
NVIDIA DGX Spark vs Mac Studio vs RTX-4080: Ollama-prestandajämförelse
GPT-OSS 120b-benchmärkningar på tre AI-plattformar
Jag hittade några intressanta prestandatest av GPT-OSS 120b som kör på Ollama över tre olika plattformar: NVIDIA DGX Spark, Mac Studio, och RTX 4080. GPT-OSS 120b-modellen från Ollama-biblioteket väger 65 GB, vilket innebär att den inte passar in i den 16 GB VRAM som finns på en RTX 4080 (eller den nyare RTX 5080).
Ja, modellen kan köras med delvis avlastning till CPU, och om du har 64 GB systemminne (som jag har), kan du prova det. Dock skulle denna konfiguration inte anses vara nära produktionssäker. För verkligen krävande arbetsbelastningar kan du behöva något som NVIDIA DGX Spark, som är specifikt designad för högkapacitets AI-arbetsbelastningar. För mer om LLM-prestanda – genomflöde mot latens, VRAM-gränser och jämförelser över olika körningar och hårdvara – se LLM-prestanda: Jämförelser, fläckar och optimering.

Jag förväntade mig att denna LLM skulle ha stor nytta av att köras på en “hög-RAM AI-enhet” som DGX Spark. Även om resultaten är goda, är de inte så dramatiskt bättre än vad du kanske förväntar dig givet prisförskottet mellan DGX Spark och billigare alternativ.
TL;DR
Ollama som kör GPT-OSS 120b prestandajämförelse över tre plattformar:
| Enhetsnamn | Promptutvärderingsprestanda (tokens/s) | Genereringsprestanda (tokens/s) | Anteckningar |
|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | Bästa allmänna prestanda, helt GPU-accelererad |
| Mac Studio | Okänd | 34 → 6 | En test visade försämring vid ökad kontextstorlek |
| RTX 4080 | 969 | 12,45 | 78% CPU / 22% GPU delning pga VRAM-gränser |
Modellspecifikationer:
- Modell: GPT-OSS 120b
- Parametrar: 117B (Mixture-of-Experts arkitektur)
- Aktiva parametrar per pass: 5,1B
- Kvantisering: MXFP4
- Modellstorlek: 65 GB
Detta är liknande i arkitektur till andra MoE-modeller som Qwen3:30b, men på en mycket större skala.
GPT-OSS 120b på NVIDIA DGX Spark
LLM-prestandadatat för NVIDIA DGX Spark kommer från den officiella Ollama-bloggposten (länkad nedan i avsnittet “Nyttiga länkar”). DGX Spark representerar NVIDIAs inträde på marknaden för personliga AI-superdatorer, med 128 GB enhetsminne specifikt designat för att köras med stora språkmodeller.

GPT-OSS 120b:s prestanda ser imponerande ut med 41 tokens/s för generering. Detta gör den tydligt till vinnaren för denna modell, vilket visar att den extra minneskapaciteten kan göra en verklig skillnad för extremt stora modeller.
Dock ser prestandan för medel- till stora LLM:s inte lika imponerande ut. Detta är särskilt tydligt med Qwen3:32b och Llama3.1:70b – exakt de modeller där du skulle förvänta dig att den höga RAM-kapaciteten skulle skina. Prestandan på DGX Spark för dessa modeller är inte inspirerande jämfört med prisförskottet. Om du huvudsakligen arbetar med modeller i 30-70B parametrarområdet, kan du vilja överväga alternativ som en välkonfigurerad arbetsstation) eller till och med en Quadro RTX 5880 Ada med dess 48 GB VRAM.
GPT-OSS 120b på Mac Studio Max
Youtubekanalen Slinging Bits har utfört omfattande tester med GPT-OSS 120b som kör på Ollama med olika kontextstorlekar. Resultaten visar en betydande prestandafråga: modellens genereringshastighet sjönk dramatiskt från 34 tokens/s till bara 6 tokens/s när kontextstorleken ökade.
Den här prestandaförsämringen är sannolikt pga minnespress och hur macOS hanterar enhetsminnesarkitekturen. Även om Mac Studio Max har imponerande enhetsminne (upp till 192 GB i M2 Ultra-konfigurationen), så hanterar den mycket stora modeller vid ökande kontextbelastningar på ett särskilt sätt jämfört med dedikerad GPU VRAM.


