
Choosing best LLM for Perplexica
Testing how Perplexica performs with various LLMs running on local Ollama: Llama3, Llama3.1, Hermes 3, Mistral Nemo, Mistral Large, Gemma 2, Qwen2, Phi 3 and Command-r of various quants and selecting The best LLM for Perplexica

Need to mention right away that it’s not a test and comparison of the models alone, it’s a test of their performance in combination with Perplexica. And as you might expect,
- the Perplexica prompts and LLM call parameters like temperature and seed can change
- the SearxNG search results can change
- ollama model can be updated
Though it might be not definitive test, still could give you impression what to expect from different models when they are used with Perplexica.
TL;DR
The best models are Mistral Nemo 12b, both quantisations Q6 and Q8 showed excellent results. Just not producing the follow up buttons and printing sources inside. Hopefully this will be fixed in some next of Perplexica releases. These models shared first place with qwen2-72b-instruct-q4_1. But this model is much larger, ~45GB, so be careful.
Second is to command-r-35b-v0.1-q2_K, qwen2-7b-instruct-q8_0, qwen2-72b-instruct-q2_K (be carefull, this one will not fit into 16GB VRAM) and mistral-large-122b-instruct-2407-q3_K_S (the largest of them all).
Third is to llama3.1:8b-instruct-q4_0, hermes3-8b-llama3.1-q8_0 (llama3.1 based), llama3.1-70b-instruct-q2_K (this one is big too) and llama3.1-70b-instruct-q3_K_S (and this one too) llama3.1-70b-instruct-q4_0 (don’t let me start on this one’s size).
Claude 3.5 sonnet and Claude 3 haiku are not participating in the comparison, because they are not self-hosted, but I give you their results anyway, decide for yourselves.
The result table, models are listed alphabetically:
| Model name, params, quant | q1 | q2 | q3 | Total | Place |
|---|---|---|---|---|---|
| claude 3 haiku | 0 | 2 | 0 | 2 | |
| claude 3.5 sonnet | 2 | 2 | 2 | 6 | not selfhosted |
| command-r-35b-v0.1-q2_K | 2 | 2 | 1 | 5 | 2 |
| command-r-35b-v0.1-q3_K_S | 0 | 1 | 0 | 1 | |
| gemma2-9b-instruct-q8_0 | 0 | 0 | 0 | 0 | |
| gemma2-27b-instruct-q3_K_S | 1 | 0 | 0 | 1 | |
| hermes3-8b-llama3.1-q8_0 | 1 | 1 | 2 | 4 | 3 |
| llama3:8b-instruct-q4_0 | 1 | 0 | 0 | 1 | |
| llama3.1:8b-instruct-q4_0 | 1 | 2 | 1 | 4 | 3 |
| llama3.1:8b-instruct-q6_K | 1 | 2 | 0 | 3 | |
| llama3.1-8b-instruct-q8_0 | 1 | 1 | 1 | 3 | |
| llama3.1-70b-instruct-q2_K | 2 | 1 | 1 | 4 | 3 |
| llama3.1-70b-instruct-q3_K_S | 2 | 1 | 1 | 4 | 3 |
| llama3.1-70b-instruct-q4_0 | 2 | 2 | 0 | 4 | 3 |
| mistral-nemo-12b-instruct-2407-q6_K | 2 | 2 | 2 | 6 | 1 |
| mistral-nemo-12b-instruct-2407-q8_0 | 2 | 2 | 2 | 6 | 1 |
| mistral-large-122b-instruct-2407-q3_K_S | 2 | 2 | 1 | 5 | 2 |
| mixtral-8x7b-instruct-v0.1-q3_K_M | 1 | 2 | 1 | 4 | 3 |
| mixtral-8x7b-instruct-v0.1-q5_1 | 1 | 1 | 0 | 2 | |
| phi3-14b-medium-128k-instruct-q6_K | 1 | 1 | 1 | 3 | |
| qwen2-7b-instruct-q8_0 | 2 | 2 | 1 | 5 | 2 |
| qwen2-72b-instruct-q2_K | 1 | 2 | 2 | 5 | 2 |
| qwen2-72b-instruct-q3_K_S | 1 | 2 | 0 | 3 | |
| qwen2-72b-instruct-q4_1 | 2 | 2 | 2 | 6 | 1 |
Surprisingly Gemma 2 didn’t go well in this test at all.
TL;DR means “Too long; didn’t read” if anyone is curious.
What we test
Perplexica is a self-hosted alternative to Copilot, Perplexity.ai and similar services that do minimum three-step job
- Run user query on at least one search engine
- Download and filter search results
- Combine results together and summarize
How we test
