
Qwen3 Embedding & Reranker Modeller på Ollama: State-of-the-Art Prestanda
Nya fantastiska LLMs tillgängliga i Ollama
Modellerna för Qwen3 Embedding och Reranker (https://www.glukhov.org/sv/post/2025/06/qwen3-embedding-qwen3-reranker-on-ollama/ “Qwen3 Embedding och Reranker modeller på ollama”) är de senaste lanseringarna i Qwen-familjen, specifikt utformade för avancerade textembedding-, återvinning- och omrankningstjänster.
Glädje för ögat
Qwen3 Embedding och Reranker modeller representerar en betydande framsteg inom flerspråkig naturlig språkbehandling (NLP), med toppmodern prestanda inom textembedding och omrankningstjänster. Dessa modeller, som är en del av Qwen-serien utvecklad av Alibaba, är utformade för att stödja ett brett spektrum av applikationer, från semantisk återvinning till kodsökning. Medan Ollama är en populär öppen källkodplattform för att värd och distribuera stora språkmodeller (LLMs), är integreringen av Qwen3-modeller med Ollama inte explicit detaljerad i den officiella dokumentationen. Modellerna är dock tillgängliga via Hugging Face, GitHub och ModelScope, vilket möjliggör potentiell lokal distribution genom Ollama eller liknande verktyg.
Exempel med dessa modeller
Se exempelkod på Go som använder ollama med dessa modeller:
- Omrankning av textdokument med Ollama och Qwen3 Embedding-modell - i Go
- Omrankning av textdokument med Ollama och Qwen3 Reranker-modell - i Go
Översikt över nya Qwen3 Embedding och Reranker modeller på Ollama
Dessa modeller är nu tillgängliga för distribution på Ollama i olika storlekar, vilket ger toppmodern prestanda och flexibilitet för ett brett spektrum av språk- och kodrelaterade applikationer.
Nyckelfunktioner och kapaciteter
-
Modellstorlekar och flexibilitet
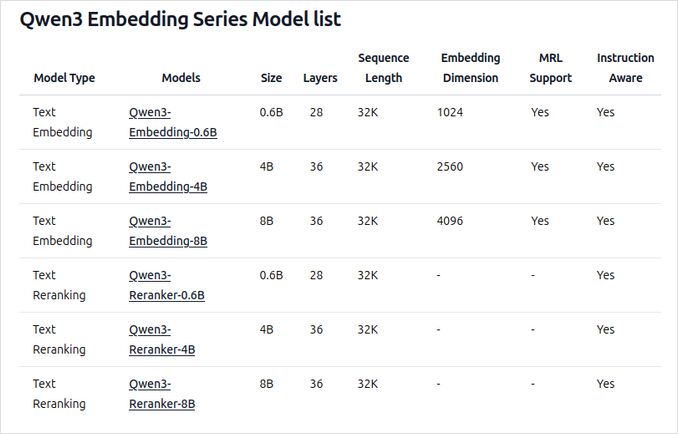
- Tillgängliga i flera storlekar: 0,6B, 4B och 8B parametrar för både embedding- och omrankningstjänster.
- 8B embedding-modellen rankas för närvarande som nr 1 på MTEB flerspråkiga toppnoteringen (per den 5 juni 2025, med en poäng på 70,58).
- Stöder ett brett utbud av kvantiseringsalternativ (Q4, Q5, Q8, etc.) för att balansera prestanda, minnesanvändning och hastighet. Q5_K_M rekommenderas för de flesta användare eftersom det bevarar mestadels av modellens prestanda samtidigt som det är resurseffektivt.
-
Arkitektur och träning
- Byggt på Qwen3-foundation, som utnyttjar både dual-encoder (för embedding) och cross-encoder (för omrankning) arkitekturer.
- Embedding-modell: Bearbetar enskilda textsegment, extraherar semantiska representationer från den slutliga dolda tillståndet.
- Reranker-modell: Tar emot textpar (t.ex. fråga och dokument) och ger en relevanspoäng med hjälp av en cross-encoder-metod.
- Embedding-modellerna använder en tre-stegs träningsparadigm: kontrastiv förträning, övervakad träning med högkvalitativ data och modellfusion för optimal generalisering och anpassningsförmåga.
- Reranker-modellerna tränas direkt med högkvalitativ märkt data för effektivitet och effektivitet.
-
Flerspråkig och fleruppgiftsstöd
- Stöder över 100 språk, inklusive programspråk, vilket möjliggör robust flerspråkig, korsspråkig och kodåtervinning.
- Embedding-modellerna tillåter flexibla vektordefinitioner och användardefinierade instruktioner för att anpassa prestanda till specifika uppgifter eller språk.
-
Prestanda och användningsområden
- Toppmoderna resultat inom textåtervinning, kodåtervinning, klassificering, klustring och bitextmining.
- Reranker-modellerna utmärker sig i olika textåtervinningsscenarier och kan smidigt kombineras med embedding-modeller för slutna återvinningstekniker.
Hur man använder på Ollama
Du kan köra dessa modeller på Ollama med kommandon som:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Välj den kvantiseringsversion som bäst passar din hårdvara och prestandabehov.
Sammanfattande tabell
| Modelltyp | Tillgängliga storlekar | Nyckelstyrkor | Flerspråkigt stöd | Kvantiseringsalternativ |
|---|---|---|---|---|
| Embedding | 0,6B, 4B, 8B | Topp MTEB-poäng, flexibel, effektiv, SOTA | Ja (100+ språk) | Q4, Q5, Q6, Q8, etc. |
| Reranker | 0,6B, 4B, 8B | Utmärker sig i textparrelevans, effektiv, flexibel | Ja | F16, Q4, Q5, etc. |
Helt underbart nyheter!
