
Modèles d'embedding et de réorganisation Qwen3 sur Ollama : une performance d'avant-garde
Nouveaux LLMs impressionnants disponibles dans Ollama
Les modèles Qwen3 Embedding and Reranker sont les dernières sorties de la famille Qwen, spécifiquement conçus pour des tâches avancées d’embedding de texte, de récupération et de réordonnancement.
Joie pour l’œil
Les modèles Qwen3 Embedding and Reranker représentent un progrès significatif dans le traitement du langage naturel (NLP) multilingue, offrant des performances d’avant-garde dans les tâches d’embedding et de réordonnancement de texte. Ces modèles, faisant partie de la série Qwen développée par Alibaba, sont conçus pour soutenir un large éventail d’applications, allant de la récupération sémantique à la recherche de code. Bien que Ollama soit une plateforme open source populaire pour l’hébergement et le déploiement de grands modèles de langage (LLMs), l’intégration des modèles Qwen3 avec Ollama n’est pas explicitement détaillée dans la documentation officielle. Cependant, les modèles sont accessibles via Hugging Face, GitHub et ModelScope, permettant un déploiement local potentiel via Ollama ou des outils similaires.
Exemples d’utilisation de ces modèles
Veuillez consulter le code d’exemple en Go utilisant Ollama avec ces modèles :
- Réordonnancement de documents texte avec Ollama et modèle Qwen3 Embedding - en Go
- Réordonnancement de documents texte avec Ollama et modèle Qwen3 Reranker - en Go
Aperçu des nouveaux modèles Qwen3 Embedding and Reranker sur Ollama
Ces modèles sont désormais disponibles pour le déploiement sur Ollama en différentes tailles, offrant des performances d’avant-garde et une flexibilité pour un large éventail d’applications liées au langage et au code.
Fonctionnalités et capacités clés
-
Tailles de modèles et flexibilité
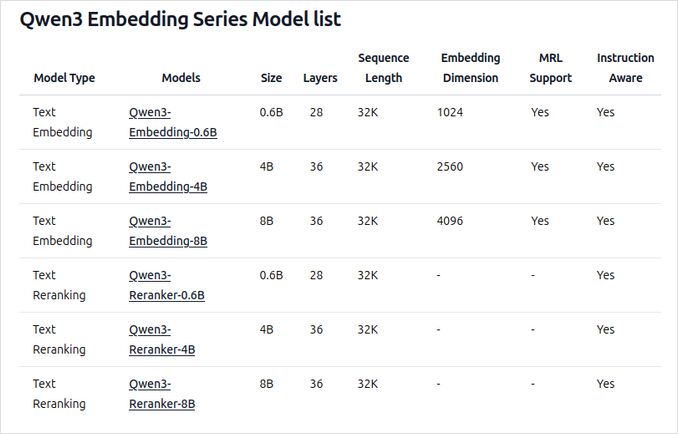
- Disponibles en plusieurs tailles : 0,6B, 4B et 8B de paramètres pour les tâches d’embedding et de réordonnancement.
- Le modèle d’embedding 8B se classe actuellement en tête du classement multilingue MTEB (au 5 juin 2025, avec une note de 70,58).
- Prend en charge une gamme d’options de quantification (Q4, Q5, Q8, etc.) pour équilibrer les performances, l’utilisation de la mémoire et la vitesse. Q5_K_M est recommandé pour la plupart des utilisateurs car il préserve la plupart des performances du modèle tout en étant efficace en termes de ressources.
-
Architecture et entraînement
- Construits sur la base Qwen3, utilisant à la fois des architectures dual-encoder (pour les embeddings) et cross-encoder (pour le réordonnancement).
- Modèle d’embedding : traite des segments de texte individuels, extrayant des représentations sémantiques à partir de l’état caché final.
- Modèle de réordonnancement : prend en charge des paires de texte (par exemple, requête et document) et produit un score de pertinence à l’aide d’une approche cross-encoder.
- Les modèles d’embedding utilisent un paradigme d’entraînement en trois étapes : entraînement contrastif, entraînement supervisé avec des données de haute qualité, et fusion de modèles pour une généralisation et une adaptabilité optimales.
- Les modèles de réordonnancement sont entraînés directement avec des données étiquetées de haute qualité pour une efficacité et une efficacité accrues.
-
Support multilingue et multitâche
- Prend en charge plus de 100 langues, y compris les langages de programmation, permettant des capacités robustes de récupération multilingue, interlingue et de code.
- Les modèles d’embedding permettent des définitions de vecteurs flexibles et des instructions définies par l’utilisateur pour adapter les performances à des tâches ou langues spécifiques.
-
Performances et cas d’utilisation
- Résultats d’avant-garde dans la récupération de texte, de code, de classification, de regroupement et d’extraction de paires de texte.
- Les modèles de réordonnancement excellent dans divers scénarios de récupération de texte et peuvent être combinés de manière fluide avec les modèles d’embedding pour des pipelines de récupération end-to-end.
Comment les utiliser sur Ollama
Vous pouvez exécuter ces modèles sur Ollama avec des commandes comme :
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Choisissez la version de quantification qui convient le mieux à vos besoins matériels et en termes de performance.
Tableau récapitulatif
| Type de modèle | Tailles disponibles | Forces clés | Support multilingue | Options de quantification |
|---|---|---|---|---|
| Embedding | 0,6B, 4B, 8B | Meilleurs scores MTEB, flexibles, efficaces, SOTA | Oui (100+ langues) | Q4, Q5, Q6, Q8, etc. |
| Reranker | 0,6B, 4B, 8B | Excelle dans la pertinence des paires de texte, efficace, flexible | Oui | F16, Q4, Q5, etc. |
Bonnes nouvelles !