We are running local Perplexica with different chat models, but the same embeddings model - nomic-embed-text:137m-v1.5-fp16. This embedding model will improve Perplexica response with every chat model, comparing to standard BGE/GTE small or Bert multilingual.
In this test with each chat model we are asking Perplexica three questions
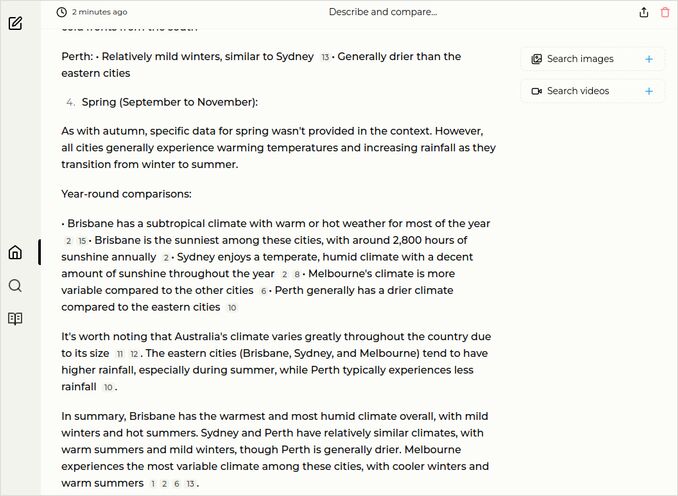
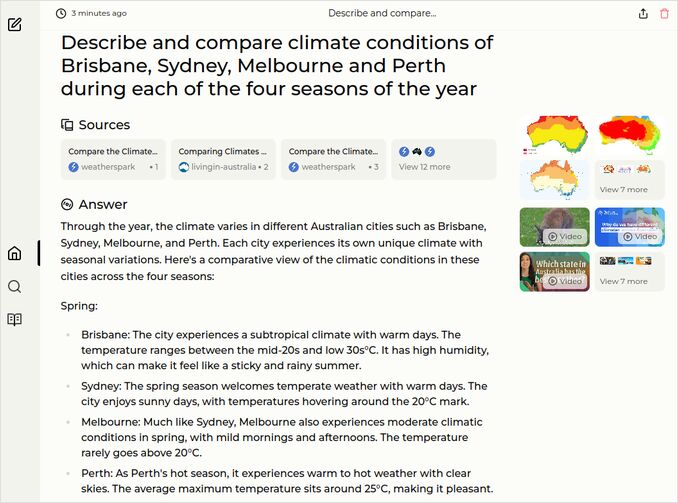
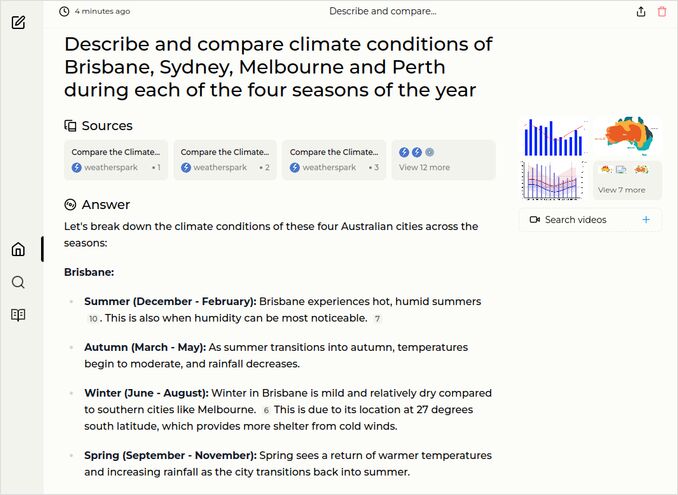
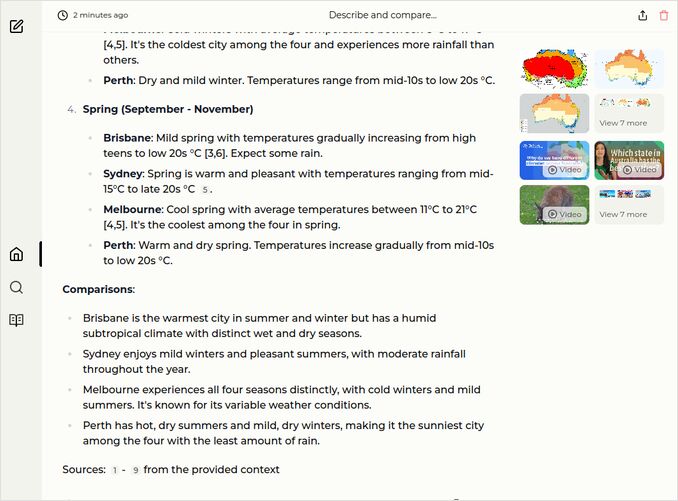
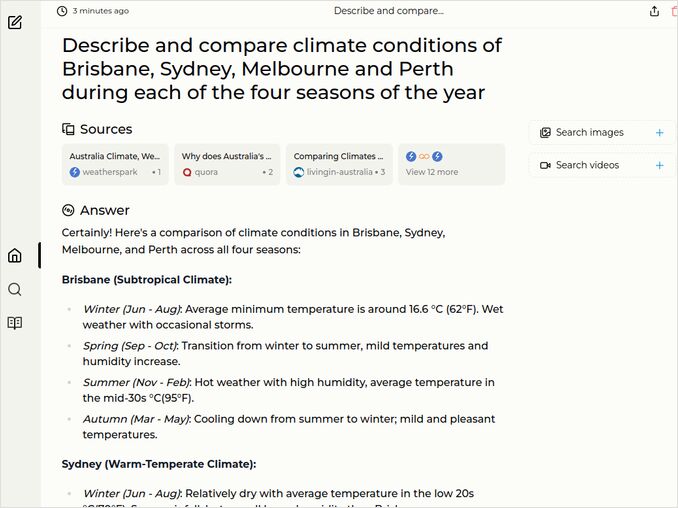
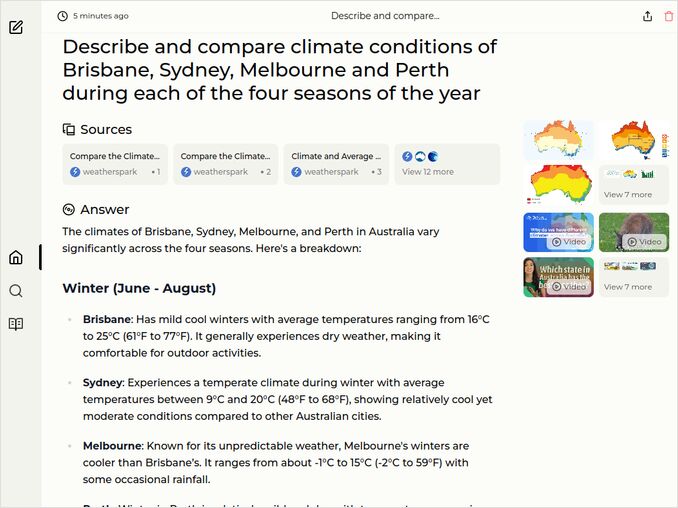
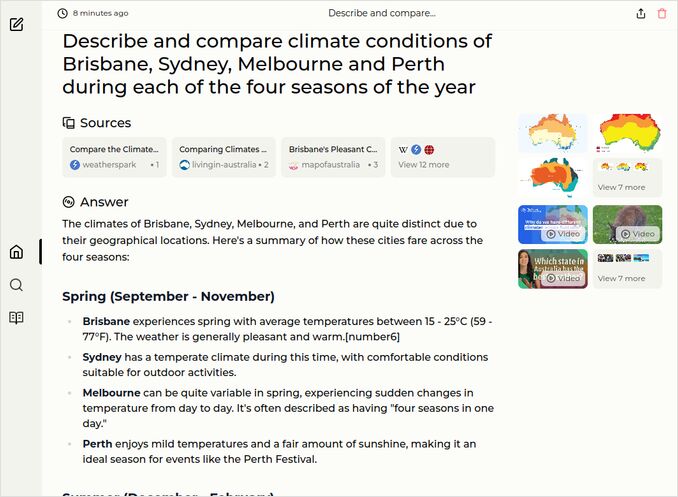
- Describe and compare climate conditions of Brisbane, Sydney, Melbourne and Perth during each of the four seasons of the year
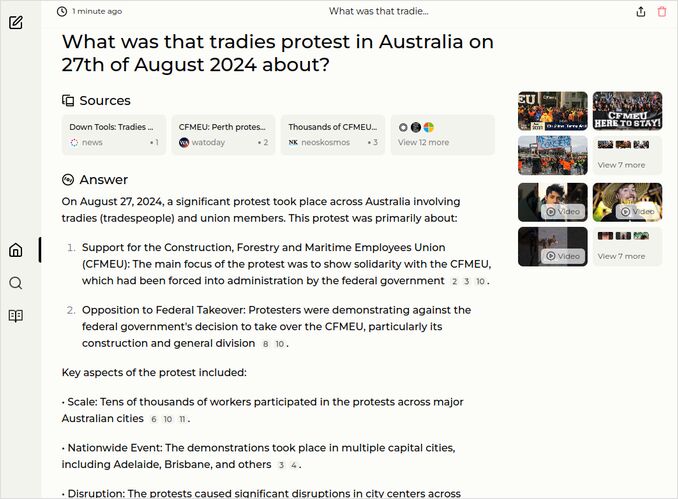
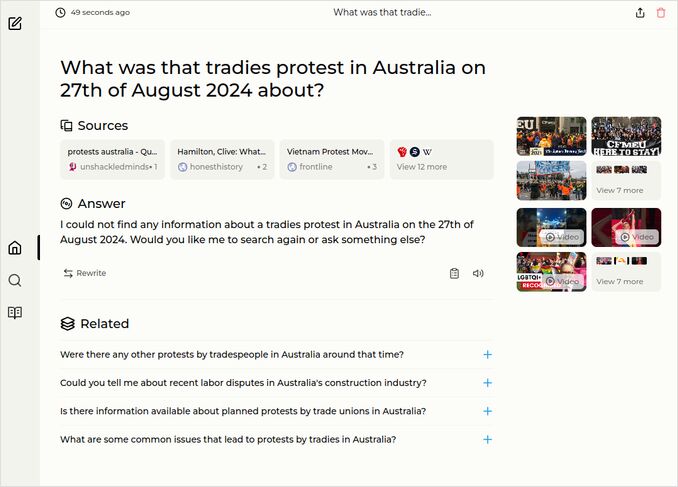
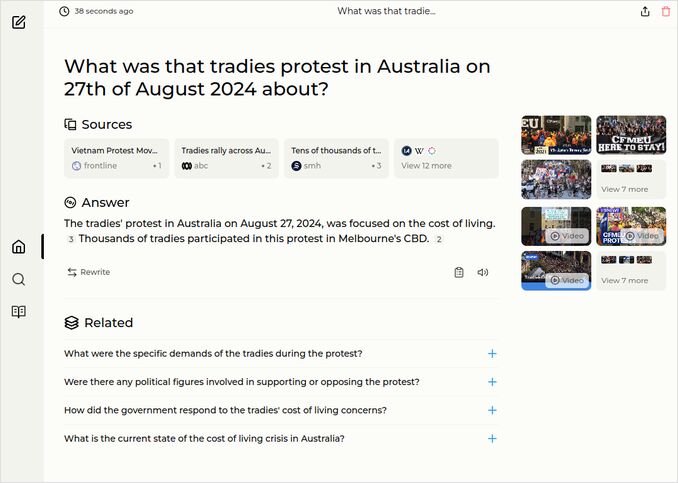
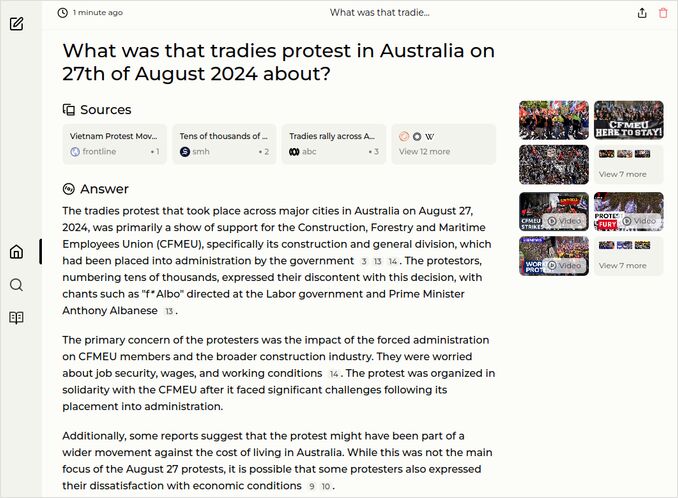
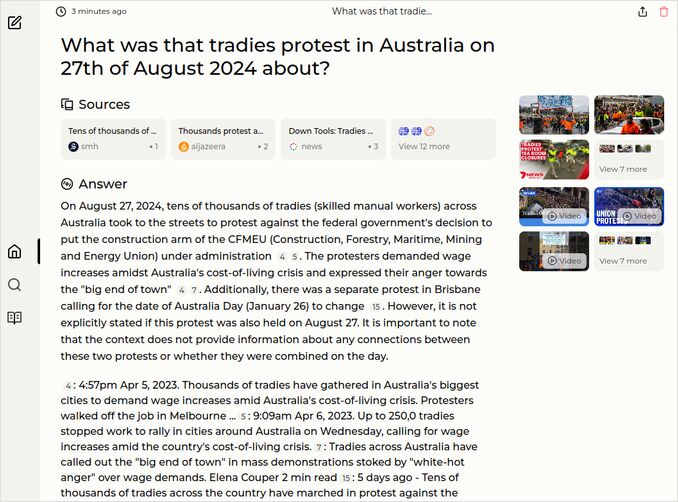
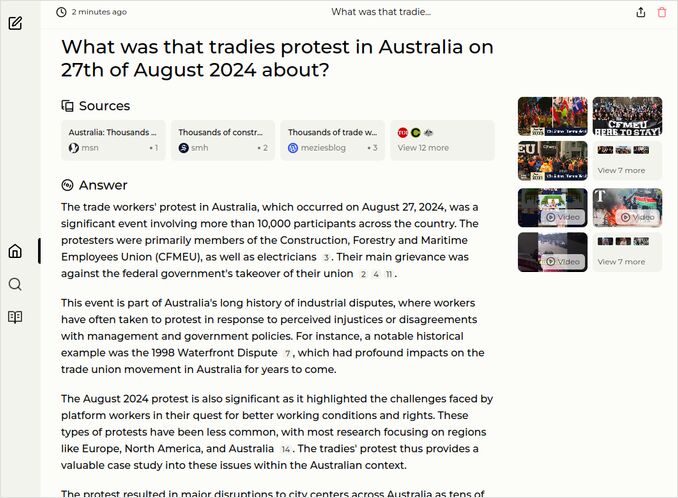
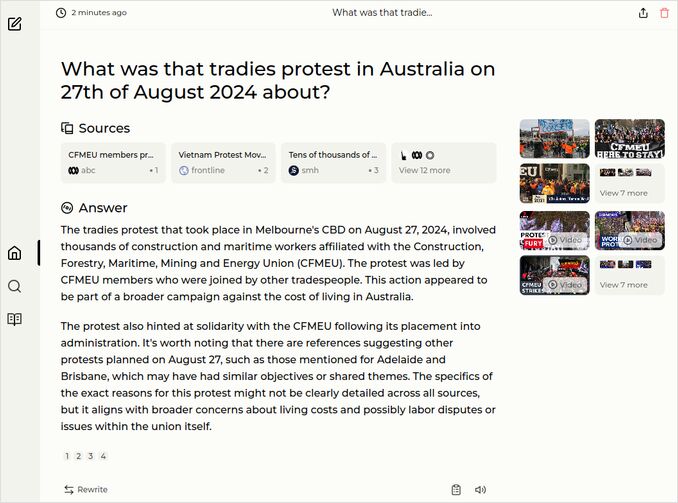
- What was that tradies protest in Australia on 27th of August 2024 about?
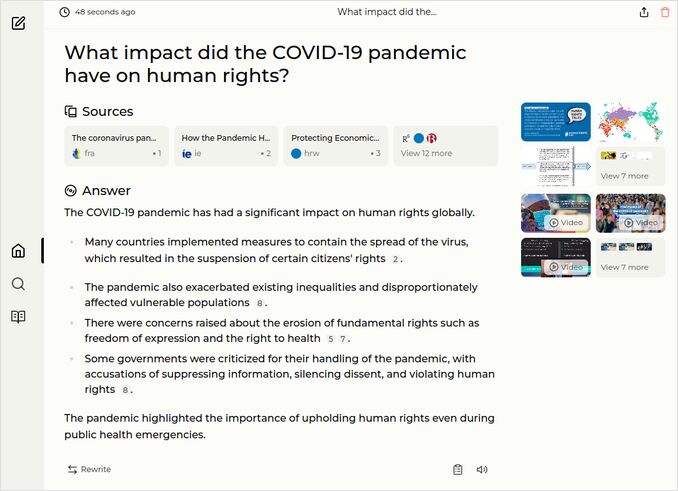
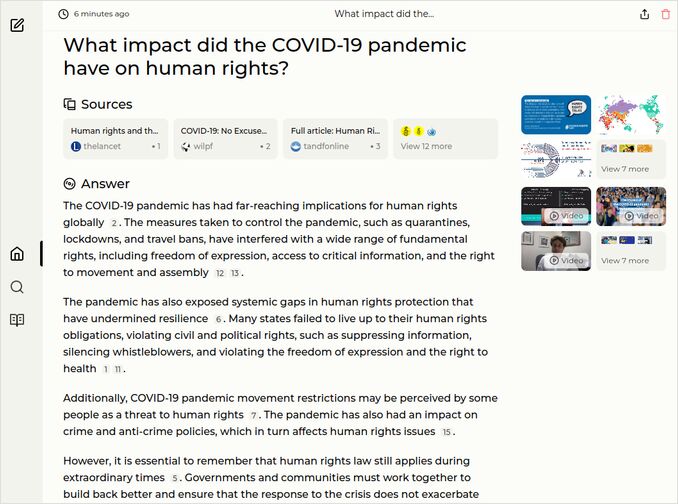
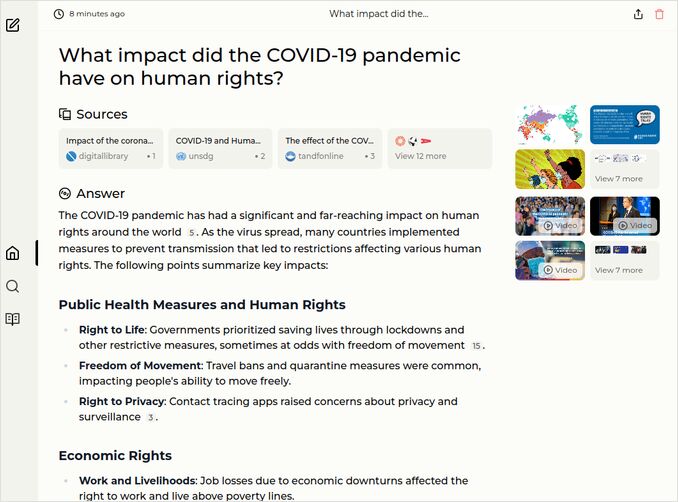
- What impact did the COVID-19 pandemic have on human rights?
We are assessing response quality of Perplexica using particular model, answering each of the questions above
- 0 points - failed to answer correctly
- 1 points - answered correctly
- 2 points - answered correctly. bonus point for depth and/or structure
So that means each model can get minimum 0 points, and max - 6 points.
The context and expectations
-
Question 1.
- Response is to contain 4 seasons description in 4 cities (1 pt if no errors)
- AND must have comparison of seasons in those 4 cities, not just independent descriptions (1 pt if no errors)
- Nice to be open-minded. But must have Celcius temperatures at least - people in those cities are using Celcius degrees, even some other might have learnt Farenheits and Gallons only.
- Three cities are on the eastern coast, one is on the western one, no need to clarify this, but to mark them all eastern is an error.
- We are waiting for some nice formatting.
-
Question 2.
- Just yesterday Australian construction workers were on huge protest. Model must pick correct protest date.
- The government accused Construction Workers’ Trade Union of corruption, and other bad things and appointed external administration
- That means overtaking the control over the body that is to protect and represent the workers interests
- The tradies are against this government overreach.
-
Question 3.
- Lockdowns are taking away freedom of movement
- Censorship and factcheckers - freedom of speech
- And (you know) bodily autonomy when selecting medical procedures without coercion, with informed concent etc., here goes also the damage to the Fabric of society and segregation
- To get 1 point - responce must contain at least two of the above.
Test Results
claude 3 haiku
q1: 0pts - Failed on ratelimit.
q2: 2pts - very good response from Claude Haiku with a lot of details
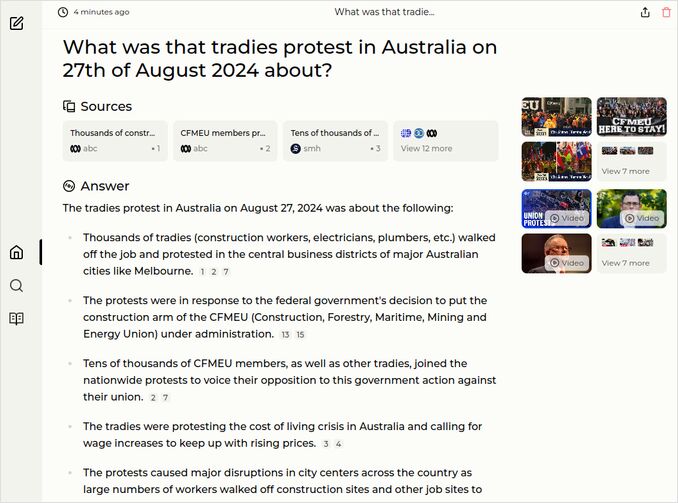
q3: 0pts - Failed on some 403 error.
Sample responses: Perplexica with claude-haiku
Ok just two points in total…
claude 3.5 sonnet
q1: 2pts - Excellent answer from Claude 3.5 Sonnet , with detailed descriptions and comparisons
q2: 2pts - The response of claude-sonnet3.5 to question 2 very good, contains all the needed details. Like this response
q3: 2pts - The response to question about human rights is good. Mentioned fabric of sosciety and dissent suppress. Could be better though. Very good text style.

Sample responses: Perplexica with claude 3.5 sonnet
command-r-35b-v0.1-q2_K
q1: 2pts - The response to question 1 from this model contains Description, but comparison is pretty minimal. Will give extra 5c for “mid-20s and low 30s°C” .
q2: 2pts - The response of command-r-35b-v0.1-q2_K to question 2 very good, contains all the needed details. Like this response
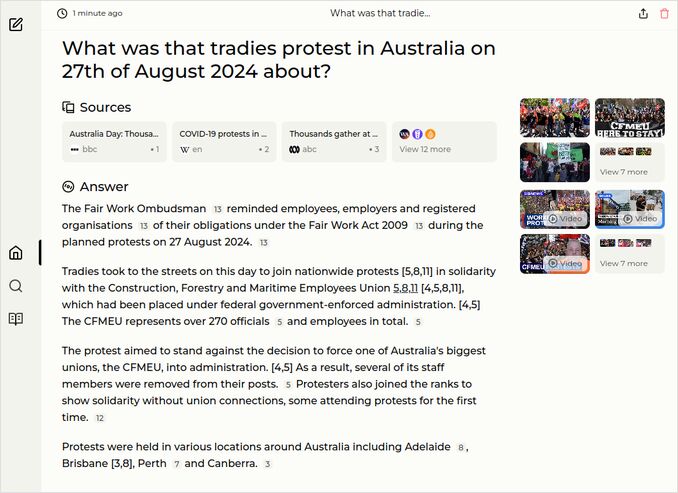
q3: 1pts - The response to question about human rights is OK but not good enough.