För tillämpningar som kräver konsekvent prestanda över olika kontextlängder gör detta Mac Studio mindre idealt för GPT-OSS 120b, trots dess annars utmärkta förmåga för AI-belastningar. Du kan få bättre lycka med mindre modeller eller överväga att använda Ollama:s parallella förfråganshantering funktioner för att maximera genomflöde i produktionsscenarier.
GPT-OSS 120b på RTX 4080
Jag tänkte först att körande Ollama med GPT-OSS 120b på min konsumentdator inte skulle vara särskilt spännande, men resultaten förvånade mig positivt. Här är vad som hände när jag testade det med denna fråga:
$ ollama run gpt-oss:120b --verbose Jämför väder i statshuvudstäder i Australien
Tänkande...
Vi behöver jämföra väder i statshuvudstäder i Australien. Ge en jämförelse, kanske inkludera
...
*Alla data tillgängliga september 2024; eventuella uppdateringar från BOM efter den datum kan lätt justera
siffrorna, men de breda mönster förblir oförändrade.*
total duration: 4m39.942105769s
load duration: 75.843974ms
prompt eval count: 75 token(s)
prompt eval duration: 77.341981ms
prompt eval rate: 969.72 tokens/s
eval count: 3483 token(s)
eval duration: 4m39.788119563s
eval rate: 12.45 tokens/s
Här är det intressanta – Ollama med denna LLM körde främst på CPU! Modellen passar helt enkelt inte in i den 16 GB VRAM, så Ollama avlastade intelligently mest av den till systemminnet. Du kan se detta beteende med hjälp av kommandot ollama ps:
$ ollama ps
NAME ID SIZE PROCESSOR CONTEXT
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
Trots att den kördes med en 78% CPU / 22% GPU-delning, levererar RTX 4080 ändå ansenlig prestanda för en modell av denna storlek. Promptutvärderingen är extremt snabb på 969 tokens/s, och även genereringshastigheten på 12,45 tokens/s är användbar för många tillämpningar.
Detta är särskilt imponerande när man tänker på att:
- Modellen är nästan 4 gånger större än den tillgängliga VRAM
- De flesta beräkningarna sker på CPU (vilket gynnas av mina 64 GB systemminne)
- Förståelsen av hur Ollama använder CPU-kärnor kan hjälpa till att optimera denna konfiguration ytterligare
Vem skulle ha trott att en konsument GPU kunde hantera en modell med 117B parametrar överhuvudtaget, låt bli med användbar prestanda? Detta visar kraften i Ollamas intelligenta minhantering och vikten av att ha tillräckligt mycket systemminne. Om du är intresserad av att integrera Ollama i dina tillämpningar, se denna guide om att använda Ollama med Python.
Notera: Även om detta fungerar för experiment och testning, kommer du att märka att GPT-OSS kan ha vissa egenskaper, särskilt med strukturerade utdataformat.
För att utforska fler jämförelser, VRAM- och CPU-avlastningstransaktioner, och prestandatuning över olika plattformar, se vår LLM-prestanda: Jämförelser, fläckar och optimering hub.
Primära källor
- Ollama på NVIDIA DGX Spark: Prestandajämförelser - Officiell Ollama-bloggpost med omfattande DGX Spark-prestandadata
- GPT-OSS 120B på Mac Studio - Slinging Bits YouTube - Detaljerad video som testar GPT-OSS 120b med olika kontextstorlekar
Relaterad läsning om hårdvarajämförelser och Ollama
- DGX Spark vs. Mac Studio: En praktisk, prisbaserad titt på NVIDIAs personliga AI-superdator - Detaljerad förklaring av DGX Spark-konfigurationer, globala priser och direkt jämförelse med Mac Studio för lokal AI-arbete
- NVIDIA DGX Spark - Förväntan - Tidig tävling om DGX Spark: tillgänglighet, priser och tekniska specifikationer
- NVidia RTX 5080 och RTX 5090-priser i Australien - oktober 2025 - Nuvarande marknadspriser för nästa generations konsument-GPU:er
- Är Quadro RTX 5880 Ada 48GB något bra? - Recension av 48 GB arbetsstation-GPU-alternativ för AI-belastningar
- Ollama cheat sheet - Komplett kommandoreferens och tips för Ollama
P.S. Ny data
Redan efter att jag hade publicerat denna post hittade jag på NVIDIAs webbplats några fler statistik om LLM-inferens på DGX Spark:
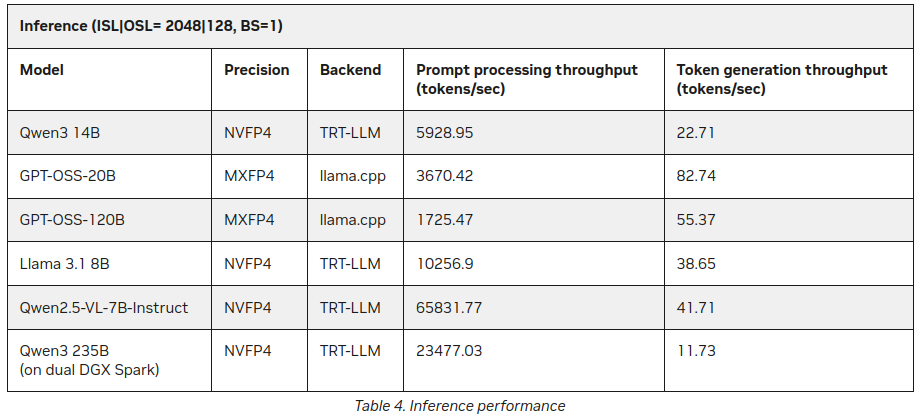
Bättre, men inte mycket kontrasterande till det som sagts ovan (55 tokens vs 41), men det är ett intressant tillägg, särskilt om Qwen3 235B (på dubbel DGX Spark) producerar 11+ tokens per sekund
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
