

Att skriva effektiva promptar för LLMs
Kräver lite experimenterande men
Även om det finns några vanliga metoder för att skriva bra instruktioner så att LLM inte blir förvirrad när den försöker förstå vad du vill ha av den.
Kräver lite experimenterande men
Även om det finns några vanliga metoder för att skriva bra instruktioner så att LLM inte blir förvirrad när den försöker förstå vad du vill ha av den.

Etikettering och träning kräver lite limning
När jag tränade objektdetektions-AI för några månader sedan - var LabelImg ett mycket användbart verktyg, men exporten från Label Studio till COCO-format accepterades inte av MMDetection-ramverket..

Låt oss testa kvaliteten på logiska felslutdetektering hos olika LLMs
Här jämför jag flera LLM-versioner: Llama3 (Meta), Phi3 (Microsoft), Gemma (Google), Mistral Nemo (Mistral AI) och Qwen (Alibaba).
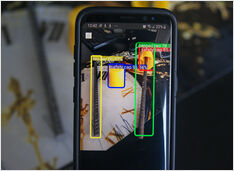
För en tid sedan tränade jag en AI för objektdetektering
På en kall vinterdag i juli… det är i Australien… kände jag ett brådskande behov att träna en AI-modell för att detektera oskyddade betongförstärkande stänger…