Sample responses: Perplexica with command-r-35b-v0.1-q2_K
command-r-35b-v0.1-q3_K_S
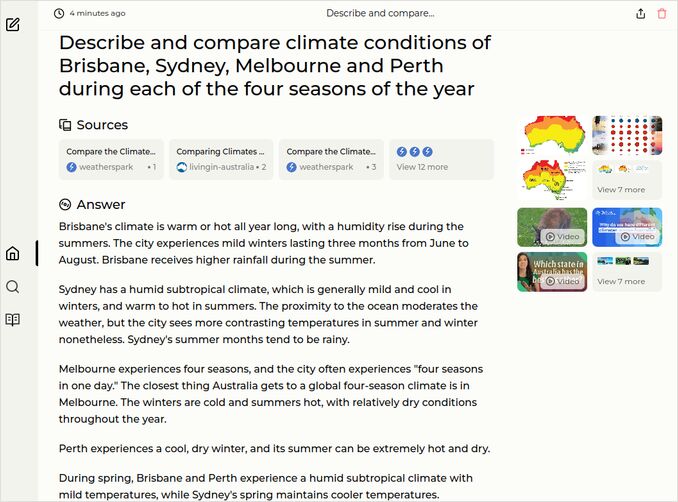
q1: 0pts - Even though this version of command-r-35b is not that heacily quantized as previous, the response is worse. No temperatures, just common wordy description, and missing the Perth’s autumn?
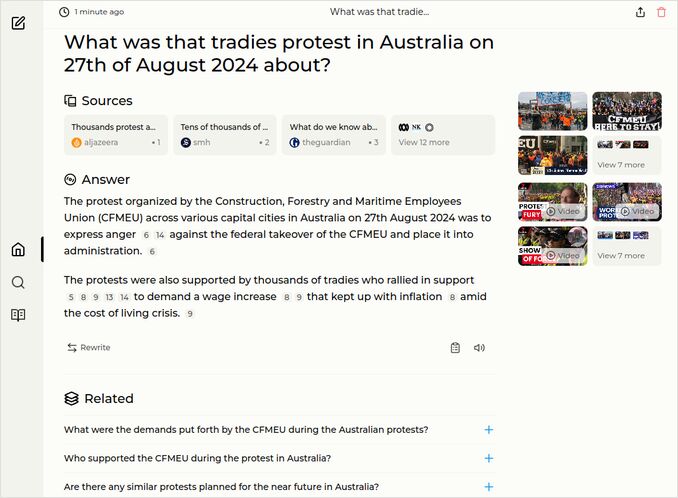
q2: 1pts - The response if this LLM to the question about tradies rally in Australia is OK, but not good enough for the extra point, and too short.
q3: 0pts - Perplexica answer to the question about human rights during pandemic with the model command-r-35b-v0.1-q3_K_S wasn’t good, as you see on the screenshot. Just freedom of association? not enough…

Sample responses: Perplexica with command-r-35b-v0.1-q3_K_S
What was it, command-r-35b-v0.1-q3_K_S? Bad luck?
gemma2-9b-instruct-q8_0
Not trying default quantization 4 gemma 2, going right away to q8.
q1: 0pts - The response of Perplexica with Gemma 2 - 9b q8_0 to the question about climate in various Australian cities was surprisingly bad. Where’s Perth? After second execution - “I apologize for the previous response. I was too focused on the lack of specific seasonal data and missed some key information within the context. Let me try again, using what I can gather:…” And still not excellent. But OK. It had a chance.
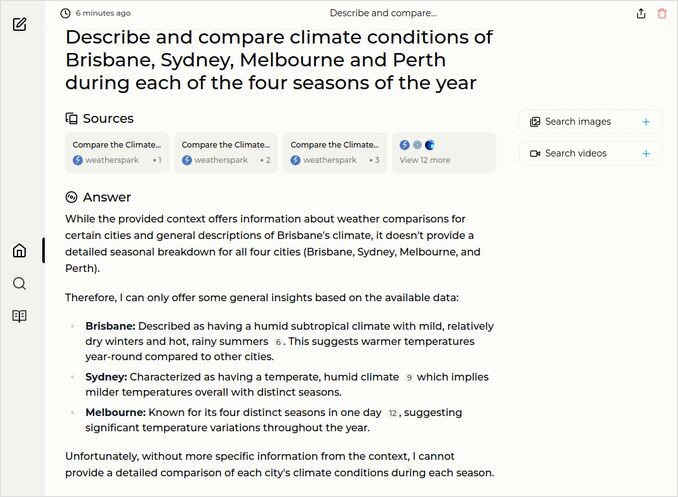
q2: 0pts - The answer to the question about the tradies protest in Australia was negative as you see on the screenshot below. Seriously? could not find anything? Ah Gemma 2, Gemma 2! After second execution - “Thousands of tradies protested in Melbourne’s CBD on August 27, 2024”. Is that all?
q3: 0pts - And answer to the question about how the human rights were impacted wasn’t good to get even 1 point either.
Sample responses: Perplexica with gemma2-9b-instruct-q8_0
And that’s not even a standard gemma2-9b-instruct-q4_0, that’s q8_0.
A candidate for removal.
gemma2-27b-instruct-q3_K_S
q1: 1pts - Good description and comparison, like it, but no temperature numbers. Those who think temperature is not a part of the climate need to talk to climate alarmists.
q2: 0pts - Perplexica with Gemma 2 27B produced incorrect response to the question 2. The protest was focused on government putting it into external administration, that would have been the correct answer.
q3: 0pts - Gemma 2 27B with Perplexica didn’t produce what we expected of it. Just “freedom of expression and assembly” - no freedom of movement mentioned.
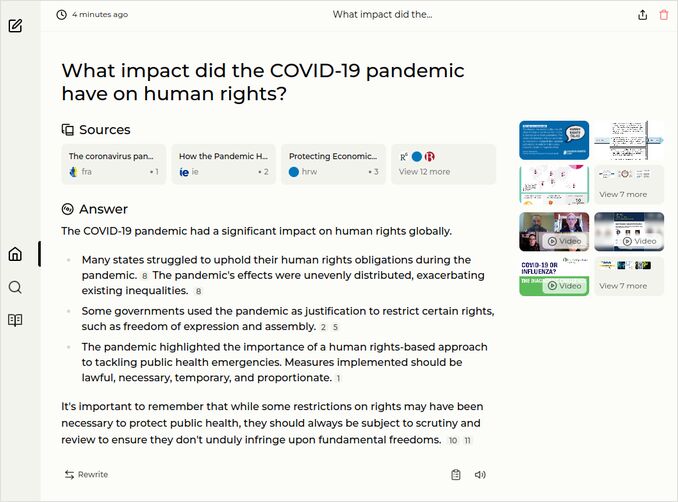
Sample responses: Perplexica with gemma2-27b-instruct-q3_K_S
Will remove it too. Probably.
hermes3-8b-llama3.1-q8_0
q1: 1pts - Good description and comparison, like it, but too much of repeating “temperatures with average highs around” .

