

Farfalle vs Perplexica
Comparando duas ferramentas de busca por IA auto-hospedadas
Comida incrível é um prazer para os olhos também. Mas neste post, vamos comparar dois sistemas de busca baseados em IA, Farfalle e Perplexica.
Comparando duas ferramentas de busca por IA auto-hospedadas
Comida incrível é um prazer para os olhos também. Mas neste post, vamos comparar dois sistemas de busca baseados em IA, Farfalle e Perplexica.

Qual linguagem usar para AWS Lambda?
Podemos escrever uma função lambda para implantação na AWS em vários idiomas. Vamos comparar o desempenho de (quase vazias) funções escritas em JavaScript, Python e Golang…
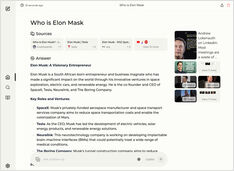
Executando um serviço do tipo copilot localmente? Fácil!
Isso é muito emocionante! Em vez de chamar o copilot ou perplexity.ai e contar ao mundo inteiro o que você está buscando, agora você pode hospedar um serviço semelhante no seu próprio PC ou laptop!
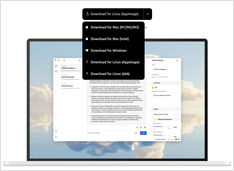
Não há tantas opções assim, mas ainda assim...
Quando comecei a experimentar com LLMs, as interfaces deles estavam em desenvolvimento ativo e agora algumas delas são realmente boas.

Testando a detecção de falácias lógicas
Recentemente, vimos a liberação de vários novos LLMs. Tempos emocionantes. Vamos testar e ver como eles se saem ao detectar falácias lógicas.

Requer algum experimento, mas
Ainda assim, existem algumas abordagens comuns para escrever prompts eficazes, de modo que os LLMs não fiquem confusos ao tentar entender o que você deseja.
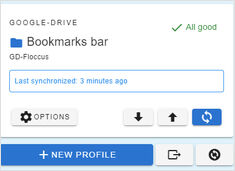
Sincronizar favoritos entre os laptops e navegadores?
Tentei diferentes ferramentas e cheguei à conclusão de que gosto mais do floccus.

Trechos frequentemente necessários de código Python
Às vezes preciso disso, mas não consigo encontrá-lo imediatamente.
Então, estou mantendo todos aqui.

A etiquetagem e o treinamento exigem algum colagem.
Quando eu treinei um detector de objetos AI há algum tempo - o LabelImg foi uma ferramenta muito útil, mas a exportação do Label Studio para o formato COCO não era aceita pela estrutura MMDetection..

8 versões do llama3 (Meta+) e 5 versões do phi3 (Microsoft) LLM
Testando como modelos com diferentes números de parâmetros e quantização estão se comportando.

Os arquivos do modelo LLM Ollama ocupam muito espaço.
Após instalar ollama é melhor reconfigurar ollama para armazená-los em um novo local imediatamente. Assim, após puxarmos um novo modelo, ele não será baixado para o local antigo.
É tão irritante assistir a todos aqueles anúncios
Você pode instalar um plugin ou extensão de bloqueio de anúncios no navegador para Google Chrome, Firefox ou Safari, mas terá que fazer isso em cada dispositivo.
O bloqueador de anúncios em toda a rede é minha solução favorita.
Mensagem de erro muito comum...
Após clonar o repositório git, faça a configuração do repositório local, especialmente defina o nome de usuário e o endereço de e-mail.

Hugo é um gerador de site estático
Quando o site é gerado com hugo, é hora de implantá-lo em alguma plataforma de hospedagem. Aqui está um tutorial sobre como enviá-lo para o AWS S3 e servir com o AWS CloudFront CDN.

Vamos testar a velocidade dos LLMs na GPU versus a CPU
Comparando a velocidade de previsão de várias versões de LLMs: llama3 (Meta/Facebook), phi3 (Microsoft), gemma (Google), mistral (open source) em CPU e GPU.

Vamos testar a qualidade de detecção de falácias lógicas de diferentes LLMs
Aqui estou comparando várias versões de LLM: Llama3 (Meta), Phi3 (Microsoft), Gemma (Google), Mistral Nemo (Mistral AI) e Qwen (Alibaba).