
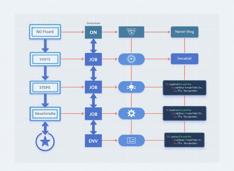
GitHub Actions 快速参考 - 标准结构和最有用的操作列表
关于常见 GitHub Actions 及其结构的简要介绍。
GitHub Actions 是 GitHub 内部的一个自动化和 CI/CD 平台,用于根据推送、拉取请求或定时任务等事件构建、测试和部署代码。
关于常见 GitHub Actions 及其结构的简要介绍。
GitHub Actions 是 GitHub 内部的一个自动化和 CI/CD 平台,用于根据推送、拉取请求或定时任务等事件构建、测试和部署代码。

顺便说一下,docker-compose 与 docker compose 是不同的……
以下是 Docker Compose 快速参考 ,包含注释示例,帮助您快速掌握 Compose 文件和命令。
关于 Obsidian ...
以下是关于
Obsidian 作为强大的 个人知识管理 (PKM) 工具
的详细分析,解释其架构、功能、优势以及它如何支持现代知识工作流程。

2025年7月,它应该很快就会发布。
NVIDIA 即将发布 NVIDIA DGX Spark - 基于 Blackwell 架构的小型 AI 超级计算机,配备 128GB 以上统一内存和 1 PFLOPS 的 AI 性能。这是运行大型语言模型(LLM)的理想设备。
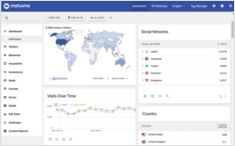
在网站上应使用哪些网络分析系统?
让我们快速了解一下可用于自托管的 Matomo、Plausible、Google 等网络分析提供商和系统 并进行比较。

标准 Ubuntu 24.04 安装流程说明
这是我安装 Ubuntu 24.04 的全新安装 时最喜欢的一套步骤。
我喜欢这里的一点是:不需要安装 NVidia 驱动程序!它们会自动安装。
我曾使用 Dokuwiki 作为个人知识库
Dokuwiki 是一个自托管的维基百科,可以轻松地在本地部署,且不需要任何数据库。
我之前是在我的宠物 Kubernetes 集群上使用 Docker 部署的。

AI适用GPU价格更新 - RTX 5080和RTX 5090
让我们比较顶级消费级GPU的价格,这些GPU特别适合用于大型语言模型(LLMs),总体上也适用于人工智能(AI)。
具体来看: RTX 5080和RTX 5090价格。它们的价格略有下降。

用于 ETS/MLOPS 的 Python 框架,设计精良
Apache Airflow 是一个开源平台,旨在通过 Python 代码以编程方式创建、安排和监控工作流,为传统手动或基于用户界面的工作流工具提供了一个灵活且强大的替代方案。

实现 RAG?这里有一些 Go 代码片段 - 2...
由于标准 Ollama 没有直接的重排序 API,
您需要通过生成查询-文档对的嵌入向量并对其进行评分来实现 使用 Qwen3 重排序器在 GO 中进行重排序。

qwen3 8b、14b 和 30b,devstral 24b,mistral small 24b
在这项测试中,我正在比较不同LLMs在Ollama上如何将Hugo页面从英语翻译成德语。
我测试的三页内容涉及不同主题,其中包含一些结构良好的markdown内容:标题、列表、表格、链接等。

实现 RAG?这里有一些用 Golang 编写的代码片段。
这个小的 Go代码示例重新排序调用Ollama生成嵌入 用于查询和每个候选文档, 然后按余弦相似度降序排序。

价格现实检验 — RTX 5080 和 RTX 5090
仅仅三个月前,我们还看不到RTX 5090在商店里出售,而现在它们已经上市了,但价格略高于MRSP。
让我们比较一下澳大利亚最便宜的RTX 5080和RTX 5090的价格,看看情况如何。

自托管一个网络搜索引擎?简单!
YaCy 是一个 去中心化、点对点(P2P)搜索引擎,其设计目的是无需依赖集中式服务器,使用户能够创建本地或全球索引,并通过查询分布式对等节点来执行搜索。

更多内存,更低功耗,但依然昂贵如...
顶级自动化系统用于某些令人惊叹的工作。

Ollama 现已推出全新强大的 LLM
Qwen3 Embedding 和 Reranker 模型 是 Qwen 系列的最新发布,专为高级文本嵌入、检索和重排序任务而设计。