q2: 1pts - Perplexica with hermes3-8b-llama3.1-q8_0 answered to the question 2 well. Not pergect, but good enough. The protest was focused on forced administration, that is the correct answer. White - hot anger, yes, colourful words, almost every llm cites these. I’d say “2-” or “1+”
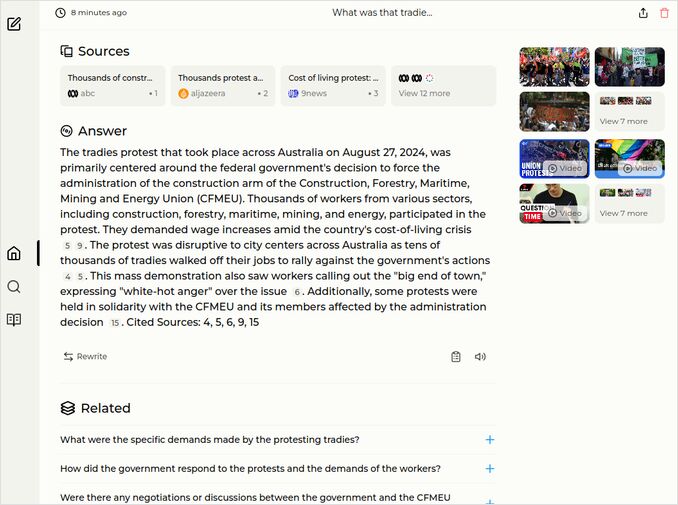
q3: 2pts - Good Perplexica response - restricting freedom of movement, speech, and assembly
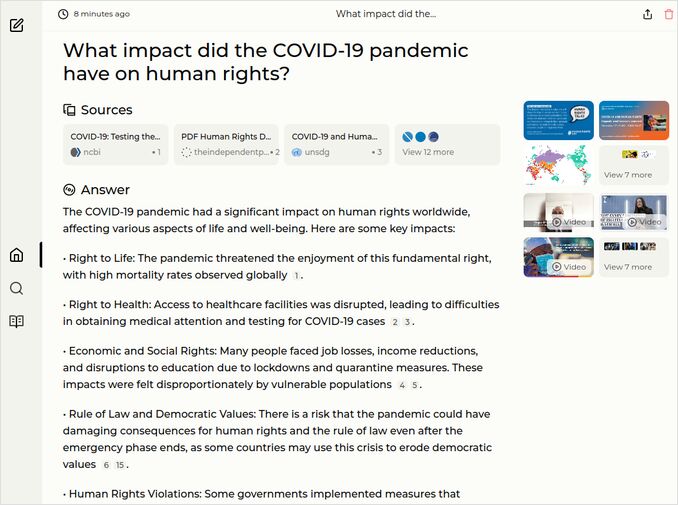
Sample responses: Perplexica with hermes3-8b-llama3.1-q8_0
llama3:8b-instruct-q4_0 (llama3:latest)
q1: 1pts - Llama3 8b from Meta together with Perplexica produced a clear and correct response, nice structure, but no cities comparison. The screenshot of the answer is on the top of the article.
q2: 0pts - Perplexica with llama3:8b could not find the details of this big tradies protest at all:
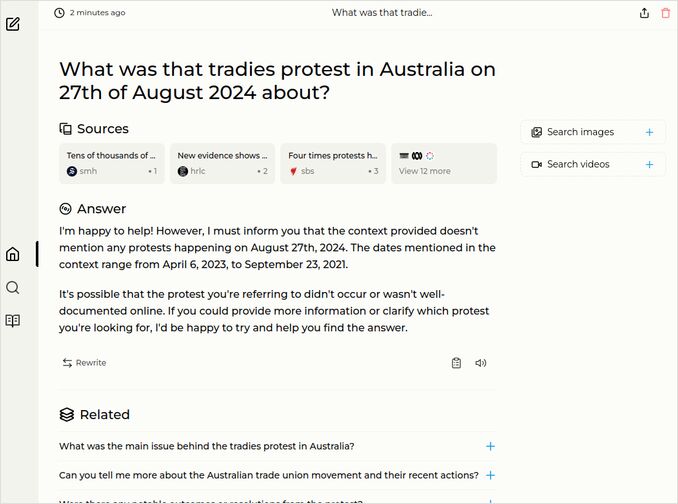
q3: 0pts - The answer to the question about human rights is owerhelmingly from WHO point of view. Why exactly did we need SearxNG? :

Sample responses: Perplexica with llama3-8b-instruct-q4_0
llama3.1-8b-instruct-q4_0
q1: 1pts - very nice structure, even better than from llama3-8b-instruct-q4_0, still no cities comparison :
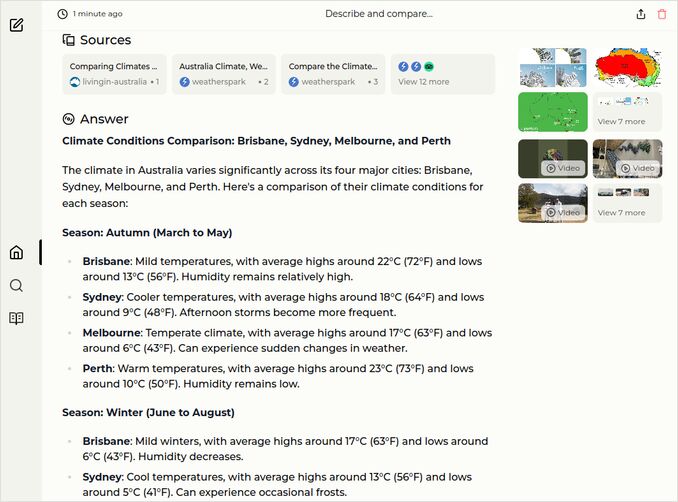
q2: 2pts - Good. could be better, but still like it.
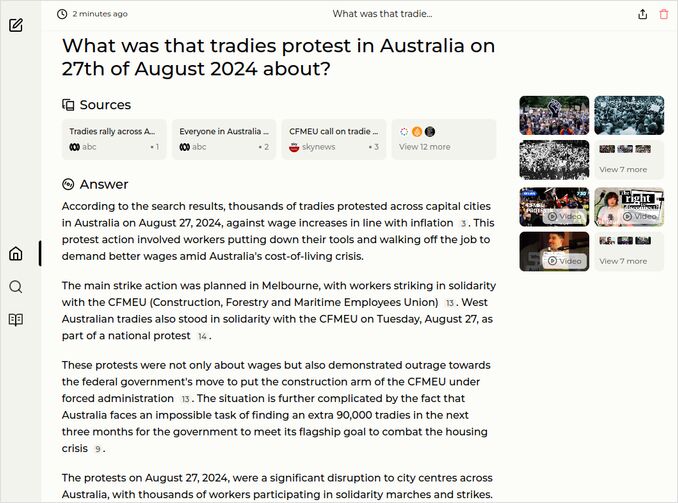
q3: 1pts - Good, but not enough:
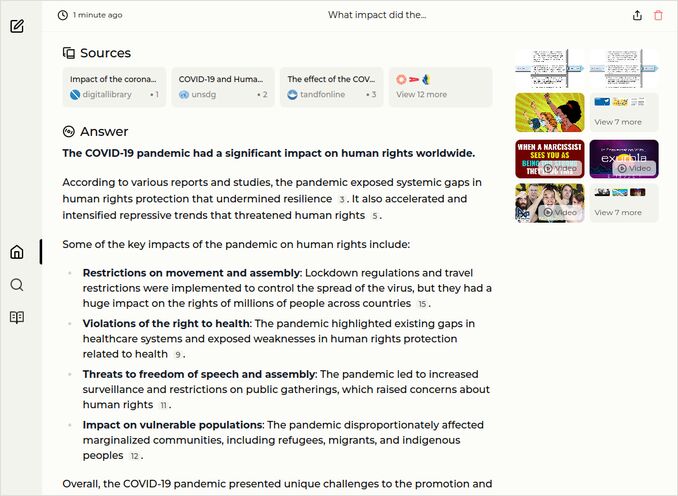
Sample responses: Perplexica with llama3.1-8b-instruct-q4_0
llama3.1-8b-instruct-q6_K
q1: 1pts - All good and clear, still no cities comparison
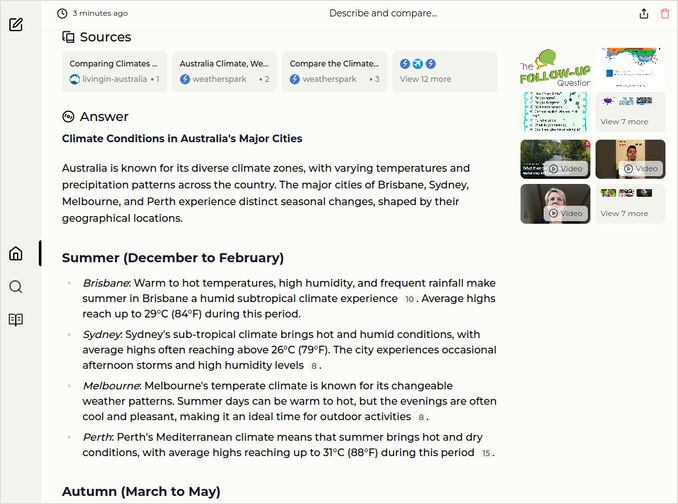
q2: 2pts - Very good:
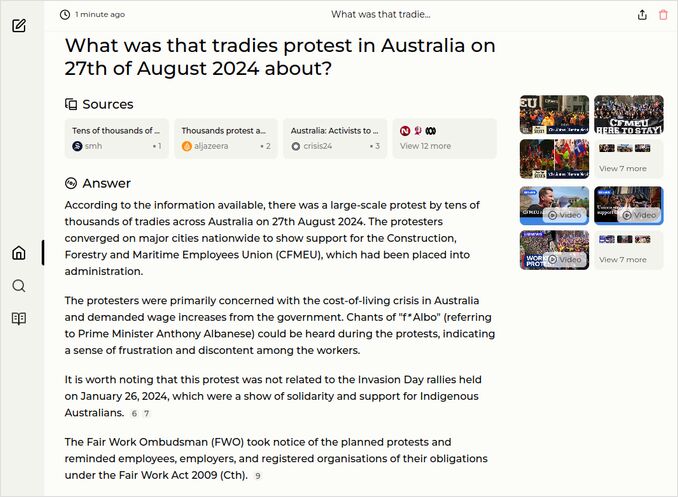
q3: 0pts - well… almost good, but still not.

