
NVIDIA DGX Spark vs Mac Studio vs RTX-4080 : Comparaison des performances d'Ollama
Benchmarks GPT-OSS 120b sur trois plateformes d'IA
J’ai découvert des tests de performance intéressants sur l’exécution du modèle GPT-OSS 120b avec Ollama sur trois plateformes différentes : NVIDIA DGX Spark, Mac Studio, et RTX 4080. Le modèle GPT-OSS 120b de la bibliothèque Ollama pèse 65 Go, ce qui signifie qu’il ne peut pas s’exécuter dans les 16 Go de VRAM d’un RTX 4080 (ou sur le plus récent RTX 5080).
Oui, le modèle peut s’exécuter avec un déchargement partiel vers le CPU, et si vous avez 64 Go de RAM système (comme je l’ai), vous pouvez le tester. Cependant, ce type de configuration ne serait pas considéré comme étant prêt pour la production. Pour des charges de travail vraiment exigeantes, vous pourriez avoir besoin de quelque chose comme le NVIDIA DGX Spark, qui est spécifiquement conçu pour les charges de travail d’IA à grande capacité. Pour plus d’informations sur les performances des LLM – débit vs latence, limites de VRAM, et benchmarks sur différents runtimes et matériels – consultez LLM Performance: Benchmarks, Bottlenecks & Optimization.

J’attendais que ce LLM bénéficie considérablement de l’exécution sur un appareil à « grande mémoire d’IA » comme le DGX Spark. Bien que les résultats soient bons, ils ne sont pas aussi nettement meilleurs que vous pourriez vous y attendre compte tenu de la différence de prix entre le DGX Spark et des options plus abordables.
TL;DR
Ollama exécutant GPT-OSS 120b comparaison des performances sur trois plateformes :
Appareil | Performance d’évaluation des prompts (tokens/sec) | Performance de génération (tokens/sec) | Notes —|—|-|–|- – NVIDIA DGX Spark | 1159 | 41 | Meilleure performance globale, entièrement accélérée par le GPU Mac Studio | Inconnue | 34 → 6 | Un test a montré une dégradation avec l’augmentation de la taille du contexte RTX 4080 | 969 | 12,45 | 78 % CPU / 22 % GPU en raison des limites de VRAM
Spécifications du modèle :
- Modèle : GPT-OSS 120b
- Paramètres : 117B (architecture Mixture-of-Experts)
- Paramètres actifs par passe : 5,1B
- Quantification : MXFP4
- Taille du modèle : 65 Go
C’est similaire à l’architecture d’autres modèles MoE comme Qwen3:30b, mais à une échelle bien plus grande.
GPT-OSS 120b sur NVIDIA DGX Spark
Les données de performance du LLM sur le NVIDIA DGX Spark proviennent d’un article de blog officiel d’Ollama (lien ci-dessous dans la section « Liens utiles »). Le DGX Spark représente l’entrée de NVIDIA sur le marché des superordinateurs d’IA personnels, doté de 128 Go de mémoire unifiée spécifiquement conçue pour exécuter des modèles de langage de grande taille.

La performance de génération du GPT-OSS 120b semble impressionnante à 41 tokens/sec. Cela en fait clairement le gagnant pour ce modèle particulier, montrant que la capacité mémoire supplémentaire peut vraiment faire la différence pour les modèles extrêmement grands.
Cependant, les performances des LLM de taille moyenne à grande ne sont pas aussi convaincantes. Cela est particulièrement visible avec Qwen3:32b et Llama3.1:70b – exactement les modèles où l’on s’attendrait à ce que la grande capacité de mémoire brille. Les performances de ces modèles sur le DGX Spark ne sont pas inspirantes par rapport au prix premium. Si vous travaillez principalement avec des modèles dans la fourchette de 30 à 70 milliards de paramètres, vous pourriez envisager des alternatives comme un ordinateur de travail bien configuré ou même un Quadro RTX 5880 Ada avec ses 48 Go de VRAM.
GPT-OSS 120b sur Mac Studio Max
Le canal YouTube Slinging Bits a effectué des tests approfondis de l’exécution du GPT-OSS 120b avec Ollama sur différentes tailles de contexte. Les résultats révèlent une préoccupation de performance significative : la vitesse de génération du modèle est tombée de 34 tokens/s à seulement 6 tokens/s à mesure que la taille du contexte augmentait.
Cette dégradation de performance est probablement due à la pression mémoire et à la manière dont macOS gère l’architecture de mémoire unifiée. Bien que le Mac Studio Max ait une mémoire unifiée impressionnante (jusqu’à 192 Go dans la configuration M2 Ultra), la manière dont il gère les très grands modèles sous des charges de contexte croissantes diffère considérablement de la VRAM dédiée du GPU.


Pour les applications nécessitant une performance constante sur différentes longueurs de contexte, cela rend le Mac Studio moins idéal pour le GPT-OSS 120b, malgré ses capacités excellentes pour les charges de travail d’IA. Vous pourriez avoir plus de chance avec des modèles plus petits ou envisager d’utiliser les fonctionnalités de gestion des requêtes parallèles d’Ollama ici pour maximiser le débit dans les scénarios de production.
GPT-OSS 120b sur RTX 4080
J’ai initialement pensé que l’exécution d’Ollama avec le GPT-OSS 120b sur mon PC de consommation ne serait pas particulièrement excitante, mais les résultats m’ont agréablement surpris. Voici ce qui s’est produit lors de mes tests avec cette requête :
$ ollama run gpt-oss:120b --verbose Compare the weather in state capitals of Australia
Thinking...
We need to compare weather in state capitals of Australia. Provide a comparison, perhaps include
...
*All data accessed September 2024; any updates from the BOM after that date may slightly adjust the
numbers, but the broad patterns remain unchanged.*
total duration: 4m39.942105769s
load duration: 75.843974ms
prompt eval count: 75 token(s)
prompt eval duration: 77.341981ms
prompt eval rate: 969.72 tokens/s
eval count: 3483 token(s)
eval duration: 4m39.788119563s
eval rate: 12.45 tokens/s
Maintenant, voici ce qui est intéressant – Ollama avec ce LLM s’exécutait principalement sur le CPU ! Le modèle ne tient simplement pas dans les 16 Go de VRAM, donc Ollama a intelligemment transféré la plupart de lui-même vers la mémoire système. Vous pouvez observer ce comportement à l’aide de la commande ollama ps :
$ ollama ps
NAME ID SIZE PROCESSOR CONTEXT
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
Malgré une répartition de 78 % CPU / 22 % GPU, le RTX 4080 livre néanmoins des performances respectables pour un modèle de cette taille. L’évaluation des prompts est extrêmement rapide à 969 tokens/s, et même la vitesse de génération de 12,45 tokens/s est utilisable pour de nombreuses applications.
Cela est particulièrement impressionnant si l’on considère que :
- Le modèle est presque 4 fois plus grand que la VRAM disponible
- La plupart des calculs ont lieu sur le CPU (ce qui profite de mes 64 Go de RAM système)
- Comprendre comment Ollama utilise les cœurs du CPU peut aider à optimiser davantage ce setup
Qui aurait cru qu’un GPU de consommation puisse gérer un modèle de 117 milliards de paramètres, encore moins avec une performance utilisable ? Cela démontre la puissance de la gestion intelligente de la mémoire d’Ollama et l’importance d’avoir suffisamment de RAM système. Si vous souhaitez intégrer Ollama dans vos applications, consultez ce guide sur l’utilisation d’Ollama avec Python.
Note : Bien que cela fonctionne pour l’expérimentation et les tests, vous remarquerez que GPT-OSS peut avoir quelques particularités, notamment avec les formats de sortie structurée.
Pour explorer davantage de benchmarks, les compromis entre déchargement de VRAM et CPU, et l’optimisation des performances sur différentes plateformes, consultez notre LLM Performance: Benchmarks, Bottlenecks & Optimization.
Sources primaires
- Ollama sur NVIDIA DGX Spark : Benchmarks de performance - Article de blog officiel d’Ollama avec des données de performance DGX Spark complètes
- GPT-OSS 120B sur Mac Studio – Slinging Bits YouTube - Vidéo détaillée testant GPT-OSS 120b avec différentes tailles de contexte
Lecture complémentaire sur les comparaisons matérielles et Ollama
- DGX Spark vs. Mac Studio : Une vue pratique et vérifiée en prix sur le superordinateur d’IA personnel de NVIDIA - Explication détaillée des configurations DGX Spark, des prix mondiaux, et de la comparaison directe avec le Mac Studio pour le travail local d’IA
- NVIDIA DGX Spark – Anticipation - Couverture précoce du DGX Spark : disponibilité, prix, et spécifications techniques
- Prix du RTX 5080 et du RTX 5090 en Australie – Octobre 2025 - Prix actuels du prochain génération de GPU de consommation
- Le Quadro RTX 5880 Ada 48GB est-il bon pour les charges de travail d’IA ? - Avis sur le GPU de travail alternatif de 48 Go pour les charges de travail d’IA
- Ollama cheatsheet - Référence complète des commandes et conseils pour Ollama
P.S. Nouveaux données
Déjà après avoir publié cet article, j’ai trouvé sur le site NVIDIA quelques statistiques supplémentaires sur l’inférence des LLM sur le DGX Spark :
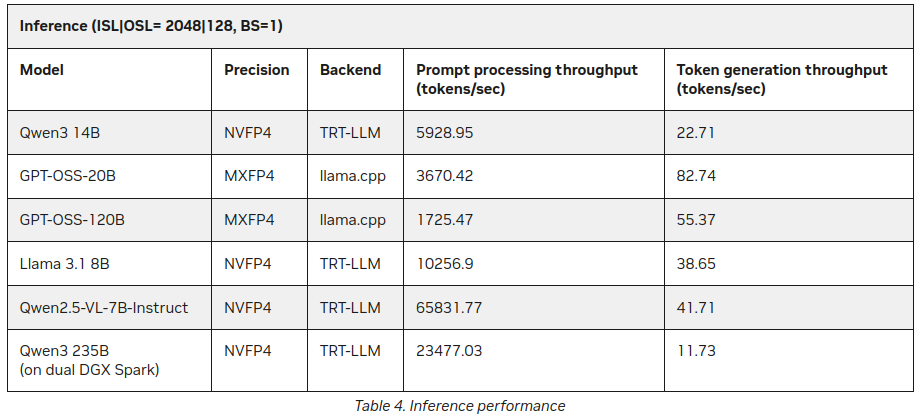
Meilleures, mais pas contradictoires avec ce qui a été dit ci-dessus (55 tokens vs 41), mais c’est une addition intéressante, surtout concernant Qwen3 235B (sur dual DGX Spark) produisant 11+ tokens/seconde
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
