
Modelos de Embedding e Reranker do Qwen3 no Ollama: Desempenho de Estado da Arte
Novos LLMs incríveis disponíveis no Ollama
Os modelos Qwen3 Embedding e Reranker são as últimas liberações da família Qwen, especificamente projetados para tarefas avançadas de embedding de texto, recuperação e reclassificação.
Alegria para o olho
Os modelos Qwen3 Embedding e Reranker representam um avanço significativo no processamento de linguagem natural (NLP) multilíngue, oferecendo desempenho de ponta em tarefas de embedding e reclassificação de texto. Esses modelos, parte da série Qwen desenvolvida pela Alibaba, foram projetados para suportar uma ampla gama de aplicações, desde a recuperação semântica até a busca de código. Embora o Ollama seja uma plataforma popular de código aberto para hospedagem e implantação de modelos de linguagem grandes (LLMs), a integração dos modelos Qwen3 com o Ollama não está explicitamente detalhada na documentação oficial. No entanto, os modelos estão acessíveis via Hugging Face, GitHub e ModelScope, permitindo a implantação local potencial através do Ollama ou ferramentas semelhantes.
Exemplos usando esses modelos
Veja um exemplo de código em Go usando ollama com esses modelos:
- Reclassificação de documentos de texto com Ollama e modelo Qwen3 Embedding - em Go
- Reclassificação de documentos de texto com Ollama e modelo Qwen3 Reranker - em Go
Visão geral dos novos modelos Qwen3 Embedding e Reranker no Ollama
Esses modelos estão agora disponíveis para implantação no Ollama em várias tamanhos, oferecendo desempenho de ponta e flexibilidade para uma ampla gama de aplicações relacionadas a linguagem e código.
Principais características e capacidades
-
Tamanhos do modelo e flexibilidade
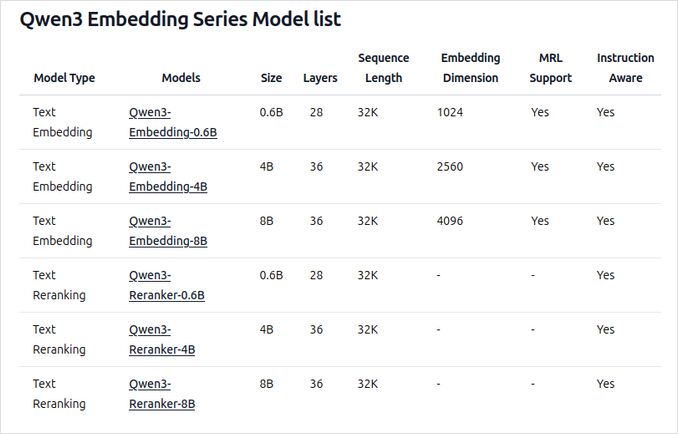
- Disponíveis em vários tamanhos: 0,6B, 4B e 8B parâmetros para ambas as tarefas de embedding e reclassificação.
- O modelo de embedding de 8B atualmente ocupa a posição número 1 no leaderboard multilíngue MTEB (até 5 de junho de 2025, com uma pontuação de 70,58).
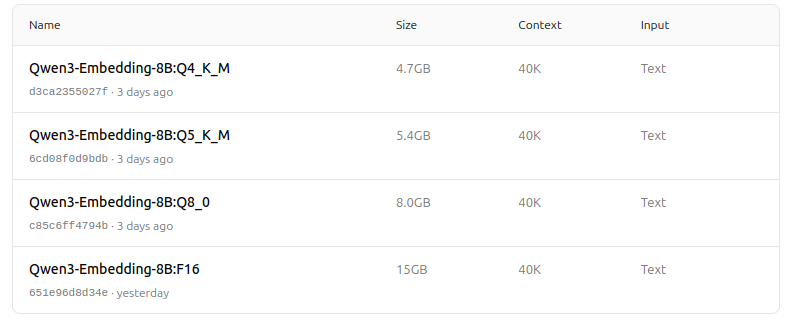
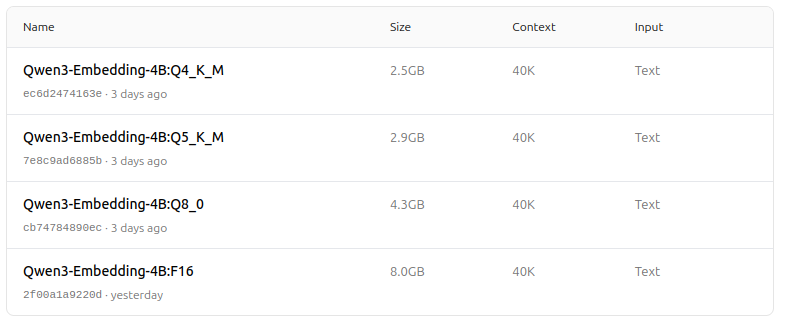
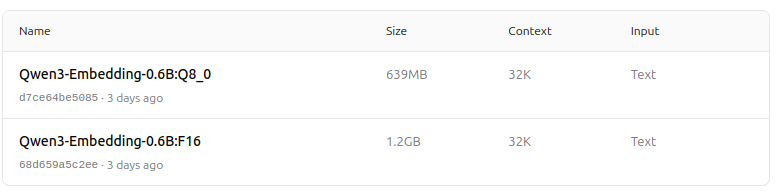
- Suporta uma gama de opções de quantização (Q4, Q5, Q8, etc.) para equilibrar desempenho, uso de memória e velocidade. O Q5_K_M é recomendado para a maioria dos usuários, pois preserva a maioria do desempenho do modelo enquanto é eficiente em recursos.