Sample responses: Perplexica with llama3.1-8b-instruct-q6_K
llama3.1-8b-instruct-q8_0
q1: 2pts - All nice and clear. No Farenheits, but Celcius is in place. no cities comparison :
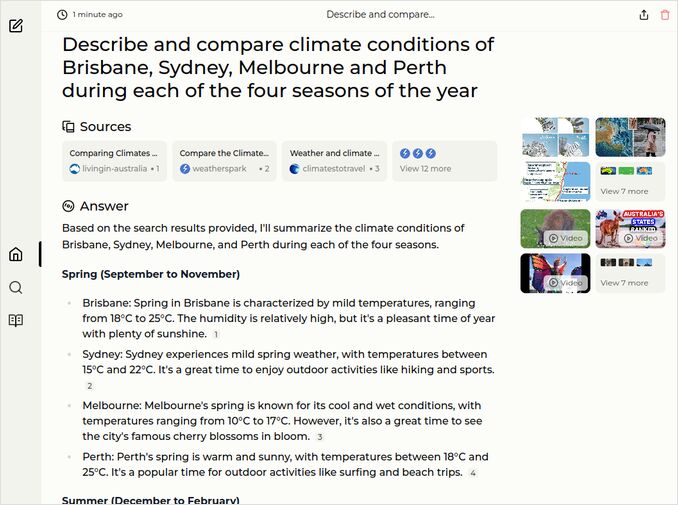
q2: 1pts - Maybe… it is good, but not extremely.
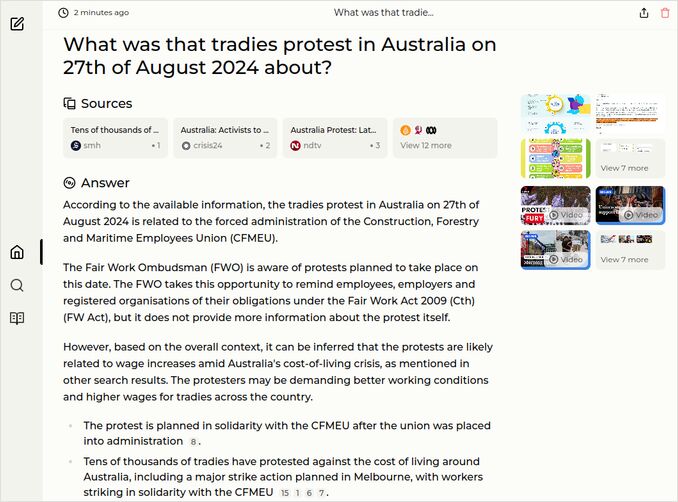
q3: 1pts - First call was not to the point at all. Just Restrictions on movement and assembly… Second call to Perplexica with llama3.1-8b-instruct-q8_0 produced very good response. Many good points. See in the sample responses. Overall giving 1 point.
Sample responses: Perplexica with llama3.1-8b-instruct-q8_0
llama3.1-70b-instruct-q2_K
Now the Cavalry is joining! And not fitting into 16GB of GPU VRAM at all. But the results are better right away.
q1: 2pts - Best so far, we have cities comparison! :
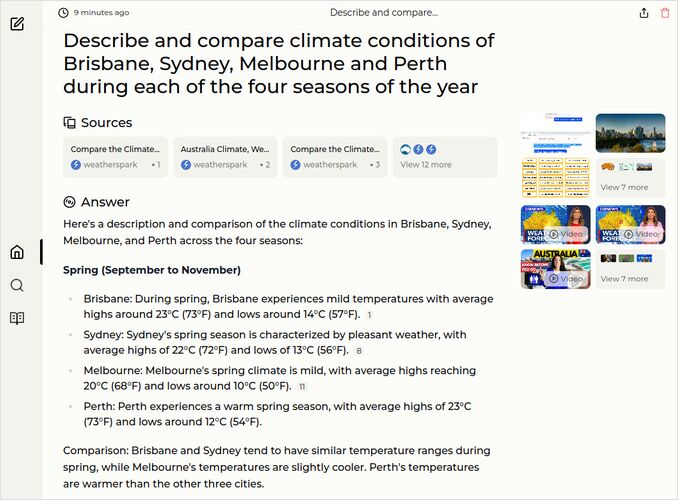
q2: 1pts - The response is orrect but overly conscise.
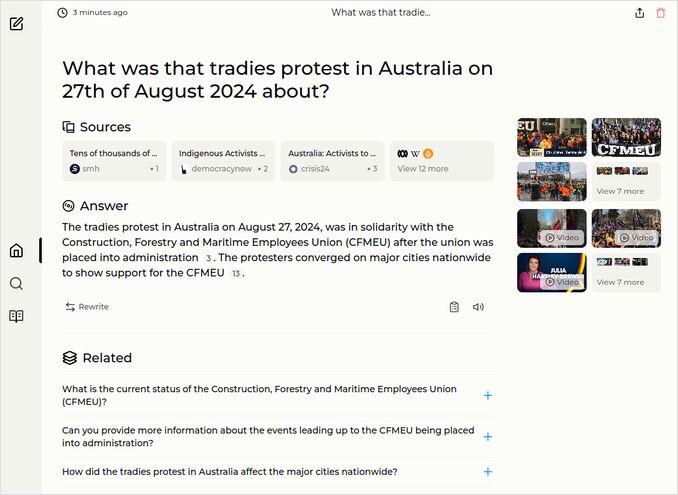
q3: 1pts - The best response so far, but still, no mentioning of bodily autonomy and coercion.
Sample responses: Perplexica with llama3.1-70b-instruct-q2_K
llama3.1-70b-instruct-q3_K_S
q1: 2pts - Good rich language, Very good comparison and description. The choice of the sources is also excellent.

q2: 1pts - Correct but not enough to be good.
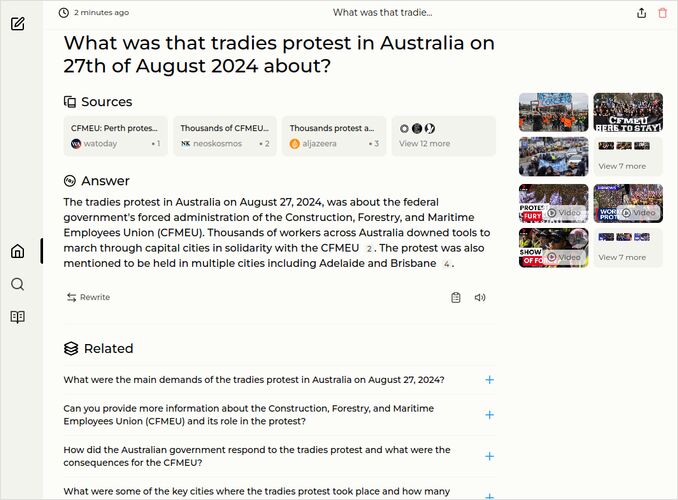
q3: 1pts - Citing many reports, like “need to address”, without details. But Freedom of movement and expression are mentioned. ok. The Lancet looks better to me than that those words from United Nations High Commissioner for Human Rights - “disproportionate impact on vulnerable populations”, “the protection of marginalized groups.” … Like proportionate impact is ok… like missing importance of protection of human rights for all, not just marginalised groups. The response best we have so far. If no other model compiles such list of references, will give it extra point.

Sample responses: Perplexica with llama3.1-70b-instruct-q3_K_S
llama3.1-70b-instruct-q4_0
q1: 2pts - llama3.1-70b-instruct-q4_0 model’s response to the question about four cities climate during four seasons contains - good descriptions with decent language quality, Very good comparison and description. The choice of the sources is also excellent. Sources in the end of the text is a bug.

q2: 2pts - Excellent response of Perplexica with llama3.1-70b-instruct-q4_0 model to the question about Australian tradies protest deserves 2 points:
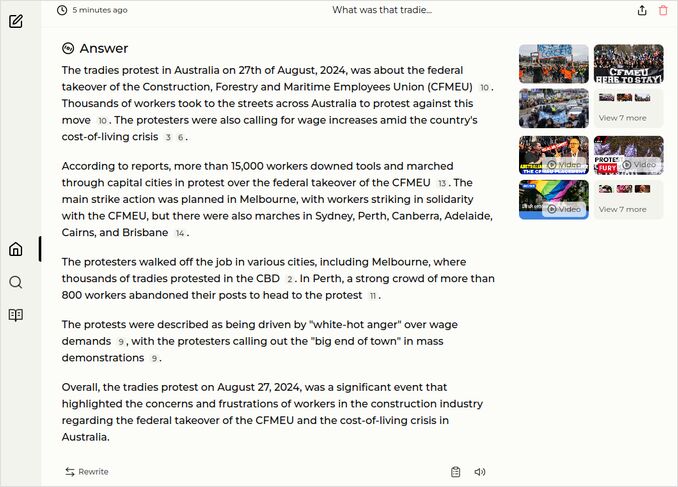
q3: 0pts - The response contained only water. Huge impact, devastating impact, far-reaching impact on human rights. That not what we wanted to know.

Sample responses: Perplexica with llama3.1-70b-instruct-q4_0
mistral-nemo-12b-instruct-2407-q6_K
q2: 2pts - Good, quite long and clear description, summary can count as comparison.
q2: 2pts - Very good and detailed response:
q3: 2pts - All as expected, many details listed, very good, logical response.

