
Ollama 上的 Qwen3 嵌入与重排序模型:最先进的性能
Ollama 现已推出全新强大的 LLM
Qwen3 Embedding 和 Reranker 模型 是 Qwen 系列的最新发布,专为高级文本嵌入、检索和重排序任务而设计。
悦目之喜
Qwen3 Embedding 和 Reranker 模型 在多语言自然语言处理(NLP)方面实现了重大进步,为文本嵌入和重排序任务提供了最先进的性能。这些模型是阿里巴巴开发的 Qwen 系列的一部分,旨在支持各种应用,从语义检索到代码搜索。虽然 Ollama 是一个用于托管和部署大型语言模型(LLMs)的流行开源平台,但 Qwen3 模型与 Ollama 的集成在官方文档中并未明确说明。然而,这些模型可以通过 Hugging Face、GitHub 和 ModelScope 获取,从而通过 Ollama 或类似工具实现本地部署。
使用这些模型的示例
请参阅使用 ollama 和这些模型的 Go 语言示例代码:
Ollama 上新 Qwen3 Embedding 和 Reranker 模型概述
这些模型现在可以在 Ollama 上以各种尺寸部署,为广泛的语言和代码相关应用提供最先进的性能和灵活性。
关键功能和能力
-
模型尺寸和灵活性
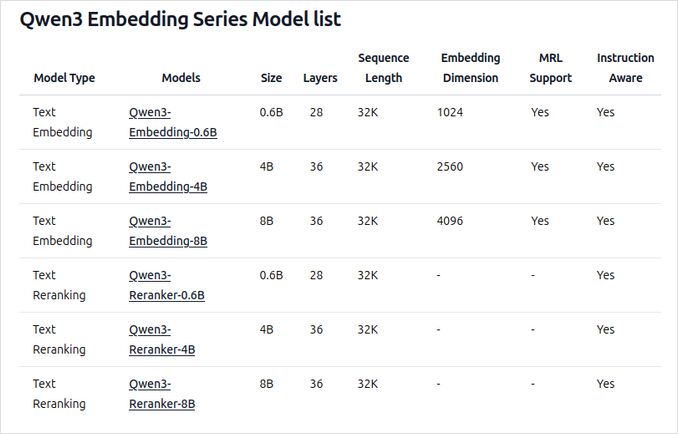
- 提供多种尺寸:0.6B、4B 和 8B 参数,适用于嵌入和重排序任务。
- 8B 嵌入模型目前在 MTEB 多语言排行榜上排名第一(截至 2025 年 6 月 5 日,得分为 70.58)。
- 支持多种量化选项(Q4、Q5、Q8 等),以平衡性能、内存使用和速度。Q5_K_M 推荐给大多数用户,因为它在保持大多数模型性能的同时资源效率高。
-
架构和训练
- 基于 Qwen3 基础构建,利用双编码器(用于嵌入)和交叉编码器(用于重排序)架构。
- 嵌入模型:处理单个文本段,从最终隐藏状态中提取语义表示。
- 重排序模型:采用文本对(如查询和文档)并使用交叉编码器方法输出相关性得分。
- 嵌入模型使用三阶段训练范式:对比预训练、使用高质量数据的监督训练以及模型合并,以实现最佳的泛化和适应性。
- 重排序模型直接使用高质量标记数据进行训练,以提高效率和效果。
-
多语言和多任务支持
- 支持超过 100 种语言,包括编程语言,实现强大的多语言、跨语言和代码检索能力。
- 嵌入模型允许灵活的向量定义和用户自定义指令,以根据特定任务或语言定制性能。
-
性能和使用场景
- 在文本检索、代码检索、分类、聚类和双语矿采方面取得最先进的结果。
- 重排序模型在各种文本检索场景中表现出色,可以与嵌入模型无缝结合,形成端到端的检索流水线。
如何在 Ollama 上使用
你可以使用以下命令在 Ollama 上运行这些模型:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
选择最适合你的硬件和性能需求的量化版本。
总结表
| 模型类型 | 可用尺寸 | 关键优势 | 多语言支持 | 量化选项 |
|---|---|---|---|---|
| 嵌入模型 | 0.6B, 4B, 8B | MTEB 排名第一,灵活,高效,SOTA | 是(100+ 语言) | Q4, Q5, Q6, Q8 等 |
| 重排序模型 | 0.6B, 4B, 8B | 在文本对相关性方面表现出色,高效,灵活 | 是 | F16, Q4, Q5 等 |
好消息!