Les modèles Qwen3 Embedding and Reranker sur Ollama représentent un bond significatif dans les capacités de récupération multilingue et multitâche de texte et de code. Avec des options de déploiement flexibles, de fortes performances de benchmark et un support pour un large éventail de langues et de tâches, ils sont bien adaptés aux environnements de recherche et de production.
Zoo de modèles - un plaisir pour l’œil maintenant
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
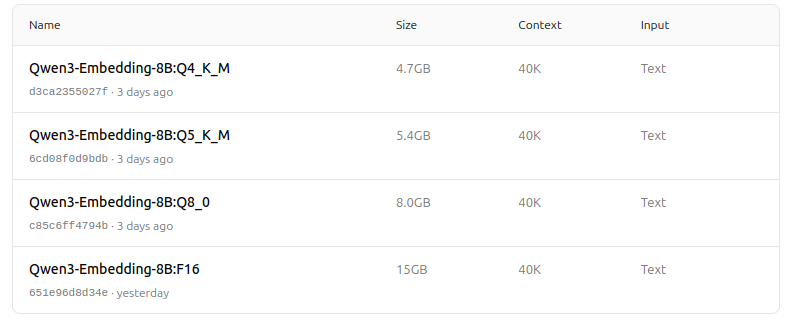
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
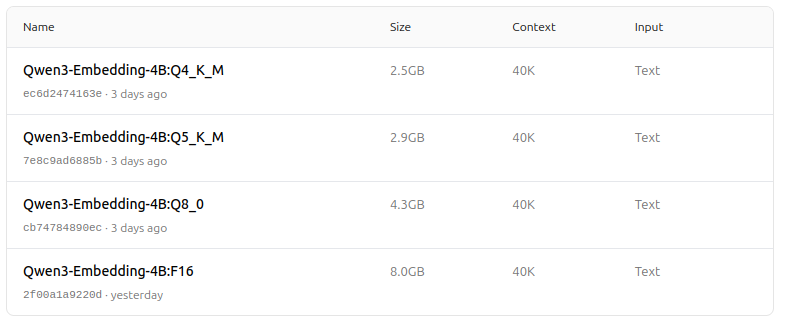
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
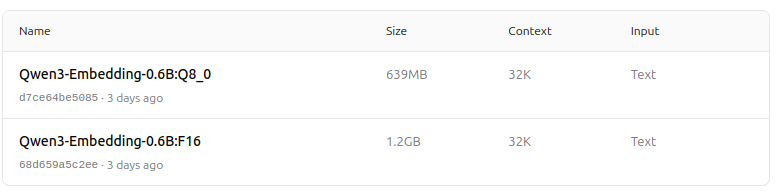
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
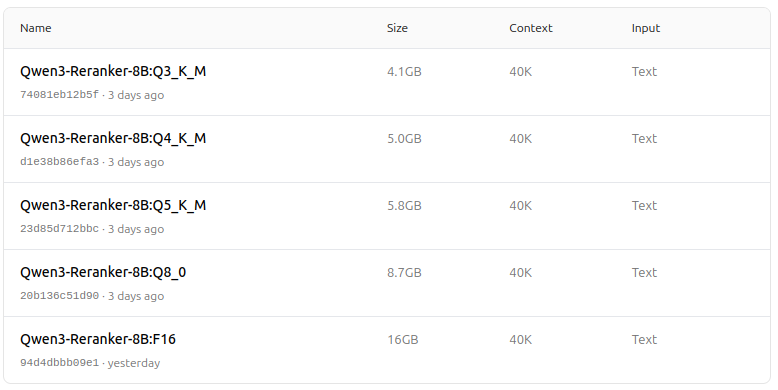
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
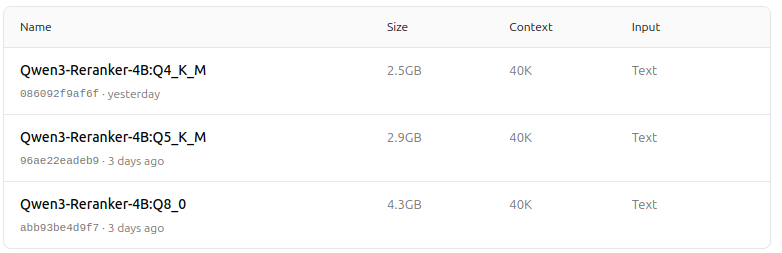
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
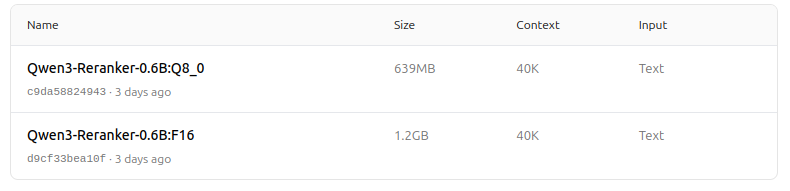
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
Très bien !
Liens utiles
- Réordonnancement de documents texte avec Ollama et modèle Qwen3 Embedding - en Go
- Réordonnancement de documents texte avec Ollama et modèle Qwen3 Reranker - en Go
- Ollama cheatsheet
- Déplacer les modèles Ollama vers un autre disque ou dossier
- Auto-hébergement de Perplexica - avec Ollama
- Test : Comment Ollama utilise les performances du processeur Intel et les cœurs efficaces
- Comparaison de la vitesse des modèles LLM
- Comparaison des capacités de résumé des LLM
- Fournisseurs de modèles LLM en nuage
- Comment Ollama gère les requêtes parallèles
- Comparaison de la qualité de traduction des pages Hugo - LLMs sur Ollama