The best model so far.
Sample responses: Perplexica with mistral-nemo-12b-instruct-2407-q6_K
!!! Mistrall Nemo 12b q6 is not producing follow-up questions buttons in Perplexica… and listing sources as a part of response.
mistral-nemo-12b-instruct-2407-q8_0
This model didn’t fit well with embeddings one into VRAM, Ollama gave OOM. I was using internal Perplexica embeddings - BGE Small. Still gave me very good results.
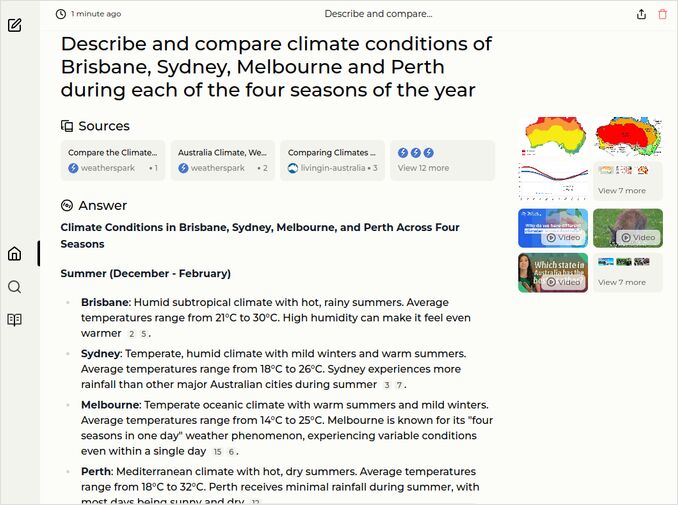
q1: 2pts - Excellent description and good comparison
q2: 2pts - Very good response:
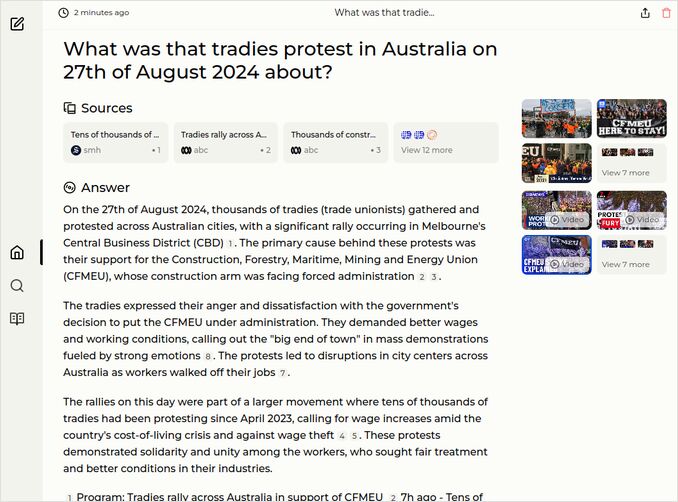
q3: 2pts - Response mentions freedom of movement, assembly, and expression, and social fabric. Good. Not excellent, but good enough.

Sample responses: Perplexica with mistral-nemo-12b-instruct-2407-q8_0
!!! Mistrall Nemo 12b q8 is not producing follow-up questions buttons in Perplexica… and listing sources as a part of response.
mistral-large-122b-instruct-2407-q3_K_S
This model is very large, more then 50GB. I was using internal Perplexica embeddings - BGE Small.
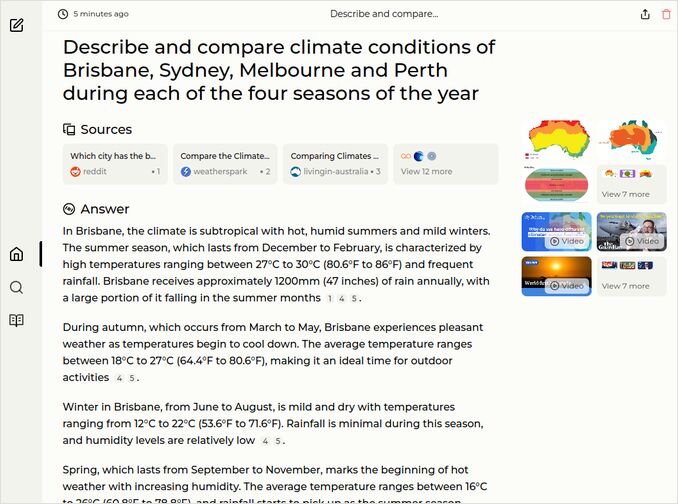
q1: 2pts - response was good in per-city descriptions, and two comparisons.

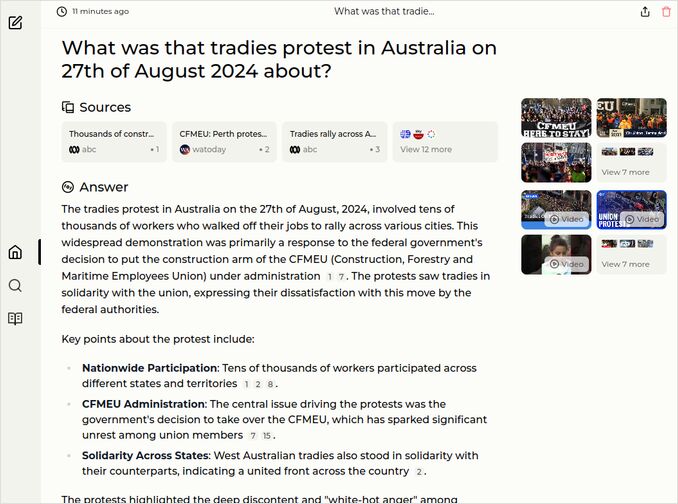
q2: 2pts - Excellent response from mistral large 122b, main reason was disagreement with government placing external administration over the union:
q3: 1pts - Response mentions lockdown and fabrics not good enough to be good.

Sample responses: Perplexica with mistral-large-122b-instruct-2407-q3_K_S
mixtral-8x7b-instruct-v0.1-q3_K_M
I was using internal Perplexica embeddings here too - BGE Small.
q1: 1pts - response was only in per-city descriptions and short summary, no structure, no comparisons.
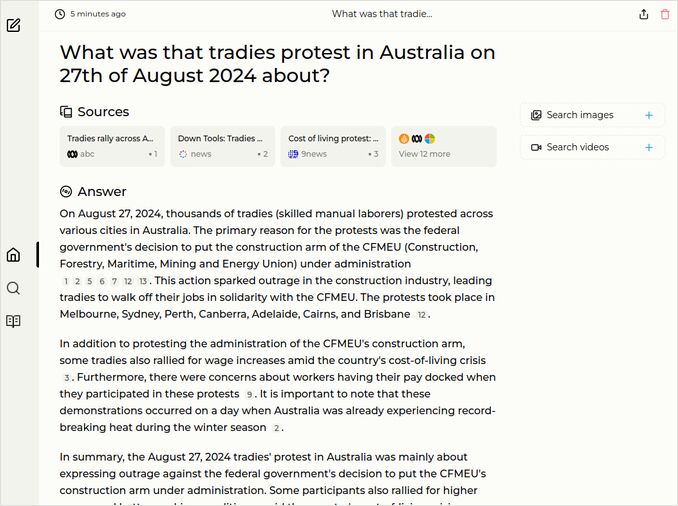
q2: 2pts - Excellent response from mistral large 122b, main reason was disagreement with government placing external administration over the union:
q3: 1pts - Response mentions lockdown and fabrics not good enough to be good.

Sample responses: Perplexica with mixtral-8x7b-instruct-v0.1-q3_K_M
mixtral-8x7b-instruct-v0.1-q5_1
I was using internal Perplexica embeddings here too - BGE Small.
q1: 1pts - detailed per-city descriptions, and just short summary and listtle comparison, there is a structure, repeating text patterns.

q2: 1pts - government placing the union under external administration. And then some mixup about another protest:
q3: 0pts - Response mentions - Wuhan officials in China suppressing information, silencing whistleblowers, and violating the freedom of expression and the right to health. That’s not enough for 1 point

Didn’t like repeating phrases. But the model is quite fast.
Sample responses: Perplexica with mixtral-8x7b-instruct-v0.1-q5_1
phi3-14b-medium-128k-instruct-q6_K
I was using internal Perplexica embeddings - BGE Small, same case as from Mistral Nemo - 12b q8.
q1: 1pts - All nice, good comparison, but LLM is talking too much.
q2: 1pts - Result is good, but model is talking too much out of context:
q3: 1pts - almost good, but still not. mentions democratic fabric and suppression of information.

Sample responses: Perplexica with phi3-14b-medium-128k-instruct-q6_K
qwen2-7b-instruct-q8_0
q1: 2pts - both C and F, all detailed descriptions and comparison. very good.
q2: 2pts - Good response, could be better, but still good:
q3: 1pts - Democratic Fabric and censorship. Thats good but not enough for 2 points. And the word “Result” in response.

