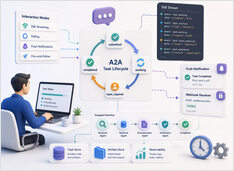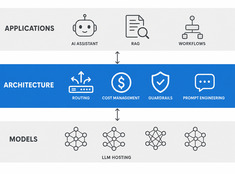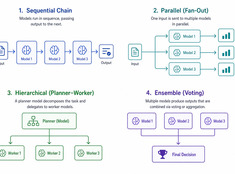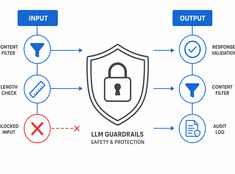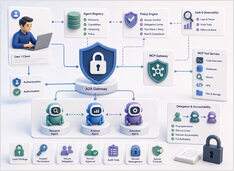
Sécurité des agents A2A et MCP : identité, délégation et traçabilité
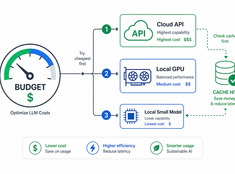
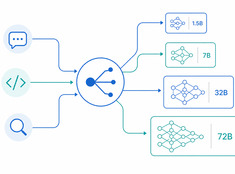
La sécurité du protocole concerne qui peut agir, non le modèle.
L’injection de prompt attire la majeure partie de l’attention en matière de sécurité dans les systèmes de LLM, et cela est justifié, mais ce n’est pas le seul problème une fois que les agents commencent à utiliser des outils et à déléguer du travail à d’autres agents.