

FLUX.1-Kontext-dev:图像增强AI模型
用于根据文本指令增强图像的AI模型
Black Forest Labs 已发布 FLUX.1-Kontext-dev,这是一款先进的图像到图像 AI 模型,它可以通过文本指令增强现有图像。
用于根据文本指令增强图像的AI模型
Black Forest Labs 已发布 FLUX.1-Kontext-dev,这是一款先进的图像到图像 AI 模型,它可以通过文本指令增强现有图像。

启用 NVIDIA CUDA 支持的 Docker 模型运行器的 GPU 加速功能
Docker Model Runner 是 Docker 官方用于本地运行 AI 模型的工具,但
在 Docker Model Runner 中启用 NVidia GPU 加速
需要特定的配置。

通过智能令牌优化,将大语言模型成本降低80%
令牌优化是区分成本效益高的LLM应用与耗费预算的实验的关键技能。
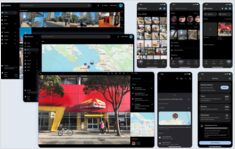
您在自托管人工智能驱动备份中的照片
Immich 是一款革命性的开源、自托管照片和视频管理解决方案,它赋予你对记忆的完全控制权。凭借与 Google Photos 相媲美的功能,包括人工智能驱动的人脸识别、智能搜索和自动手机备份,同时确保你的数据在你自己的服务器上保持私密和安全。

GPT-OSS 120b 在三个 AI 平台上的基准测试
我找到了一些关于GPT-OSS 120b在三个不同平台上运行的性能测试结果:NVIDIA DGX Spark、Mac Studio和RTX 4080。Ollama库中的GPT-OSS 120b模型大小为65GB,这意味着它无法装入RTX 4080(或更新的RTX 5080的16GB显存中。

使用 Python 示例构建 AI 助手的 MCP 服务器
模型上下文协议(MCP)正在革新AI助手与外部数据源和工具的交互方式。在本指南中,我们将探讨如何构建 MCP 服务器(Python),重点介绍网络搜索和爬取功能的示例。
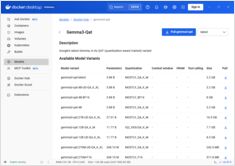
Docker Model Runner 命令快速参考
Docker Model Runner (DMR) 是 Docker 官方用于本地运行 AI 模型的解决方案,于 2025 年 4 月推出。此快速参考提供了所有关键命令、配置和最佳实践的快速查阅。
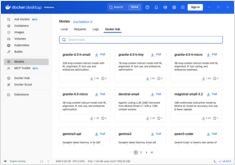
对比 Docker Model Runner 和 Ollama 本地大语言模型
在本地运行大型语言模型 (LLMs) 已成为隐私保护、成本控制和离线功能的重要趋势。 2025 年 4 月,Docker 推出了 Docker Model Runner (DMR),这是其用于 AI 模型部署的官方解决方案,标志着该领域的重大转变。

专用芯片正在让人工智能推理变得更加快速、廉价。

可用性、六个国家的真实零售价格以及与Mac Studio的对比。
NVIDIA DGX Spark 是真实存在的,将于 2025年10月15日 开售,目标用户是需要 本地大型语言模型(LLM)工作 的 CUDA 开发者,配备集成的 NVIDIA AI 套件。美国建议零售价为 3,999美元;由于增值税和渠道因素,英国/德国/日本 的零售价更高。澳大利亚/韩元 的公开标价 尚未广泛发布。

将 Ollama 与 Go 集成:SDK 指南、示例及生产最佳实践。
本指南全面概述了可用于 Ollama 的 Go SDK,并比较了它们的功能集。

比较这两个模型的速度、参数和性能
以下是 Qwen3:30b 和 GPT-OSS:20b 的比较,重点聚焦于指令遵循和性能参数、规格和速度:

不太好看。
Ollama的GPT-OSS模型在处理结构化输出时经常出现问题,尤其是在与LangChain、OpenAI SDK、vllm等框架一起使用时。

从Ollama获取结构化输出的几种方法
大型语言模型(LLMs) 功能强大,但在生产环境中,我们很少希望得到自由形式的段落。 相反,我们希望获得可预测的数据:属性、事实或可以输入到应用程序中的结构化对象。 这就是LLM结构化输出。

我对ollama模型调度的测试 ```
在这里,我比较了新版本 Ollama 为模型分配的 VRAM 量与旧版本 Ollama 的情况。新版本表现更差。

我对Ollama当前开发状态的看法
Ollama 已经迅速成为在本地运行大型语言模型(LLMs)最受欢迎的工具之一。
其简单的命令行界面(CLI)和流畅的模型管理功能,使其成为希望在云之外使用 AI 模型的开发人员的首选。
但与许多有前景的平台一样,已经出现了 Enshittification 的迹象: