Studio sea menos ideal para GPT-OSS 120b, a pesar de sus capacidades excelentes en general para cargas de trabajo de IA. Podrías tener más suerte con modelos más pequeños o considerar usar funciones de manejo de solicitudes paralelas de Ollama para maximizar el throughput en escenarios de producción.
GPT-OSS 120b en RTX 4080
Inicialmente creía que ejecutar Ollama con GPT-OSS 120b en mi PC de consumo no sería particularmente emocionante, pero los resultados me sorprendieron agradablemente. Aquí está lo que sucedió cuando realicé la prueba con esta consulta:
$ ollama run gpt-oss:120b --verbose Compare the weather in state capitals of Australia
Thinking...
We need to compare weather in state capitals of Australia. Provide a comparison, perhaps include
...
*All data accessed September 2024; any updates from the BOM after that date may slightly adjust the
numbers, but the broad patterns remain unchanged.*
total duration: 4m39.942105769s
load duration: 75.843974ms
prompt eval count: 75 token(s)
prompt eval duration: 77.341981ms
prompt eval rate: 969.72 tokens/s
eval count: 3483 token(s)
eval duration: 4m39.788119563s
eval rate: 12.45 tokens/s
Aquí está lo interesante—Ollama con este LLM estaba ejecutándose principalmente en la CPU! El modelo simplemente no cabe en los 16GB de VRAM, por lo que Ollama desalojó inteligentemente la mayor parte a la memoria RAM del sistema. Puedes ver este comportamiento usando el comando ollama ps:
$ ollama ps
NAME ID SIZE PROCESSOR CONTEXT
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
A pesar de ejecutarse con una división de 78% CPU / 22% GPU, el RTX 4080 aún entrega un rendimiento respetable para un modelo de este tamaño. La evaluación del prompt es increíblemente rápida a 969 tokens/s, y incluso la velocidad de generación de 12.45 tokens/s es útil para muchas aplicaciones.
Esto es particularmente impresionante al considerar que:
- El modelo es casi 4 veces más grande que la VRAM disponible
- La mayor parte del cálculo ocurre en la CPU (lo cual beneficia de mis 64GB de RAM del sistema)
- Entender cómo Ollama usa los núcleos de CPU puede ayudar a optimizar esta configuración aún más
¿Quién habría pensado que una GPU de consumo podría manejar un modelo de 117B de parámetros en absoluto, y aún más con un rendimiento útil? Esto demuestra el poder del manejo inteligente de memoria de Ollama y la importancia de tener suficiente RAM del sistema. Si estás interesado en integrar Ollama en tus aplicaciones, consulta esta guía sobre usar Ollama con Python.
Nota: Aunque esto funciona para experimentación y pruebas, notarás que GPT-OSS puede tener algunos problemas, especialmente con formatos de salida estructurados.
Para explorar más benchmarks, trade-offs entre VRAM y desalojo a CPU, y ajuste de rendimiento en diferentes plataformas, consulta nuestro Rendimiento de LLM: Benchmarks, Cuellos de Botella y Optimización.
Fuentes primarias
- Ollama en NVIDIA DGX Spark: Benchmarks de Rendimiento - Entrada oficial del blog de Ollama con datos completos de rendimiento en DGX Spark
- GPT-OSS 120B en Mac Studio - Canal de YouTube Slinging Bits - Video detallado probando GPT-OSS 120b con diferentes tamaños de contexto
Lecturas relacionadas sobre comparación de hardware y Ollama
- DGX Spark vs. Mac Studio: Una mirada práctica y con precios revisados sobre el superordenador personal de NVIDIA - Explicación detallada de configuraciones DGX Spark, precios globales y comparación directa con Mac Studio para trabajo local de IA
- NVIDIA DGX Spark - Anticipación - Cobertura temprana del DGX Spark: disponibilidad, precios y especificaciones técnicas
- Precios de NVidia RTX 5080 y RTX 5090 en Australia - Octubre 2025 - Precios actuales del mercado para las nuevas GPU de consumo
- ¿El Quadro RTX 5880 Ada 48GB es útil? - Revisión de la alternativa de GPU de 48GB para cargas de trabajo de IA
- Ollama cheatsheet - Referencia completa de comandos y consejos para Ollama
P.D. Nuevos datos
Ya después de haber publicado este post encontré en el sitio de NVIDIA algunas estadísticas adicionales sobre la inferencia de LLM en DGX Spark:
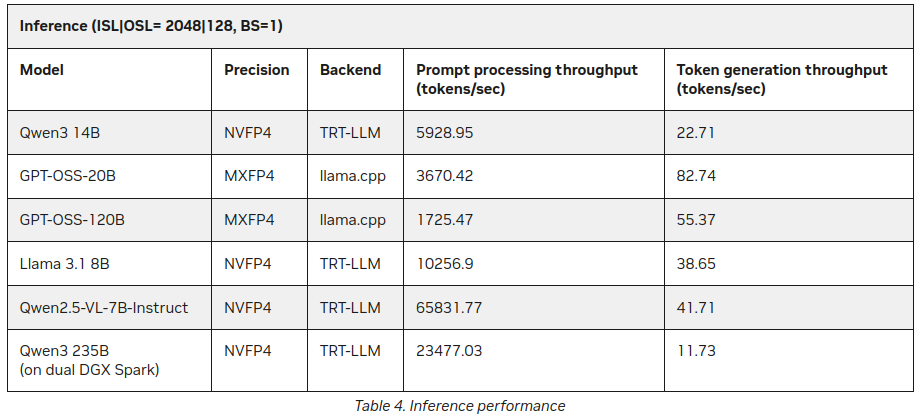
Mejor, pero no contradiciendo mucho lo dicho anteriormente (55 tokens vs 41), pero es una interesante adición, especialmente sobre Qwen3 235B (en doble DGX Spark) produciendo 11+ tokens por segundo
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
