
NVIDIA DGX Spark vs Mac Studio vs RTX-4080: Comparação de Desempenho do Ollama
Benchmark do GPT-OSS 120b em três plataformas de IA
Fiz uma pesquisa sobre alguns interessantes testes de desempenho do GPT-OSS 120b em execução no Ollama em três diferentes plataformas: NVIDIA DGX Spark, Mac Studio e RTX 4080. O modelo GPT-OSS 120b da biblioteca Ollama tem 65GB, o que significa que não cabe na VRAM de 16GB de um RTX 4080 (ou no mais recente RTX 5080).
Sim, o modelo pode ser executado com desempenho parcial offloadado para o CPU, e se você tiver 64GB de memória RAM do sistema (como eu tenho), você pode tentar. No entanto, esse setup não seria considerado nem perto de um desempenho adequado para produção. Para cargas de trabalho verdadeiramente exigentes, você pode precisar de algo como o NVIDIA DGX Spark, que foi especificamente desenvolvido para cargas de trabalho de IA de alta capacidade. Para mais sobre o desempenho de LLM—throughput vs latência, limites de VRAM e benchmarks em diferentes runtimes e hardware—veja Desempenho de LLM: Benchmarks, Bottlenecks & Otimização.

Eu esperava que esse LLM se beneficiasse significativamente ao ser executado em um “dispositivo de IA de alta memória” como o DGX Spark. Embora os resultados sejam bons, eles não são tão drasticamente melhores quanto você poderia esperar, considerando a diferença de preço entre o DGX Spark e opções mais acessíveis.
TL;DR
Ollama executando GPT-OSS 120b comparação de desempenho em três plataformas:
| Dispositivo | Desempenho de Avaliação de Prompt (tokens/sec) | Desempenho de Geração (tokens/sec) | Notas |
|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | Melhor desempenho geral, totalmente acelerado por GPU |
| Mac Studio | Desconhecido | 34 → 6 | Um teste mostrou degradação com aumento do tamanho do contexto |
| RTX 4080 | 969 | 12,45 | Divisão de 78% CPU / 22% GPU devido a limites de VRAM |
Especificações do modelo:
- Modelo: GPT-OSS 120b
- Parâmetros: 117B (arquitetura Mixture-of-Experts)
- Parâmetros ativos por passo: 5,1B
- Quantização: MXFP4
- Tamanho do modelo: 65GB
Isso é semelhante em arquitetura a outros modelos MoE, como Qwen3:30b, mas em uma escala muito maior.
GPT-OSS 120b no NVIDIA DGX Spark
Os dados de desempenho do LLM no NVIDIA DGX Spark vêm do post oficial do blog Ollama (linkado abaixo na seção de links úteis). O DGX Spark representa a entrada da NVIDIA no mercado de supercomputadores pessoais de IA, com 128GB de memória unificada especificamente projetada para executar modelos de linguagem grandes.

O desempenho do GPT-OSS 120b parece impressionante com 41 tokens/sec para geração. Isso o torna claramente o vencedor para este modelo específico, mostrando que a capacidade adicional de memória pode realmente fazer uma diferença para modelos extremamente grandes.
No entanto, o desempenho dos LLMs médios a grandes não parece tão convincente. Isso é particularmente notável com os modelos Qwen3:32b e Llama3.1:70b—exatamente os modelos onde você esperaria que a alta capacidade de memória brilhasse. O desempenho desses modelos no DGX Spark não é inspirador quando comparado ao溢价 de preço. Se você estiver trabalhando principalmente com modelos no intervalo de 30-70B de parâmetros, talvez você queira considerar alternativas como uma estação de trabalho bem configurada ou até mesmo um Quadro RTX 5880 Ada com seus 48GB de VRAM.
GPT-OSS 120b no Mac Studio Max
O canal de YouTube Slinging Bits conduziu testes abrangentes executando o GPT-OSS 120b no Ollama com tamanhos de contexto variáveis. Os resultados revelam uma preocupação significativa de desempenho: a velocidade de geração do modelo caiu drasticamente de 34 tokens/s para apenas 6 tokens/s à medida que o tamanho do contexto aumentava.
Essa degradação de desempenho é provavelmente devida à pressão de memória e à forma como o macOS gerencia a arquitetura de memória unificada. Embora o Mac Studio Max tenha uma memória unificada impressionante (até 192GB na configuração M2 Ultra), a forma como ele lida com modelos muito grandes sob cargas de contexto crescentes difere significativamente da VRAM de GPU dedicada.


