फ्लक्स.1-कोण्टेक्स्ट-डेव: इमेज ऑगमेंटेशन AI मॉडल
इमेजों को टेक्स्ट निर्देशों के साथ बढ़ाने के लिए AI मॉडल
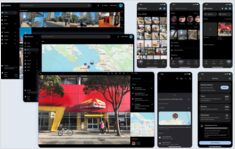
ब्लैक फॉरेस्ट लैब्स ने FLUX.1-Kontext-dev जारी किया है, एक उन्नत इमेज-टू-इमेज एआई मॉडल जो टेक्स्ट निर्देशों का उपयोग करके मौजूदा इमेजों को बढ़ाता है।