

Mengurangi Biaya LLM: Strategi Optimisasi Token
Potong biaya LLM sebesar 80% dengan optimisasi token yang cerdas
Optimasi token adalah keterampilan kritis yang membedakan aplikasi LLM yang hemat biaya dari eksperimen yang menghabiskan anggaran.
Potong biaya LLM sebesar 80% dengan optimisasi token yang cerdas
Optimasi token adalah keterampilan kritis yang membedakan aplikasi LLM yang hemat biaya dari eksperimen yang menghabiskan anggaran.

Bangun server MCP untuk asisten AI dengan contoh Python
Model Context Protocol (MCP) sedang merevolusi cara asisten AI berinteraksi dengan sumber data eksternal dan alat. Dalam panduan ini, kita akan menjelaskan bagaimana membangun server MCP dalam Python, dengan contoh yang berfokus pada kemampuan pencarian web dan pengambilan data.

Ketersediaan, harga ritel dunia nyata di enam negara, dan perbandingan dengan Mac Studio.
NVIDIA DGX Spark adalah nyata, tersedia untuk dibeli 15 Oktober 2025, dan ditujukan untuk pengembang CUDA yang membutuhkan pekerjaan LLM lokal dengan tumpukan AI NVIDIA yang terintegrasi. Harga MSRP AS $3.999; harga ritel UK/DE/JP lebih tinggi karena pajak dan saluran. Harga publik AUD/KRW belum secara luas diposting.

Integrasi Ollama dengan Go: Panduan SDK, contoh, dan praktik terbaik untuk produksi.
Panduan ini memberikan gambaran menyeluruh tentang SDK Go untuk Ollama yang tersedia dan membandingkan set fitur mereka.

Membandingkan kecepatan, parameter, dan kinerja dari dua model ini
Berikut adalah perbandingan antara Qwen3:30b dan GPT-OSS:20b dengan fokus pada pemenuhan instruksi dan parameter kinerja, spesifikasi, serta kecepatan:

+ Contoh Spesifik Menggunakan LLM Berpikir
Dalam posting ini, kita akan menjelajahi dua cara untuk menghubungkan aplikasi Python Anda ke Ollama: 1. Melalui HTTP REST API; 2. Melalui perpustakaan Ollama Python resmi.

Tidak terlalu menarik.
Model GPT-OSS Ollama memiliki masalah berulang dalam menangani output terstruktur, terutama ketika digunakan dengan kerangka kerja seperti LangChain, OpenAI SDK, vllm, dan lainnya.

API yang sedikit berbeda memerlukan pendekatan khusus.
Berikut adalah perbandingan dukungan sampingan untuk output terstruktur (mendapatkan JSON yang andal) di berbagai penyedia LLM populer, beserta contoh Python minimal

Beberapa cara untuk mendapatkan output terstruktur dari Ollama
Model Bahasa Besar (LLMs) sangat kuat, tetapi dalam produksi kita jarang ingin paragraf bebas. Sebaliknya, kita ingin data yang dapat diprediksi: atribut, fakta, atau objek terstruktur yang dapat Anda masukkan ke dalam aplikasi. Itu adalah Keluaran Terstruktur LLM.
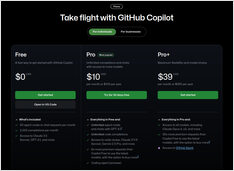
Deskripsi, daftar perintah rencana dan pintasan keyboard
Berikut adalah panduan terkini lembar pintas GitHub Copilot, yang mencakup pintasan penting, perintah, tips penggunaan, dan fitur konteks untuk Visual Studio Code dan Copilot Chat

Longread tentang spesifikasi dan implementasi MCP dalam GO
Di sini kita memiliki deskripsi tentang Model Context Protocol (MCP), catatan singkat tentang cara mengimplementasikan server MCP dalam Go, termasuk struktur pesan dan spesifikasi protokol.

Menerapkan RAG? Berikut beberapa potongan kode Go - 2...
Karena Ollama standar tidak memiliki API rerank langsung, Anda perlu menerapkan reranking menggunakan Qwen3 Reranker dalam GO dengan menghasilkan embedding untuk pasangan query-dokumen dan memberi skor mereka.

Menerapkan RAG? Berikut adalah beberapa contoh kode dalam Golang...
Ini sedikit Contoh kode Go untuk reranking memanggil Ollama untuk menghasilkan embedding untuk query dan setiap dokumen kandidat, kemudian mengurutkan menurun berdasarkan kesamaan kosinus.

LLM untuk mengekstrak teks dari HTML...
Dalam perpustakaan model Ollama terdapat model yang mampu mengubah konten HTML menjadi Markdown, yang berguna untuk tugas konversi konten.

Apa ini tren pemrograman yang dibantu AI?
Vibe coding adalah pendekatan pemrograman yang didorong oleh AI, di mana pengembang menggambarkan fungsi yang diinginkan dalam bahasa alami, memungkinkan alat AI untuk menghasilkan kode secara otomatis.