Para aplicações que exigem desempenho consistente em diferentes comprimentos de contexto, isso torna o Mac Studio menos ideal para o GPT-OSS 120b, apesar de suas capacidades excelentes para cargas de trabalho de IA. Você pode ter mais sorte com modelos menores ou considere usar funcionalidades de manipulação de requisições paralelas do Ollama para maximizar o throughput em cenários de produção.
GPT-OSS 120b no RTX 4080
Inicialmente, pensei que executar o Ollama com o GPT-OSS 120b no meu PC de consumo não seria particularmente emocionante, mas os resultados me surpreenderam de forma agradável. Aqui está o que aconteceu quando testei com essa consulta:
$ ollama run gpt-oss:120b --verbose Compare the weather in state capitals of Australia
Pensando...
Precisamos comparar o clima nas capitais dos estados da Austrália. Forneça uma comparação, talvez inclua
...
*Todos os dados acessados em setembro de 2024; quaisquer atualizações do BOM após essa data podem levemente ajustar os
números, mas os padrões gerais permanecem inalterados.*
duração total: 4m39.942105769s
duração de carregamento: 75.843974ms
contagem de avaliação de prompt: 75 token(s)
duração de avaliação de prompt: 77.341981ms
taxa de avaliação de prompt: 969,72 tokens/s
contagem de avaliação: 3483 token(s)
duração de avaliação: 4m39.788119563s
taxa de avaliação: 12,45 tokens/s
Agora aqui está a parte interessante—Ollama com este LLM estava sendo executado principalmente no CPU! O modelo simplesmente não cabe na VRAM de 16GB, então o Ollama inteligentemente offloadou a maior parte dele para a memória RAM do sistema. Você pode ver esse comportamento usando o comando ollama ps:
$ ollama ps
NOME ID TAMANHO PROCESSADOR CONTEXTO
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
Apesar de estar sendo executado com uma divisão de 78% CPU / 22% GPU, o RTX 4080 ainda entrega um desempenho respeitável para um modelo desse tamanho. A avaliação do prompt é extremamente rápida, com 969 tokens/s, e mesmo a velocidade de geração de 12,45 tokens/s é utilizável para muitas aplicações.
Isso é particularmente impressionante quando você considera que:
- O modelo é quase 4 vezes maior que a VRAM disponível
- A maior parte da computação acontece no CPU (que beneficia-se da minha memória RAM de 64GB)
- Entender como o Ollama usa os núcleos do CPU pode ajudar a otimizar esse setup ainda mais
Quem diria que um GPU de consumo poderia lidar com um modelo de 117B de parâmetros, deixando de lado o desempenho útil? Isso demonstra o poder da inteligente gestão de memória do Ollama e a importância de ter uma quantidade suficiente de memória RAM do sistema. Se você estiver interessado em integrar o Ollama em suas aplicações, consulte este guia sobre usar o Ollama com Python.
Nota: Embora isso funcione para experimentação e testes, você notará alguns peculiaridades no GPT-OSS, especialmente com formatos de saída estruturada.
Para explorar mais benchmarks, trade-offs entre VRAM e offload de CPU, e ajustes de desempenho em diferentes plataformas, consulte nosso Desempenho de LLM: Benchmarks, Bottlenecks & Otimização hub.
Fontes Principais
- Ollama no NVIDIA DGX Spark: Benchmarks de Desempenho - Post oficial do blog Ollama com dados abrangentes de desempenho do DGX Spark
- GPT-OSS 120B no Mac Studio - Canal Slinging Bits no YouTube - Teste detalhado do GPT-OSS 120b com tamanhos de contexto variáveis
Leitura Relacionada sobre Comparação de Hardware e Ollama
- DGX Spark vs. Mac Studio: Uma Visão Prática, com Verificação de Preços, sobre o Supercomputador Pessoal de IA da NVIDIA - Explicação detalhada das configurações do DGX Spark, preços globais e comparação direta com o Mac Studio para trabalhos locais de IA
- NVIDIA DGX Spark - Antecipação - Cobertura inicial do DGX Spark: disponibilidade, preços e especificações técnicas
- Preços do NVidia RTX 5080 e RTX 5090 na Austrália - Outubro de 2025 - Preços atuais de mercado para GPUs de consumo da próxima geração
- O Quadro RTX 5880 Ada 48GB é bom? - Resenha da alternativa de GPU de 48GB para cargas de trabalho de IA
- Ollama cheatsheet - Referência completa de comandos e dicas para o Ollama
P.S. Novos Dados
Já depois de eu ter publicado este post, encontrei no site da NVIDIA algumas estatísticas adicionais sobre a inferência de LLM no DGX Spark:
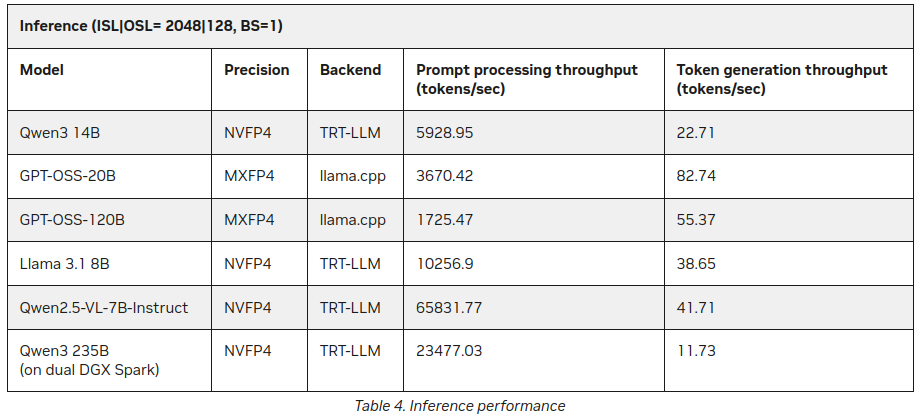
Melhor, mas não contradiz muito o que foi dito acima (55 tokens vs 41), mas é uma adição interessante, especialmente sobre Qwen3 235B (em duplo DGX Spark) produzindo 11+ tokens por segundo
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
