

Self-Hosting Cognee: Uji Kinerja LLM
Menguji Cognee dengan LLM lokal - hasil nyata
Cognee adalah kerangka kerja Python untuk membangun grafik pengetahuan dari dokumen menggunakan LLM. Tapi apakah itu bekerja dengan model yang dihosting sendiri?
Menguji Cognee dengan LLM lokal - hasil nyata
Cognee adalah kerangka kerja Python untuk membangun grafik pengetahuan dari dokumen menggunakan LLM. Tapi apakah itu bekerja dengan model yang dihosting sendiri?

Bagaimana Saya Memperbaiki Masalah Jaringan di Ubuntu
Setelah secara otomatis menginstal kernel baru, Ubuntu 24.04 kehilangan koneksi jaringan ethernet. Masalah yang mengganggu ini terjadi untuk kedua kalinya pada saya, jadi saya mencatat solusinya di sini untuk membantu orang lain yang menghadapi masalah yang sama.

Pos singkat, hanya mencatat harga
Dengan volatilitas harga RAM yang gila ini, untuk membentuk dan memiliki gambaran yang lebih baik, mari kita lacak harga RAM di Australia terlebih dahulu.

Harga RAM melonjak 163-619% karena permintaan AI mengganggu pasokan
Pasaran memori sedang mengalami volatilitas harga yang belum pernah terjadi sebelumnya di akhir 2025, dengan harga RAM melonjak secara dramatis di segala segmen.

Harga GPU Konsumen yang Cocok untuk AI - RTX 5080 dan RTX 5090
Mari kita bandingkan harga untuk GPU konsumen tingkat atas, yang cocok khususnya untuk LLM dan secara umum untuk AI.
Secara khusus saya melihat RTX-5080 dan RTX-5090 harga.

Buatkan AI perusahaan di perangkat keras berbasis anggaran dengan model terbuka
Demokratisasi AI sudah tiba. Dengan LLM open-source seperti Llama 3, Mixtral, dan Qwen kini bersaing dengan model proprietary, tim dapat membangun infrastruktur AI yang kuat menggunakan perangkat keras konsumen - mengurangi biaya sambil mempertahankan kontrol penuh atas privasi data dan penggunaan.

Aktifkan percepatan GPU untuk Docker Model Runner dengan dukungan NVIDIA CUDA
Docker Model Runner adalah alat resmi Docker untuk menjalankan model AI secara lokal, tetapi mengaktifkan percepatan GPU NVidia di Docker Model Runner memerlukan konfigurasi khusus.

Benchmark GPT-OSS 120b pada tiga platform AI
Saya menemukan beberapa uji kinerja menarik dari GPT-OSS 120b yang berjalan di Ollama di tiga platform berbeda: NVIDIA DGX Spark, Mac Studio, dan RTX 4080. Model GPT-OSS 120b dari perpustakaan Ollama memiliki ukuran 65GB, yang berarti tidak masuk ke dalam 16GB VRAM dari RTX 4080 (atau yang lebih baru RTX 5080).
Referensi cepat untuk perintah Docker Model Runner
Docker Model Runner (DMR) adalah solusi resmi Docker untuk menjalankan model AI secara lokal, diperkenalkan pada April 2025. Cheat sheet ini memberikan referensi cepat untuk semua perintah penting, konfigurasi, dan praktik terbaik.
Manajemen VM sederhana untuk Linux dengan GNOME Boxes
Dalam pemandangan komputasi saat ini, virtualisasi telah menjadi hal yang esensial untuk pengembangan, pengujian, dan menjalankan beberapa sistem operasi. Bagi pengguna Linux yang mencari cara sederhana dan intuitif untuk mengelola mesin virtual, GNOME Boxes menonjol sebagai pilihan ringan dan ramah pengguna yang memprioritaskan kemudahan penggunaan tanpa mengorbankan fungsi.