-
Arquitetura e treinamento
- Construído sobre a base Qwen3, aproveitando tanto a arquitetura dual-encoder (para embeddings) quanto a arquitetura cross-encoder (para reclassificação).
- Modelo de embedding: Processa segmentos de texto únicos, extraídos representações semânticas do estado oculto final.
- Modelo de reclassificação: Recebe pares de texto (por exemplo, consulta e documento) e produz uma pontuação de relevância usando uma abordagem cross-encoder.
- Modelos de embedding usam um paradigma de treinamento em três etapas: pré-treinamento contrastivo, treinamento supervisionado com dados de alta qualidade e fusão de modelos para generalização e adaptabilidade ótimas.
- Modelos de reclassificação são treinados diretamente com dados rotulados de alta qualidade para eficiência e eficácia.
-
Suporte multilíngue e multitarefa
- Suporta mais de 100 idiomas, incluindo linguagens de programação, permitindo capacidades robustas de recuperação multilíngue, cross-lingual e de código.
- Modelos de embedding permitem definições flexíveis de vetores e instruções definidas pelo usuário para personalizar o desempenho para tarefas ou idiomas específicos.
-
Desempenho e casos de uso
- Resultados de ponta em recuperação de texto, recuperação de código, classificação, agrupamento e mineração de bitexto.
- Modelos de reclassificação excelentes em diversos cenários de recuperação de texto e podem ser combinados de forma seamles com modelos de embedding para pipelines de recuperação end-to-end.
Como usar no Ollama
Você pode executar esses modelos no Ollama com comandos como:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Escolha a versão de quantização que melhor se adapte às necessidades de hardware e desempenho.
Tabela resumo
| Tipo de modelo | Tamanhos disponíveis | Principais vantagens | Suporte multilíngue | Opções de quantização |
|---|---|---|---|---|
| Embedding | 0,6B, 4B, 8B | Pontuação MTEB de ponta, flexível, eficiente, SOTA | Sim (mais de 100 idiomas) | Q4, Q5, Q6, Q8, etc. |
| Reranker | 0,6B, 4B, 8B | Excelente em relevância de pares de texto, eficiente, flexível | Sim | F16, Q4, Q5, etc. |
Notícia incrível!
Os modelos Qwen3 Embedding e Reranker no Ollama representam um salto significativo nas capacidades de recuperação de texto e código multilíngue e multitarefa. Com opções flexíveis de implantação, desempenho forte em benchmarks e suporte para uma ampla gama de idiomas e tarefas, eles são ideais para ambientes de pesquisa e produção.
Zoológico de modelos - prazer para o olho agora
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
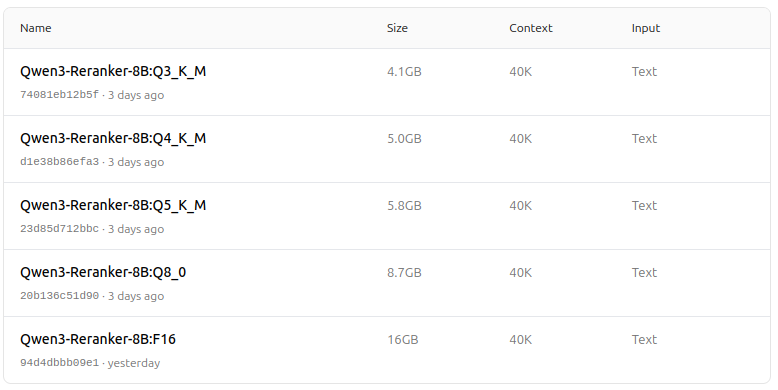
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
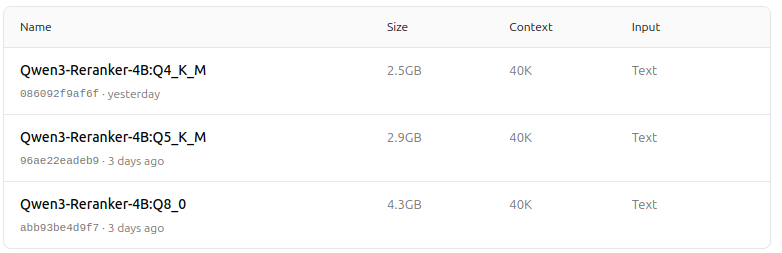
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
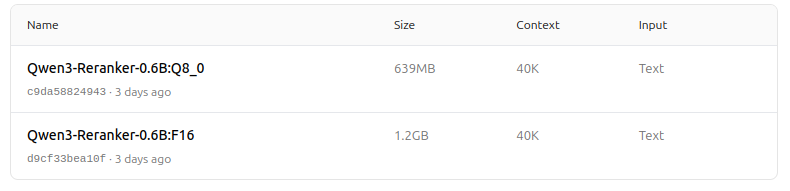
Legal!
Links úteis
- Reclassificação de documentos de texto com Ollama e modelo Qwen3 Embedding - em Go
- Reclassificação de documentos de texto com Ollama e modelo Qwen3 Reranker - em Go
- Ollama cheatsheet
- Mover modelos Ollama para um disco ou pasta diferente
- Auto-hospedagem do Perplexica - com Ollama
- Teste: Como Ollama está usando o desempenho da CPU Intel e núcleos eficientes
- Velocidade de desempenho dos LLM
- Comparação das capacidades de resumo dos LLM
- Fornecedores de LLM em nuvem
- Como o Ollama lida com solicitações paralelas
- Comparação da qualidade de tradução de páginas Hugo - LLMs no Ollama
