
NVIDIA DGX Spark vs Mac Studio vs RTX-4080: Ollamaの性能比較
GPT-OSS 120bの3つのAIプラットフォームにおけるベンチマーク
私は、Ollama上でGPT-OSS 120bのパフォーマンステストを3つの異なるプラットフォームで確認しました:NVIDIA DGX Spark, Mac Studio, and RTX 4080。OllamaライブラリのGPT-OSS 120bモデルは65GBあり、これはRTX 4080(または新しいRTX 5080の16GB VRAMには収まらないことを意味します。
はい、モデルは部分的にCPUにオフロードして実行することが可能です。64GBのシステムRAMがある場合(私のように)、試してみることができます。ただし、この設定は生産性に必要なパフォーマンスとはほど遠いものになります。本当に要求の厳しいワークロードでは、NVIDIA DGX Sparkのようなものが必要になるかもしれません。これは、大容量のAIワークロードに特化して設計されています。
LLMのパフォーマンスに関する情報(スループット対レイテンシー、VRAMの制限、ランタイムおよびハードウェアにわたるベンチマークなど)については、LLM Performance: Benchmarks, Bottlenecks & Optimizationをご覧ください。

私は、このLLMがDGX Sparkのような「高RAM AIデバイス」上で大幅にパフォーマンスが向上するものだと期待していました。結果は良好ですが、DGX Sparkとより安価なオプションの価格差に比べて、想像ほど劇的に良い結果にはなっていません。
TL;DR
OllamaでGPT-OSS 120bを実行した際の3つのプラットフォームにおけるパフォーマンス比較:
| デバイス | プロンプト評価性能(トークン/秒) | 生成性能(トークン/秒) | メモ |
|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | 全体的に最も優れたパフォーマンス、完全にGPU加速 |
| Mac Studio | 未知 | 34 → 6 | 1つのテストではコンテキストサイズの増加により性能が低下した |
| RTX 4080 | 969 | 12.45 | VRAMの制限により、78% CPU / 22% GPUに分離 |
モデル仕様:
- モデル:GPT-OSS 120b
- パラメータ:117B(Mixture-of-Expertsアーキテクチャ)
- 1パスあたりのアクティブパラメータ:5.1B
- 量子化:MXFP4
- モデルサイズ:65GB
これは、Qwen3:30bなどの他のMoEモデルとアーキテクチャが似ていますが、はるかに大規模なスケールです。
NVIDIA DGX Spark上のGPT-OSS 120b
NVIDIA DGX SparkのLLMパフォーマンスデータは、以下の「役に立つリンク」セクションに記載されている公式Ollamaブログ投稿から来ています。DGX Sparkは、NVIDIAが個人用AIスーパーコンピュータ市場に参入したものです。これは、大規模言語モデルを実行するために設計された128GBの統合メモリを備えています。

GPT-OSS 120bの生成パフォーマンスは41トークン/秒で非常に印象的です。これは、このモデルにとって明確な勝者であり、非常に大きなモデルにとってメモリ容量が実際に差を生むことを示しています。
しかし、中規模~大規模LLMのパフォーマンスは魅力的ではありません。これは特に、Qwen3:32bやLlama3.1:70bといったモデルで顕著です。これらのモデルでは、高RAM容量が光るはずですが、DGX Sparkでのパフォーマンスは価格のプレミアムに比べて魅力的ではありません。30~70Bパラメータのモデルに主に取り組んでいる場合は、適切に構成されたワークステーションや、48GB VRAMを持つQuadro RTX 5880 Adaを検討することをお勧めします。
Mac Studio Max上のGPT-OSS 120b
Youtubeチャンネル「Slinging Bits」は、Ollama上でGPT-OSS 120bを実行し、異なるコンテキストサイズでのテストを実施しました。その結果、モデルの生成速度がコンテキストサイズが増加するにつれて34トークン/秒からわずか6トークン/秒に急激に低下したという重大なパフォーマンス上の問題が明らかになりました。
このパフォーマンスの劣化は、メモリの圧力とmacOSが統合メモリアーキテクチャをどのように管理するかによるものと考えられます。Mac Studio Maxは、M2 Ultra構成では最大192GBの統合メモリを備えており、非常に印象的ですが、非常に大きなモデルが増加したコンテキスト負荷下での処理方法は、専用GPU VRAMと大きく異なります。


