

使用 Python 中的 PDFMiner 从 PDF 中提取文本
用 Python 掌握 PDF 文本提取
PDFMiner.six 是一个强大的 Python 库,用于从 PDF 文档中提取文本、元数据和布局信息。
用 Python 掌握 PDF 文本提取
PDFMiner.six 是一个强大的 Python 库,用于从 PDF 文档中提取文本、元数据和布局信息。
掌握浏览器自动化进行测试与数据抓取
Playwright 是一个强大且现代的浏览器自动化框架,它彻底改变了网络爬虫和端到端测试的方式。

使用 BAML 和 Instructor 实现类型安全的 LLM 输出
在生产环境中使用大型语言模型时,获取结构化、类型安全的输出至关重要。
两个流行的框架——BAML 和 Instructor——采用不同的方法来解决这个问题。

为可扩展性和清晰度构建你的 Go 项目
构建 Go 项目结构 对于长期的可维护性、团队协作和可扩展性至关重要。与强制使用固定目录布局的框架不同,Go 倡导灵活性——但这种自由也意味着需要选择适合项目特定需求的模式。

Python 依赖注入模式实现清晰可测试的代码
依赖注入 (DI) 是一种基本的设计模式,它在 Python 应用程序中促进干净、可测试和易于维护的代码。

使用 Python 和 Ollama 构建 AI 搜索代理
Ollama 的 Python 库现在包含原生的 OLlama 网络搜索 功能。只需几行代码,你就可以使用网络上的实时信息增强本地 LLM,从而减少幻觉并提高准确性。

从代码注释自动生成 OpenAPI 文档
API 文档对于任何现代应用程序都至关重要,对于 Go APIs Swagger(OpenAPI)已成为行业标准。 对于 Go 开发人员来说,swaggo 提供了一种优雅的解决方案,可以直接从代码注释生成全面的 API 文档。

掌握本地LLM部署,对比12+工具
本地部署大型语言模型 随着开发人员和组织寻求增强的隐私性、减少延迟和对AI基础设施的更大控制权,变得越来越流行。

使用 Go 微服务构建强大的 AI/ML 管道
随着人工智能和机器学习工作负载变得越来越复杂,对强大的编排系统的需求也变得更为迫切。Go语言的简洁性、性能和并发特性使其成为构建机器学习流水线的编排层的理想选择,即使模型本身是用Python编写的。
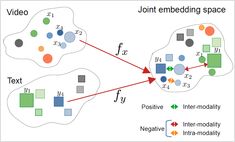
在共享的嵌入空间中统一文本、图像和音频
跨模态嵌入 代表了人工智能领域的一项突破,它使不同数据类型能够在统一的表示空间中实现理解和推理。

在预算硬件上部署企业级AI,使用开放模型
人工智能的民主化已经到来。
借助像 Llama 3、Mixtral 和 Qwen 这样的开源大语言模型(LLM),团队现在可以使用消费级硬件构建强大的 AI 基础设施 - 在降低成本的同时,仍能完全控制数据隐私和部署。

LongRAG、Self-RAG、GraphRAG - 下一代技术
检索增强生成(RAG) 已经远远超越了简单的向量相似性搜索。 LongRAG、Self-RAG 和 GraphRAG 代表了这些能力的前沿。

使用自动文档和类型安全构建超快速的 API
FastAPI 已经成为构建 API 最令人兴奋的 Python Web 框架之一,结合了现代 Python 特性、卓越的性能和开发体验。

使用 Go 强大的生态系统构建生产就绪的 REST API
构建高性能 REST API with Go 已成为 Google、Uber、Dropbox 和无数初创公司驱动系统的一种标准方法。

使用SOLID设计模式构建可维护的Python应用程序
Clean Architecture 通过强调关注点分离和依赖管理,彻底改变了开发人员构建可扩展、可维护应用程序的方式。

使用Saga模式在微服务中处理事务
Saga模式 通过将分布式事务分解为一系列带有补偿操作的本地事务,提供了一种优雅的解决方案。