

RAM价格飙升:2025年涨幅高达619%
“由于人工智能需求导致供应紧张,RAM价格暴涨163%至619%”
2025年下半段,内存市场正经历前所未有的价格波动,所有细分市场中RAM价格均出现大幅上涨。
“由于人工智能需求导致供应紧张,RAM价格暴涨163%至619%”
2025年下半段,内存市场正经历前所未有的价格波动,所有细分市场中RAM价格均出现大幅上涨。

从代码注释自动生成 OpenAPI 文档
API 文档对于任何现代应用程序都至关重要,对于 Go APIs Swagger(OpenAPI)已成为行业标准。 对于 Go 开发人员来说,swaggo 提供了一种优雅的解决方案,可以直接从代码注释生成全面的 API 文档。

掌握本地LLM部署,对比12+工具
本地部署大型语言模型 随着开发人员和组织寻求增强的隐私性、减少延迟和对AI基础设施的更大控制权,变得越来越流行。

用 linters 和自动化工具掌握 Go 代码质量
现代 Go 开发要求严格的代码质量标准。Go 的 Linter 在代码进入生产环境之前,会自动检测 bug、安全漏洞和风格不一致的问题。

使用现代代码检查工具掌握 Python 代码质量
Python linters 是必不可少的工具,它们可以在不执行代码的情况下分析代码中的错误、风格问题和潜在的 bug。 它们强制执行编码标准,提高可读性,并帮助团队维护高质量的代码库。

跨平台掌握行尾符转换
Windows和Linux之间的换行符不一致系统会导致格式问题、Git警告和脚本失败。 本综合指南涵盖检测、转换和预防策略。

适合人工智能的消费级显卡价格 - RTX 5080 和 RTX 5090
让我们比较顶级消费级GPU的价格,这些GPU特别适合LLMs,也适用于AI整体。 具体来说,我正在查看 RTX-5080和RTX-5090价格。

使用 Go 微服务构建强大的 AI/ML 管道
随着人工智能和机器学习工作负载变得越来越复杂,对强大的编排系统的需求也变得更为迫切。Go语言的简洁性、性能和并发特性使其成为构建机器学习流水线的编排层的理想选择,即使模型本身是用Python编写的。

创建Markdown表格的完整指南
表格是 Markdown 中用于组织和呈现结构化数据的最强大功能之一。 无论您是在创建技术文档、README 文件还是博客文章,了解如何正确格式化表格都可以显著提高内容的可读性和专业性。
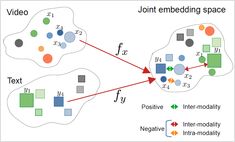
在共享的嵌入空间中统一文本、图像和音频
跨模态嵌入 代表了人工智能领域的一项突破,它使不同数据类型能够在统一的表示空间中实现理解和推理。

高效地将 LaTeX 文档转换为 Markdown
将LaTeX文档转换为Markdown已成为现代出版工作流程中的关键环节,它能够整合静态站点生成器、文档平台和版本控制系统,同时保持可读性和简洁性。

从代码到 PyPI 部署,掌握 Python 包管理
Python打包 已经有了显著的发展,现代工具和标准使得分发你的代码比以往任何时候都更容易。

在预算硬件上部署企业级AI,使用开放模型
人工智能的民主化已经到来。
借助像 Llama 3、Mixtral 和 Qwen 这样的开源大语言模型(LLM),团队现在可以使用消费级硬件构建强大的 AI 基础设施 - 在降低成本的同时,仍能完全控制数据隐私和部署。

用先进的反指纹技术保护您的隐私
在现代网络中,您的数字身份可以通过复杂的数字指纹追踪技术,在不使用 cookie 或明确同意的情况下被追踪。

使用Prometheus建立强大的基础设施监控系统
Prometheus 已成为监控云原生应用程序和基础设施的实际标准,提供指标收集、查询和与可视化工具的集成。

LongRAG、Self-RAG、GraphRAG - 下一代技术
检索增强生成(RAG) 已经远远超越了简单的向量相似性搜索。 LongRAG、Self-RAG 和 GraphRAG 代表了这些能力的前沿。