Ollama 上的 Qwen3 Embedding 和 Reranker 模型在多语言、多任务文本和代码检索能力方面实现了重大飞跃。凭借灵活的部署选项、强大的基准性能以及对广泛语言和任务的支持,它们非常适合研究和生产环境。
模型动物园 - 现在悦目之喜
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
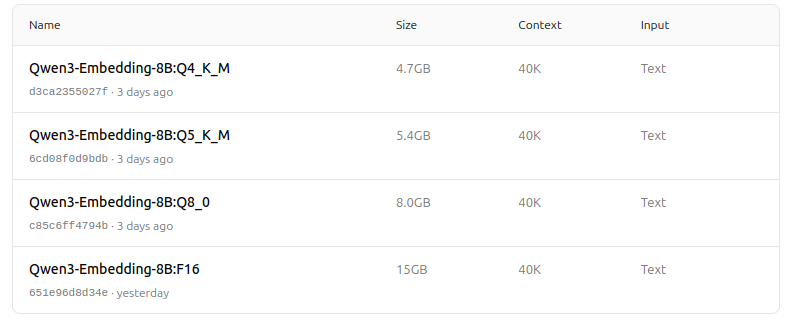
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
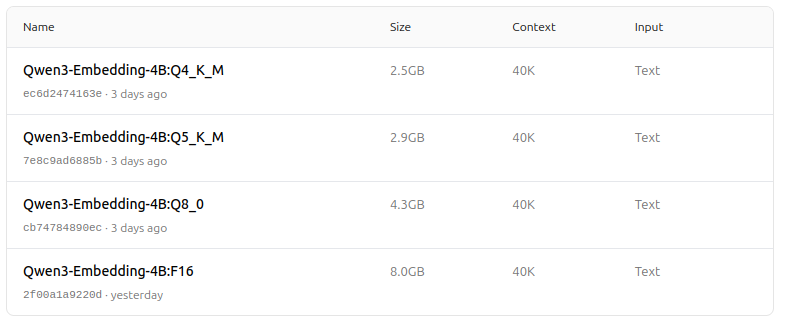
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
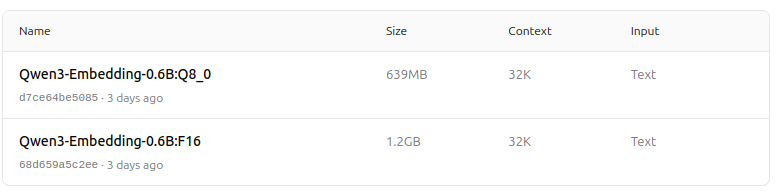
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
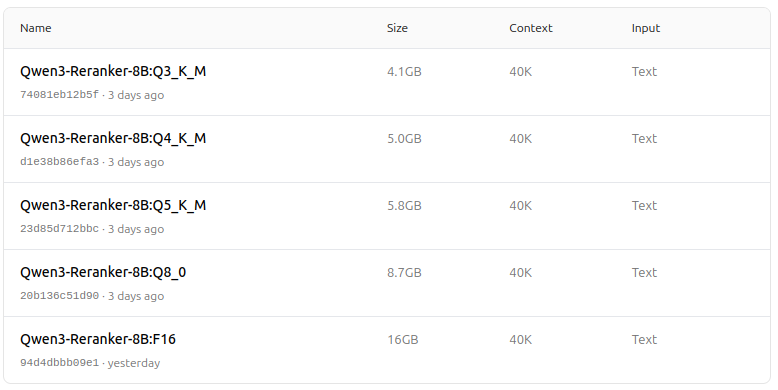
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
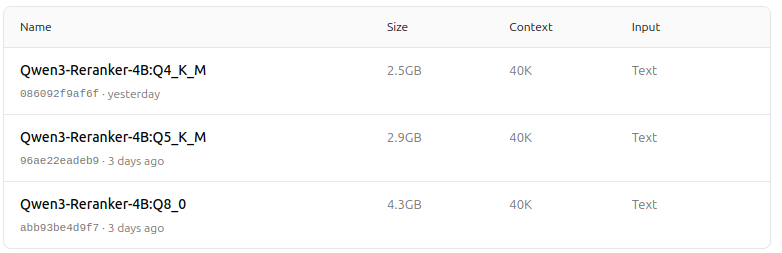
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
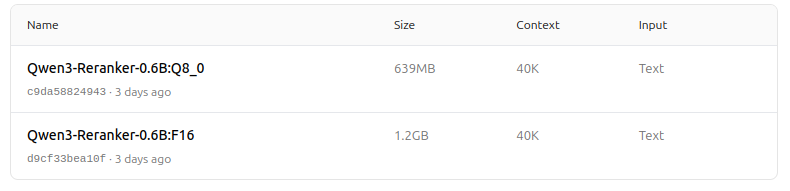
真棒!