Chip khusus sedang membuat inferensi AI lebih cepat dan murah.
Masa depan AI bukan hanya tentang model yang lebih cerdas models — tetapi tentang silikon yang lebih cerdas.
Perangkat keras khusus untuk inference LLM sedang mendorong revolusi yang mirip dengan perpindahan penambangan Bitcoin ke ASICs.

Ketersediaan, harga ritel dunia nyata di enam negara, dan perbandingan dengan Mac Studio.
NVIDIA DGX Spark adalah nyata, tersedia untuk dibeli 15 Oktober 2025, dan ditujukan untuk pengembang CUDA yang membutuhkan pekerjaan LLM lokal dengan tumpukan AI NVIDIA yang terintegrasi. Harga MSRP AS $3.999; harga ritel UK/DE/JP lebih tinggi karena pajak dan saluran. Harga publik AUD/KRW belum secara luas diposting.

Harga GPU Konsumen yang Cocok untuk AI - RTX 5080 dan RTX 5090
Kembali lagi, mari kita bandingkan harga untuk GPU konsumen tingkat atas yang cocok untuk LLM khususnya dan AI secara umum. Secara spesifik, saya sedang melihat harga RTX-5080 dan RTX-5090. Harganya sedikit turun.
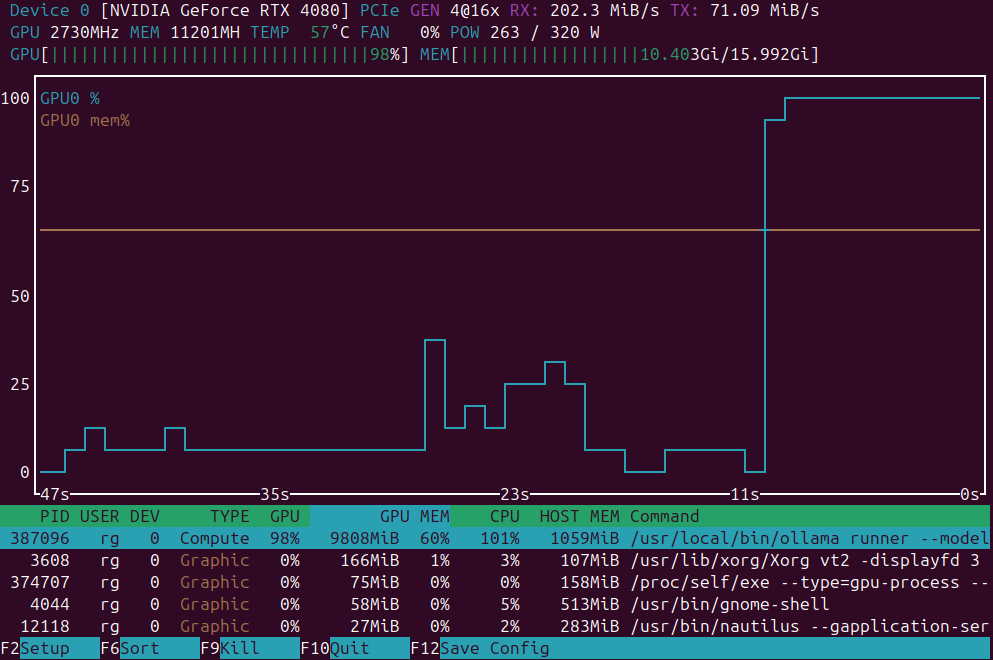
Daftar singkat aplikasi untuk pemantauan beban GPU
Aplikasi pemantauan beban GPU: nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

Pada Juli 2025, segera akan tersedia
Nvidia segera merilis NVIDIA DGX Spark - superkomputer kecil AI berbasis arsitektur Blackwell dengan 128+GB RAM terpadu dan kinerja AI sebesar 1 PFLOPS. Perangkat yang menarik untuk menjalankan LLM.

Pembaruan harga GPU yang cocok untuk AI - RTX 5080 dan RTX 5090
Mari kita bandingkan harga untuk GPU konsumen tingkat atas yang cocok untuk LLM khususnya dan AI secara umum. Secara khusus, lihat harga RTX 5080 dan RTX 5090. Mereka sedikit turun.