変動するコンテキスト長にわたって一貫したパフォーマンスが必要なアプリケーションでは、GPT-OSS 120bに関してはMac Studioが理想的ではありません。ただし、他のAIワークロードには非常に優れた能力を備えています。小さなモデルを使用するか、Ollamaの並列リクエスト処理機能を活用して、生産環境でのスループットを最大化することを検討してください。
RTX 4080上のGPT-OSS 120b
最初は、私のコンシューマーPCでOllamaとGPT-OSS 120bを実行した場合、特に興味深いものではないと考えていましたが、結果は私を楽しませてくれました。このクエリでテストした際の結果は以下の通りです:
$ ollama run gpt-oss:120b --verbose Compare the weather in state capitals of Australia
Thinking...
We need to compare weather in state capitals of Australia. Provide a comparison, perhaps include
...
*All data accessed September 2024; any updates from the BOM after that date may slightly adjust the
numbers, but the broad patterns remain unchanged.*
total duration: 4m39.942105769s
load duration: 75.843974ms
prompt eval count: 75 token(s)
prompt eval duration: 77.341981ms
prompt eval rate: 969.72 tokens/s
eval count: 3483 token(s)
eval duration: 4m39.788119563s
eval rate: 12.45 tokens/s
ここに興味深い点があります—このLLMを使用したOllamaは、主にCPU上で実行していました!モデルは16GB VRAMには収まらないため、OllamaはこれをシステムRAMにスマートにオフロードしています。ollama psコマンドを使用してこの動作を確認できます:
$ ollama ps
NAME ID SIZE PROCESSOR CONTEXT
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
78% CPU / 22% GPUの分割で実行しているにもかかわらず、RTX 4080はこの規模のモデルに対して非常に実用的なパフォーマンスを提供しています。プロンプト評価は969トークン/秒という非常に高速で、12.45トークン/秒という生成速度は多くのアプリケーションで使用可能です。
これは特に印象的です:
- モデルは利用可能なVRAMの4倍近くのサイズ
- 多くの計算はCPU上で行われる(これは私の64GBのシステムRAMに恩恵)
- OllamaがCPUコアを使用する方法を理解することで、この構成をさらに最適化できます
誰が予想したでしょう?コンシューマーGPUが117Bパラメータモデルを実行できるとは、ましてや実用的なパフォーマンスで!これはOllamaのスマートなメモリ管理の力と、十分なシステムRAMの重要性を示しています。Ollamaをアプリケーションに統合したい場合は、このガイドを参照してください:PythonでのOllamaの使用。
注意:これは実験やテストには適していますが、GPT-OSSにはいくつかのクセがあることに注意してください、特に構造化された出力形式に関して。
ベンチマーク、VRAMとCPUオフロードのトレードオフ、およびプラットフォームにわたるパフォーマンスチューニングについてさらに詳しく知りたい場合は、LLM Performance: Benchmarks, Bottlenecks & Optimizationのハブをご覧ください。
主な出典
- Ollama on NVIDIA DGX Spark: Performance Benchmarks - Ollama公式ブログ投稿でDGX Sparkのパフォーマンスデータを詳細に記載
- GPT-OSS 120B on Mac Studio - Slinging Bits YouTube - 多くのコンテキストサイズでGPT-OSS 120bをテストした詳細なビデオ
ハードウェア比較およびOllamaに関する関連記事
- DGX Spark vs. Mac Studio: NVIDIAの個人用AIスーパーコンピュータの実用的価格比較 - DGX Sparkの構成、グローバル価格、およびローカルAIワークのためのMac Studioとの直接比較
- NVIDIA DGX Spark - 期待 - DGX Sparkの初期のカバレッジ:利用可能性、価格、および技術仕様
- オーストラリアにおけるNVidia RTX 5080およびRTX 5090の価格 - 2025年10月 - 次世代コンシューマーGPUの現在の市場価格
- Quadro RTX 5880 Ada 48GBはAIワークロードに適しているか? - AIワークロードに向けた48GBワークステーションGPUの代替品のレビュー
- Ollamaチートシート - Ollamaのコマンドリファレンスとヒントの総合ガイド
P.S. 新しいデータ
この投稿を公開した後、NVIDIAのサイトでDGX SparkにおけるLLM推論に関するさらなる統計を発見しました:
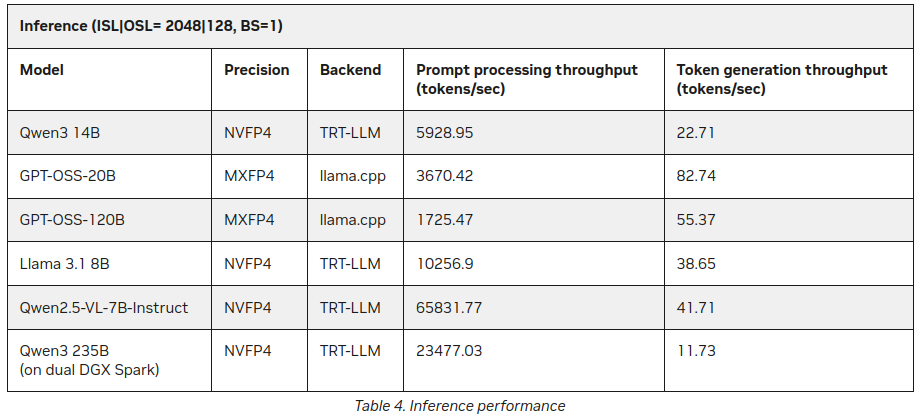
より良い結果ですが、上記の内容と大きく矛盾するわけではありません(55トークン vs 41)が、特にQwen3 235B(双DGX Spark上)が1秒あたり11以上のトークンを生成している点は興味深い追加情報です。
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
