
Qwen3 Embedding- & Reranker-Modelle auf Ollama: State-of-the-Art-Leistung
Neue beeindruckende LLMs in Ollama verfügbar
Die Qwen3 Embedding und Reranker Modelle sind die neuesten Veröffentlichungen in der Qwen-Familie und wurden speziell für fortgeschrittene Text-Embedding-, Retrieval- und Reranking-Aufgaben entwickelt.
Freude für das Auge
Die Qwen3 Embedding und Reranker Modelle stellen einen bedeutenden Fortschritt in der multilingualen natürlichen Sprachverarbeitung (NLP) dar und bieten state-of-the-art Leistungen bei Aufgaben wie Text-Embedding und Reranking. Diese Modelle, Teil der Qwen-Reihe, die von Alibaba entwickelt wurde, sind so konzipiert, dass sie eine Vielzahl von Anwendungen unterstützen, von semantischem Retrieval bis hin zu Code-Suche. Obwohl Ollama eine beliebte Open-Source-Plattform für das Hosting und Bereitstellen großer Sprachmodelle (LLMs) ist, wird die Integration der Qwen3-Modelle mit Ollama nicht explizit in der offiziellen Dokumentation beschrieben. Die Modelle sind jedoch über Hugging Face, GitHub und ModelScope zugänglich, was eine potenzielle lokale Bereitstellung über Ollama oder ähnliche Tools ermöglicht.
Beispiele zur Verwendung dieser Modelle
Bitte siehe Beispielcode in Go mit Ollama und diesen Modellen:
- Textdokumente mit Ollama und Qwen3 Embedding-Modell reranken – in Go
- Textdokumente mit Ollama und Qwen3 Reranker-Modell reranken – in Go
Übersicht der neuen Qwen3 Embedding- und Reranker-Modelle auf Ollama
Diese Modelle sind jetzt in verschiedenen Größen für die Bereitstellung auf Ollama verfügbar und bieten state-of-the-art Leistungen und Flexibilität für eine Vielzahl von Sprach- und Code-Anwendungen.
Hauptmerkmale und Fähigkeiten
-
Modellgrößen und Flexibilität
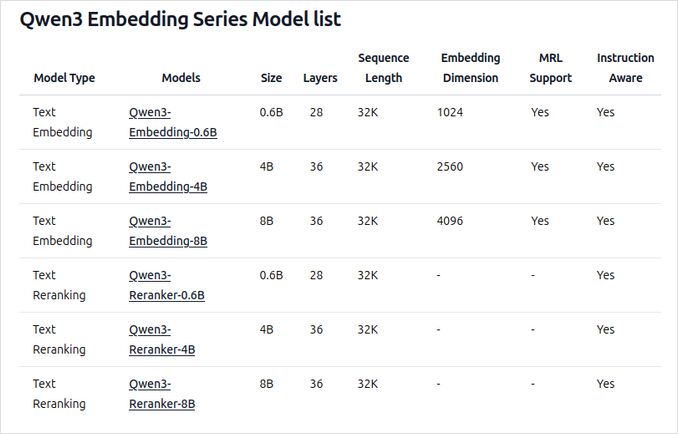
- In mehreren Größen verfügbar: 0,6B, 4B und 8B Parameter für beide Embedding- und Reranking-Aufgaben.
- Der 8B Embedding-Modell rangiert derzeit auf Platz 1 der MTEB-Mehrsprachigen Leaderboard (Stand 5. Juni 2025 mit einer Punktzahl von 70,58).
- Unterstützt eine Vielzahl von Quantisierungsoptionen (Q4, Q5, Q8 usw.) zur Balance zwischen Leistung, Speicherbedarf und Geschwindigkeit. Q5_K_M wird für die meisten Benutzer empfohlen, da sie die meisten Modellleistungen bewahrt, während sie ressourceneffizient ist.
-
Architektur und Training
- Auf der Qwen3-Grundlage aufgebaut, wobei sowohl die dual-encoder-Architektur (für Embedding) als auch die cross-encoder-Architektur (für Reranking) genutzt werden.
