LLM Self-Hosting en AI Soevereiniteit
Beheer gegevens en modellen met self-hosted LLMs
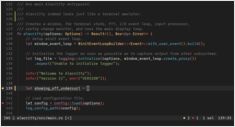
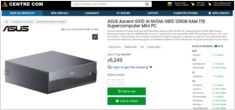
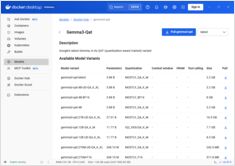
Self-hosting van LLMs houdt gegevens, modellen en inferentie onder jouw controle - een praktische weg naar AI-sovereiniteit voor teams, bedrijven en landen.
Hier: wat AI-sovereiniteit is, welke aspekten en methoden worden gebruikt om het te bouwen, hoe LLM self-hosting erin past en hoe landen het probleem aanpakken.