Qwen3 Embedding och Reranker modeller på Ollama representerar ett betydande steg framåt inom flerspråkig, fleruppgifts text- och kodåtervinning. Med flexibla distributionsalternativ, starka bänkmätningar och stöd för ett brett utbud av språk och uppgifter är de väl lämpade för både forskning och produktionsmiljöer.
Modellzoo - glädje för ögat nu
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
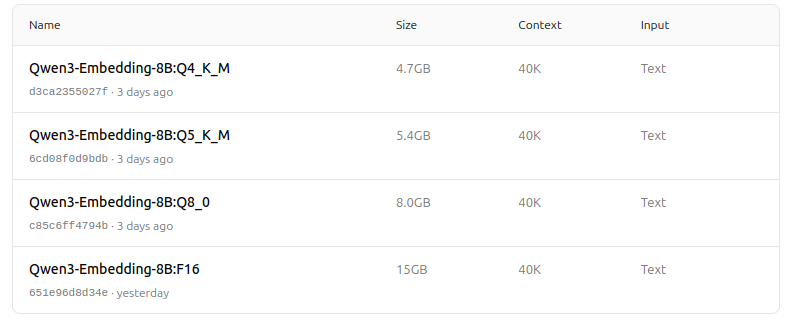
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
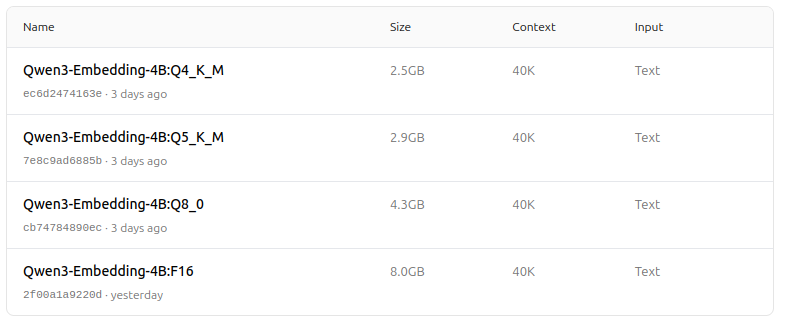
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
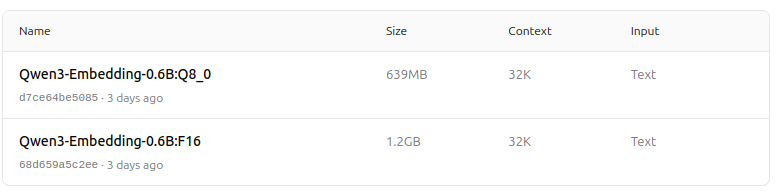
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
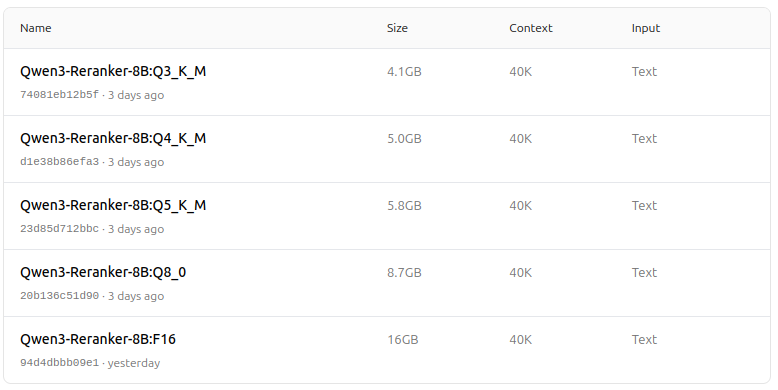
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
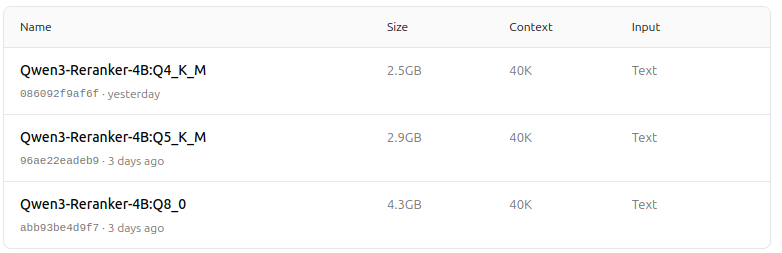
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
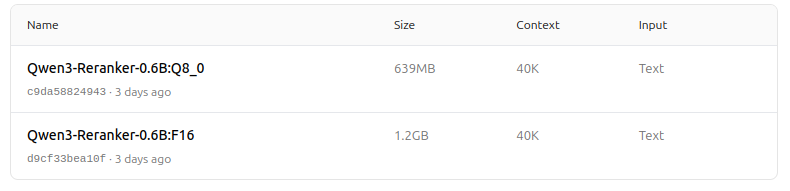
Bra!
Användbara länkar
- Omrankning av textdokument med Ollama och Qwen3 Embedding-modell - i Go
- Omrankning av textdokument med Ollama och Qwen3 Reranker-modell - i Go
- Ollama cheatsheet
- Flytta Ollama modeller till annan enhet eller mapp
- Self-hosting Perplexica - med Ollama
- Test: Hur Ollama använder Intel CPU-prestanda och effektiva kärnor
- LLM-hastighetsprestanda jämförelse
- Jämförelse av LLM-sammanfattningsförmåga
- Molnbaserade LLM-leverantörer
- Hur Ollama hanterar parallella förfrågningar
- Jämförelse av Hugo-sidöversättningskvalitet - LLMs på Ollama