- Embedding-Modell: Verarbeitet einzelne Textabschnitte und extrahiert semantische Darstellungen aus dem finalen verborgenen Zustand.
- Reranker-Modell: Nimmt Textpaare (z. B. Abfrage und Dokument) und erzeugt eine Relevanzbewertung mit einem cross-encoder-Ansatz.
- Embedding-Modelle verwenden ein dreistufiges Trainingsparadigma: kontrastives Vortraining, überwachtes Training mit hochwertigen Daten und Modellfusion für optimale Generalisierung und Anpassungsfähigkeit.
- Reranker-Modelle werden direkt mit hochwertigen etikettierten Daten trainiert, um Effizienz und Effektivität zu gewährleisten.
-
Mehrsprachige und multitaskingfähige Unterstützung
- Unterstützt über 100 Sprachen, einschließlich Programmiersprachen, wodurch robuste mehrsprachige, über-sprachliche und Code-Retrieval-Fähigkeiten ermöglicht werden.
- Embedding-Modelle ermöglichen flexible Vektordefinitionen und benutzerdefinierte Anweisungen, um die Leistung an bestimmte Aufgaben oder Sprachen anzupassen.
-
Leistung und Anwendungsfälle
- State-of-the-art Ergebnisse in Text-Retrieval, Code-Retrieval, Klassifizierung, Clustering und Bitext-Mining.
- Reranker-Modelle sind in verschiedenen Text-Retrieval-Szenarien hervorragend und können nahtlos mit Embedding-Modellen kombiniert werden, um End-to-End-Retrieval-Pipelines zu erstellen.
Wie man sie auf Ollama verwendet
Sie können diese Modelle auf Ollama mit Befehlen wie folgt verwenden:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Wählen Sie die Quantisierungsversion, die am besten zu Ihren Hardware- und Leistungsanforderungen passt.
Zusammenfassungstabelle
| Modelltyp | Verfügbare Größen | Hauptvorteile | Mehrsprachige Unterstützung | Quantisierungsoptionen |
|---|---|---|---|---|
