
Comparaison de la pertinence des GPU NVidia pour l'IA
L'IA nécessite beaucoup de puissance...
Dans le milieu du chaos du monde moderne ici, je compare les spécifications techniques de différentes cartes adaptées aux tâches IA
(Deep Learning,
Détection d’objets
et LLMs).
Elles sont toutes extrêmement chères toutefois.
Pour en savoir plus sur l’impact du choix du GPU sur le débit des LLM, les limites de VRAM et les benchmarks à travers les environnements d’exécution, consultez Performance des LLM : Benchmarks, Bottlenecks & Optimisation.

C’est une image générée par l’IA. Ne la prenez pas au sérieux…
Regardons d’autres options, juste pour explorer
| Carte | VRAM | Largeur de bus | Bande passante de mémoire | Cores CUDA | Cores Tensor | Puissance (W) |
|---|---|---|---|---|---|---|
| RTX 4060 Ti 16GB | 16 GB | 128-bit | 288 GB/s | 4,352 | 136 | 165 |
| RTX 4070 Ti 16GB | 16 GB | 256-bit | 672 GB/s | 7,680 | 240 | 285 |
| RTX 4080 16GB | 16 GB | 256-bit | 716,8 GB/s | 9,728 | 304 | 320 |
| RTX 4080 Super 16GB | 16 GB | 256-bit | 736 GB/s | 10,240 | 320 | 320 |
| RTX 4090 24GB | 24 GB | 384-bit | 1008 GB/s | 16,384 | 512 | 450 |
| RTX 5060 Ti 16GB | 16 GB | 128-bit | 448 GB/s | 4,608 | 144 | 180 |
| RTX 5070 Ti 16GB | 16 GB | 256-bit | 896 GB/s | 8,960 | 280 | 300 |
| RTX 5080 16GB | 16 GB | 256-bit | 896 GB/s | 10,752 | 336 | ~320 |
| RTX 5090 32GB | 32 GB | 512-bit | 1792 GB/s | 21,760 | 680 | ~450 |
| RTX 2000 Ada | 16 GB | 128-bit | 224 GB/s | 2,816 | 88 | 70 |
| RTX 4000 Ada | 20 GB | 160-bit | 280 GB/s | 6,144 | 192 | 70 |
| RTX 4500 Ada | 24 GB | 192-bit | 432 GB/s | 7,680 | 240 | 210 |
| RTX 5000 Ada | 32 GB | 256-bit | 576 GB/s | 12,800 | 400 | 250 |
| RTX 6000 Ada | 48 GB | 384-bit | 960 GB/s | 18,176 | 568 | 300 |
Bande passante de mémoire :
- RTX 5090 (1792 GB/s), puis RTX 4090 (1008 GB/s), puis RTX 6000 Ada (960 GB/s)
Cores Tensor :
- RTX 5090 (680), puis RTX 6000 Ada (568), puis RTX 4090 (512)
Cores CUDA :
- RTX 5090 (21 760), puis RTX 6000 Ada (18 176), puis RTX 4090 (16 384)
RAM :
- RTX 6000 Ada (48 GB), puis RTX 5090 et RTX 5000 Ada (32 GB), puis RTX 4090 (24 GB)
Prix en Australie
- RTX 6000 Ada : 12 000 AUD
- RTX 5090 : 6 000 AUD
- RTX 5000 Ada : 7 000 AUD
- RTX 4090 : épuisé
Meilleur GPU de consommation pour les LLM
Pourtant, je pense que le RTX 5090 serait toujours le meilleur choix pour le machine learning, le deep learning, l’IA et même les LLM :)
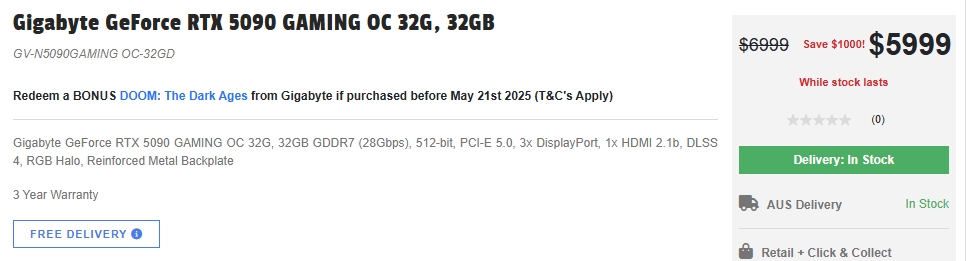
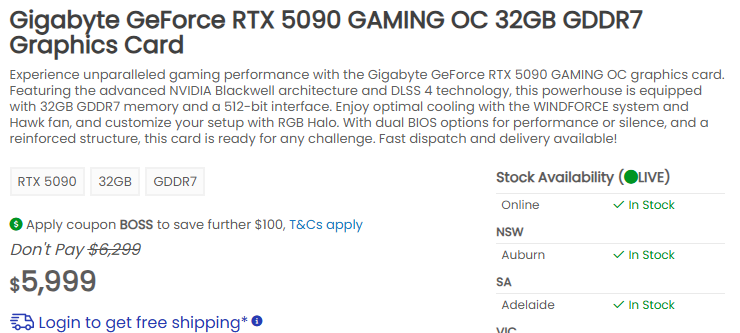
Prix réels
Un peu cher…

Et les prix réels du RTX 5090 sont 50 % plus élevés que prévu. Regardez cela !
C’est le 15/05/2025
Pour explorer les benchmarks des LLM, les exigences en VRAM et l’optimisation de la performance sur différentes cartes graphiques et environnements d’exécution, consultez notre Performance des LLM : Benchmarks, Bottlenecks & Optimisation.