Sample responses: Perplexica with qwen2-7b-instruct-q8_0
Overall, happy with this LLM version.
qwen2-72b-instruct-q2_K
q1: 1pts - good, comparison in place, and nice adjectives, but references like [number6], maybe it’s some glitch?
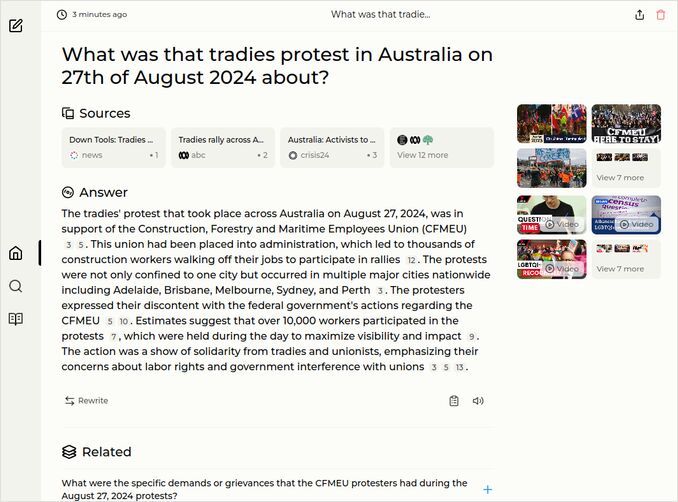
q2: 2pts - Excellent response, and references look much better. It was unstable with the references before.
q3: 2pts - Very good detailed summary. Listed among others th Freedom of movement, access to information, media restrictions and privacy
Sample responses: Perplexica with qwen2-72b-instruct-q2_K
In the beginning I did set 1 point for q1 here but other two responses were too good, I gave it a second chance and re-run question 1. Second time it produced clear response with better references but without comparison. So, still receiving 1 point. That’s very unfortunate.
qwen2-72b-instruct-q3_K_S
q1: 1pts - Good description, but no comparison?

q2: 2pts - Excellent description, structure and details in qwen2-72b-instruct-q3_K_S ’s summary
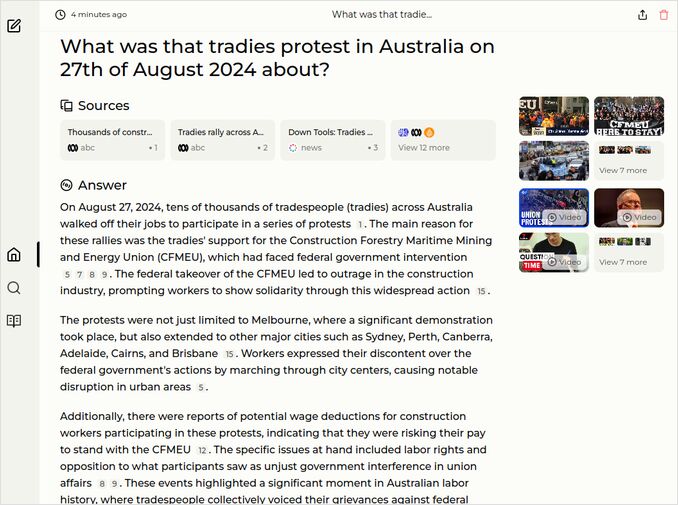
q3: 0pts - All the water, but no details. Most of the attention to equity and vulneralbe populations.

Sample responses: Perplexica with qwen2-72b-instruct-q3_K_S
qwen2-72b-instruct-q4_1
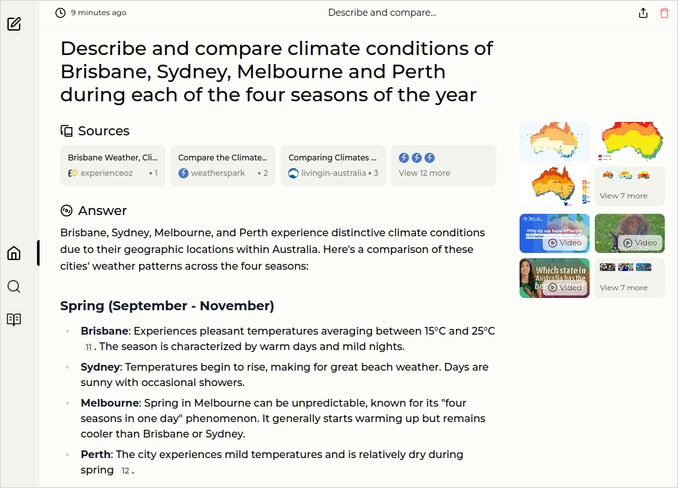
q1: 2pts - The model qwen2-72b-instruct-q4_1 produced an excellent four cities climate description with inline comparison
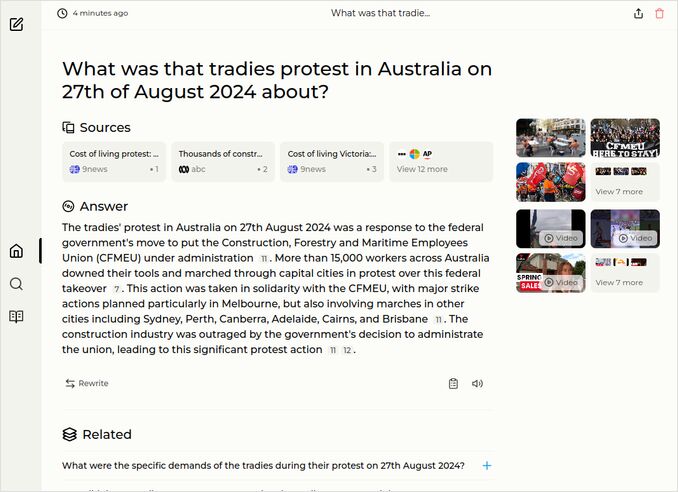
q2: 2pts - Not a lot, but this model produced good summary of August Australian tradies protests
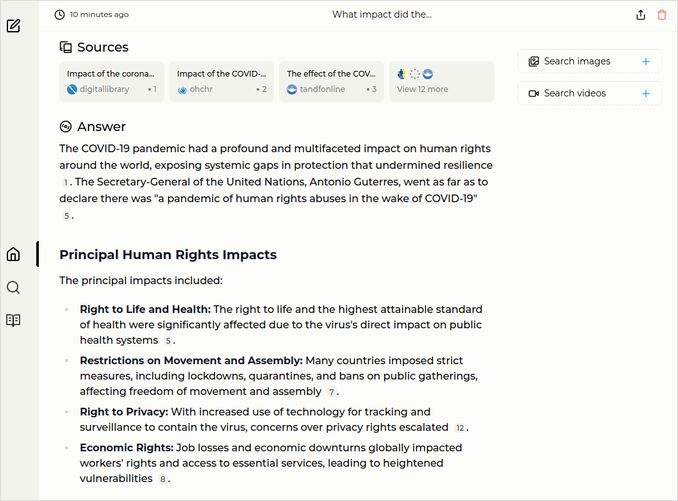
q3: 2pts - Awesome response of Perplexica with qwen2-72b-instruct-q4_1. Good structure and details.
Sample responses: Perplexica with qwen2-72b-instruct-q4_1
Useful links
Sample responses:
- Perplexica with claude 3 haiku
- Perplexica with claude 3.5 sonnet
- Perplexica with command-r-35b-v0.1-q2_K
- Perplexica with command-r-35b-v0.1-q3_K_S
- Perplexica with gemma2-9b-instruct-q8_0
- Perplexica with gemma2-27b-instruct-q3_K_S
- Perplexica with hermes3-8b-llama3.1-q8_0
- Perplexica with llama3-8b-instruct-q4_0
- Perplexica with llama3.1-8b-instruct-q4_0
- Perplexica with llama3.1-8b-instruct-q6_K
- Perplexica with llama3.1-8b-instruct-q8_0
- Perplexica with llama3.1-70b-instruct-q2_K
- Perplexica with llama3.1-70b-instruct-q3_K_S
- Perplexica with llama3.1-70b-instruct-q4_0
- Perplexica with mistral-nemo-12b-instruct-2407-q6_K
- Perplexica with mistral-nemo-12b-instruct-2407-q8_0
- Perplexica with mistral-large-122b-instruct-2407-q3_K_S
- Perplexica with mixtral-8x7b-instruct-v0.1-q3_K_M
- Perplexica with mixtral-8x7b-instruct-v0.1-q5_1
- Perplexica with phi3-14b-medium-128k-instruct-q6_K
- Perplexica with qwen2-7b-instruct-q8_0
- Perplexica with qwen2-72b-instruct-q2_K
- Perplexica with qwen2-72b-instruct-q3_K_S
- Perplexica with qwen2-72b-instruct-q4_1
Other links
- Search vs Deepsearch vs Deep Research
- How Ollama Handles Parallel Requests
- Self-hosting Perplexica - with Ollama
- Configure Ollama Models location
- LLM speed performance comparison
- Writing effective prompts for LLMs
- Comparing LLM Summarising Abilities
- Farfalle vs Perplexica - selfhosted search engines
- Logical Fallacy Detection with LLMs
- Testing logical fallacy detection by new LLMs: gemma2, qwen2 and mistralNemo
- LLMs comparison: Mistral Small, Gemma 2, Qwen 2.5, Mistral Nemo, LLama3 and Phi
- Ollama cheatsheet
- Qwen3 Embedding & Reranker Models on Ollama: State-of-the-Art Performance
Subscribe
Get new posts on AI systems, Infrastructure, and AI engineering.