| Embedding | 0,6B, 4B, 8B | Top MTEB-Scores, flexibel, effizient, SOTA | Ja (100+ Sprachen) | Q4, Q5, Q6, Q8 usw. |
| Reranker | 0,6B, 4B, 8B | Excelle bei Relevanz von Textpaaren, effizient, flexibel | Ja | F16, Q4, Q5 usw. |
Toll Nachricht!
Die Qwen3 Embedding- und Reranker-Modelle auf Ollama stellen einen bedeutenden Schritt in der mehrsprachigen, multitaskingfähigen Text- und Code-Retrieval-Fähigkeit dar. Mit flexiblen Bereitstellungsoptionen, starken Benchmark-Leistungen und Unterstützung für eine Vielzahl von Sprachen und Aufgaben sind sie ideal für Forschungs- und Produktionsumgebungen geeignet.
Modellzoo – Freude für das Auge jetzt
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
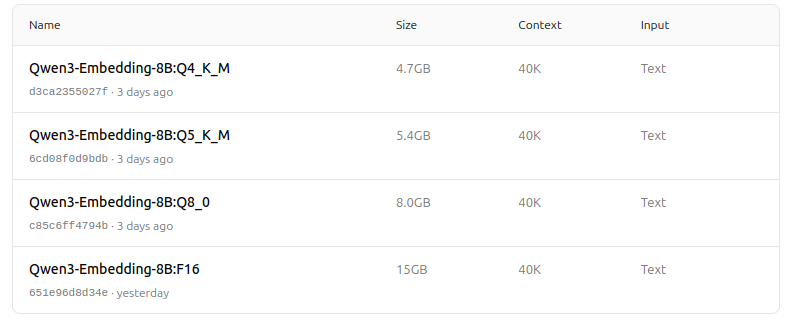
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
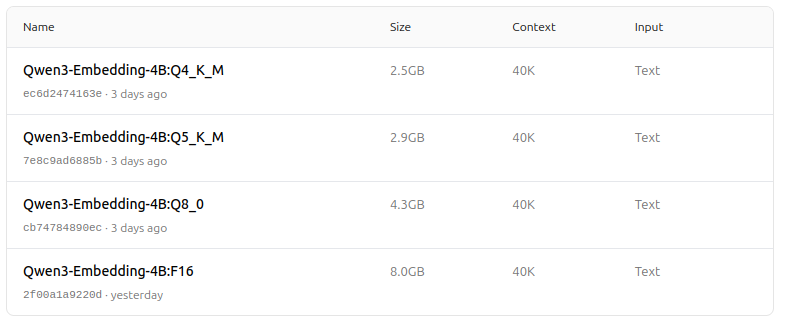
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
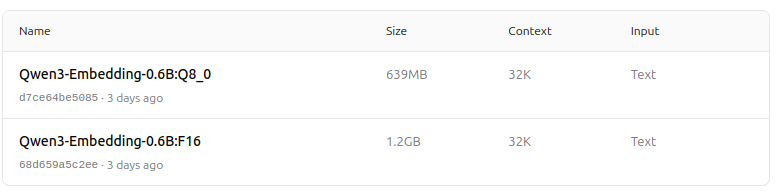
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
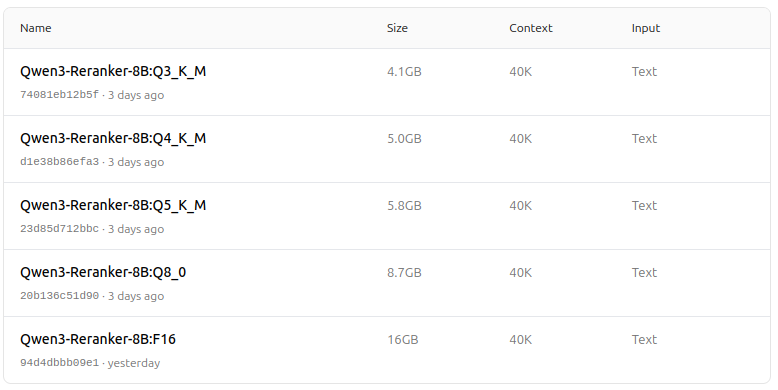
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
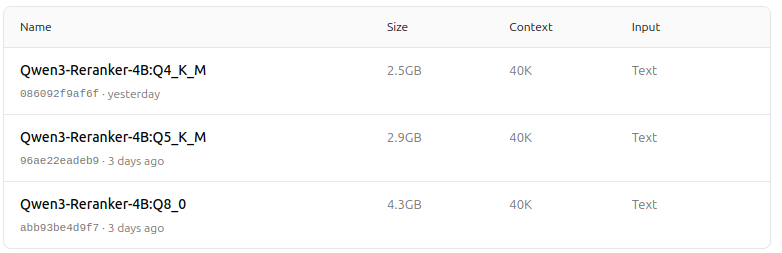
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
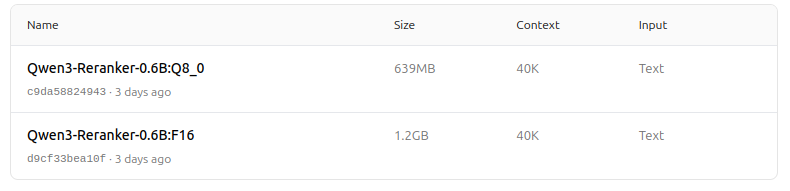
Schön!
Nützliche Links
- Textdokumente mit Ollama und Qwen3 Embedding-Modell reranken – in Go
- Textdokumente mit Ollama und Qwen3 Reranker-Modell reranken – in Go
- Ollama cheatsheet
- Ollama-Modelle auf einen anderen Laufwerk oder Ordner verschieben
- Selbsthosting von Perplexica – mit Ollama
- Test: Wie Ollama Intel-CPU-Performance und Effiziente Kerne verwendet
- LLM-Geschwindigkeitsvergleich
- Vergleich der Summarisierungsfähigkeiten von LLMs
- Cloud-LLM-Anbieter
- Wie Ollama parallele Anfragen verarbeitet
- Vergleich der Qualität der Hugo-Übersetzung – LLMs auf Ollama
